Requisito previo : teoría de conjuntos aproximados
El objetivo principal del análisis de conjuntos aproximados es la inducción de aproximaciones de conceptos. Los conjuntos aproximados constituyen una base sólida para el descubrimiento de conocimiento en la base de datos. Ofrece herramientas matemáticas para descubrir patrones ocultos en los datos. Se puede utilizar para la selección de características, la extracción de características, la reducción de datos, la generación de reglas de decisión y la extracción de patrones (plantillas, reglas de asociación), etc. Identifica dependencias parciales o totales en los datos, elimina datos redundantes, da un enfoque a valores nulos, datos faltantes , datos dinámicos y otros.
Cuatro clases básicas de conjuntos aproximados:
Hay cuatro clases básicas de teoría de conjuntos aproximados:
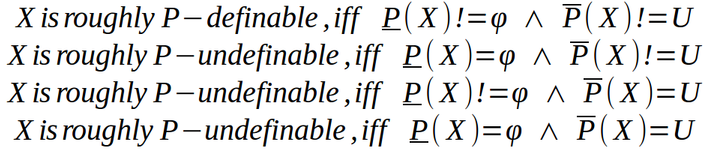
Precisión:
la precisión del conjunto aproximado de un conjunto X que mide qué tan cerca se aproxima el conjunto aproximado al conjunto objetivo X se da como:
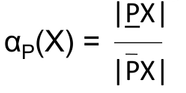
donde |X| denota la cardinalidad del conjunto X que no es nulo. Obviamente, α p (X) estará entre [0, 1] –
- si α p (X)= 1, las aproximaciones superior e inferior son iguales y X se convierte en un conjunto nítido con respecto a P.
- si α p (X)< 1, X es rugosa con respecto a P.
- si α p (X)= 0, la aproximación inferior está vacía (independientemente del tamaño de la aproximación superior).
Dependencia de atributos:
uno de los aspectos más importantes del análisis de bases de datos es el descubrimiento de dependencias de atributos. Describe qué variables están fuertemente relacionadas con qué otras variables. El conjunto de atributos Q depende totalmente de un conjunto de atributos P, denotado si todos los valores de los atributos de Q están determinados únicamente por los valores de los atributos de P. En la teoría de conjuntos aproximados, la noción de dependencia se define de manera muy simple.
Tomemos dos conjuntos disjuntos de atributos, el conjunto P y el conjunto Q. Cada conjunto de atributos induce una estructura de clases de indiscernibilidad o equivalencia. Las clases de equivalencia inducidas por P están dadas por [x] P y las clases de equivalencia inducidas por Q están dadas por [x] Q . Sea Q i una clase de equivalencia dada de la estructura de clases de equivalencia inducida por el conjunto de atributos Q. La dependencia del conjunto de atributos Q en el conjunto de atributos P, k o γ(P, Q) viene dada por:
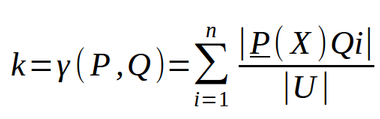
Tenga en cuenta que –
- Si k o γ(P, Q)= 1, Q depende totalmente de P.
- Si k o γ(P, Q)< 1, Q depende parcialmente (en un grado k) de P.
Reducir:
Los objetos iguales o indiscernibles se pueden representar varias veces. Algunos de los atributos pueden ser superfluos o redundantes. Deberíamos mantener sólo aquellos atributos que preservan la relación de indiscernibilidad y, en consecuencia, establecen la aproximación. Por lo general, hay varios subconjuntos de atributos de este tipo y los que son mínimos se denominan Reduct . Entonces, un Reduct es un conjunto suficiente de características que por sí mismo puede caracterizar completamente el conocimiento en la base de datos. Algunas de las características importantes de Reduct son:
- Produce la misma estructura de clase de equivalencia que la expresada por el conjunto completo de atributos que puede expresarse mediante [x] RED = [x] P .
- es mínimo
- No es único.
Algoritmo para Reducir Cálculo –
Input:
C, the set of all conditional features
D, the set of all decisional features
Output: R, a feature subset
1. T := { }, R : = { }
2. repeat
3. T : = R
4. ∀ x ∈ (C – R )
5. if γ RU{X} ( D ) > γT( D )
6. T : = R U {x}
7. R : = T
8. until γR( D ) = γC( D )
9. return R
Núcleo:
Núcleo es el conjunto de atributos que es común a todos los reductos y se denota por CORE(P) = ∩ (RED(P)) . Algunas de las características importantes de Core son:
- Consiste en atributos que no se pueden eliminar sin provocar el colapso de la estructura de clases de equivalencia.
- Puede estar vacío.
- Es el conjunto de atributos necesarios. Si eliminamos los atributos principales de la tabla de información, se producirán incoherencias en los datos.
Un ejemplo de Reducts & Core –
Tabla de información: en el conjunto aproximado, la información del modelo de datos se almacena en una tabla. Cada fila representa un hecho o un objeto. En la terminología de conjunto aproximado, una tabla de datos se denomina sistema de información. Por lo tanto, la tabla de información representa datos de entrada, recopilados de cualquier dominio. Tomemos una tabla de información como:
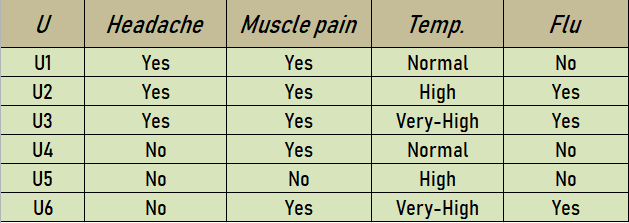
Reducir Cálculo:
El conjunto {Dolor muscular, Temp.} es una reducción del conjunto original de atributos {Dolor de cabeza, Dolor_muscular, Temp.}. Entonces, Reduct1 = {Muscle-dolor, Temp.} . Una nueva tabla de información basada en este Reduct1 se representa como:
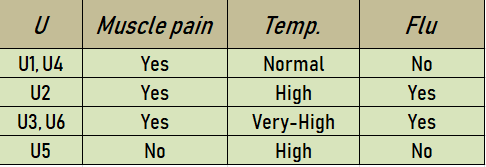
El conjunto {Dolor de cabeza, Temp.} es una reducción del conjunto original de atributos {Dolor de cabeza, Dolor_muscular, Temp.}. Entonces, Reduct2 = {Headache, Temp.} . Una nueva tabla de información basada en este Reduct2 se representa como:
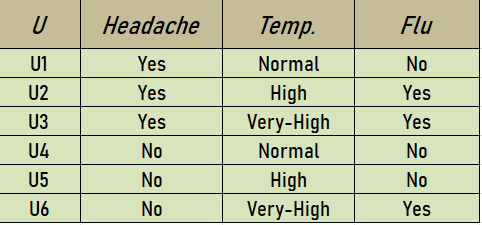
Entonces el núcleo será la intersección de todos los reductos. BÁSICO = {Dolor de cabeza, Temp}∩ {Dolor muscular, Temp} = {Temp}
Referencias:
http://zsi.tech.us.edu.pl/~nowak/bien/w2.pdf
https://www.sciencedirect.com/science/article/pii/S2468232216300786
https://www.mimuw.edu .pl/~son/datamining/RSDM/Intro.pdf