En este artículo, vamos a ver cómo unir dos marcos de datos en Pyspark usando Python. Join se usa para combinar dos o más marcos de datos basados en columnas en el marco de datos.
Sintaxis : dataframe1.join(dataframe2,dataframe1.column_name == dataframe2.column_name,”tipo”)
dónde,
- dataframe1 es el primer marco de datos
- dataframe2 es el segundo marco de datos
- column_name es la columna que coincide en ambos marcos de datos
- type es el tipo de unión que tenemos que unir
Cree el primer marco de datos para la demostración:
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
dataframe.show()
Producción:

Cree un segundo marco de datos para la demostración:
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
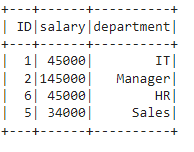
# list of employee data
data1 = [["1", "45000", "IT"],
["2", "145000", "Manager"],
["6", "45000", "HR"],
["5", "34000", "Sales"]]
# specify column names
columns = ['ID', 'salary', 'department']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data1, columns)
dataframe1.show()
Producción:
Unir internamente
Esto unirá los dos marcos de datos de PySpark en columnas clave, que son comunes en ambos marcos de datos.
Sintaxis : dataframe1.join(dataframe2,dataframe1.column_name == dataframe2.column_name,”inner”)
Ejemplo:
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# list of employee data
data1 = [["1", "45000", "IT"],
["2", "145000", "Manager"],
["6", "45000", "HR"],
["5", "34000", "Sales"]]
# specify column names
columns = ['ID', 'salary', 'department']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data1, columns)
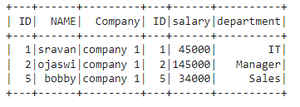
# inner join on two dataframes
dataframe.join(dataframe1,
dataframe.ID == dataframe1.ID,
"inner").show()
Producción:
Unión exterior completa
Esta unión une los dos marcos de datos con todas las filas coincidentes y no coincidentes, podemos realizar esta unión de tres maneras
Sintaxis :
- exterior : dataframe1.join(dataframe2,dataframe1.column_name == dataframe2.column_name,”outer”)
- full : dataframe1.join(dataframe2,dataframe1.column_name == dataframe2.column_name,”full”)
- fullouter : dataframe1.join(dataframe2,dataframe1.column_name == dataframe2.column_name,”fullouter”)
Ejemplo 1: usar una palabra clave externa
En este ejemplo, vamos a realizar una combinación externa en función de la columna ID en ambos marcos de datos.
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# list of employee data
data1 = [["1", "45000", "IT"],
["2", "145000", "Manager"],
["6", "45000", "HR"],
["5", "34000", "Sales"]]
# specify column names
columns = ['ID', 'salary', 'department']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data1, columns)
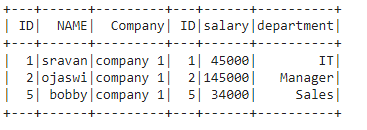
# full outer join on two dataframes
dataframe.join(dataframe1,
dataframe.ID == dataframe1.ID,
"outer").show()
Producción:

Ejemplo 2: Uso de palabra clave completa
En este ejemplo, vamos a realizar una unión externa utilizando una palabra clave completa basada en la columna de ID en ambos marcos de datos.
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# list of employee data
data1 = [["1", "45000", "IT"],
["2", "145000", "Manager"],
["6", "45000", "HR"],
["5", "34000", "Sales"]]
# specify column names
columns = ['ID', 'salary', 'department']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data1, columns)
# full outer join on two dataframes
dataframe.join(dataframe1,
dataframe.ID == dataframe1.ID,
"full").show()
Producción:

Ejemplo 3: Usar la palabra clave fullouter
En este ejemplo, vamos a realizar una unión externa utilizando una columna de identificación externa completa en ambos marcos de datos.
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# list of employee data
data1 = [["1", "45000", "IT"],
["2", "145000", "Manager"],
["6", "45000", "HR"],
["5", "34000", "Sales"]]
# specify column names
columns = ['ID', 'salary', 'department']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data1, columns)
# full outer join on two dataframes
dataframe.join(dataframe1,
dataframe.ID == dataframe1.ID,
"fullouter").show()
Producción:
Unirse a la izquierda
Aquí, esta unión se une al marco de datos al devolver todas las filas del primer marco de datos y solo las filas coincidentes del segundo marco de datos con respecto al primer marco de datos. Podemos realizar este tipo de unión usando left y leftouter.
Sintaxis :
- izquierda : dataframe1.join(dataframe2,dataframe1.column_name == dataframe2.column_name,”left”)
- exterior izquierdo : dataframe1.join(dataframe2,dataframe1.column_name == dataframe2.column_name,”leftouter”)
Ejemplo 1: Realizar combinación izquierda
En este ejemplo, vamos a realizar la combinación izquierda utilizando la palabra clave izquierda en función de la columna ID en ambos marcos de datos.
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# list of employee data
data1 = [["1", "45000", "IT"],
["2", "145000", "Manager"],
["6", "45000", "HR"],
["5", "34000", "Sales"]]
# specify column names
columns = ['ID', 'salary', 'department']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data1, columns)
# left join on two dataframes
dataframe.join(dataframe1,
dataframe.ID == dataframe1.ID,
"left").show()
Producción:

Ejemplo 2: Realizar combinación izquierda
En este ejemplo, vamos a realizar una combinación izquierda utilizando la palabra clave leftouter en función de la columna ID en ambos marcos de datos.
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# list of employee data
data1 = [["1", "45000", "IT"],
["2", "145000", "Manager"],
["6", "45000", "HR"],
["5", "34000", "Sales"]]
# specify column names
columns = ['ID', 'salary', 'department']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data1, columns)
# left join on two dataframes
dataframe.join(dataframe1,
dataframe.ID == dataframe1.ID,
"leftouter").show()
Producción
Unirse a la derecha
Aquí, esta unión se une al marco de datos al devolver todas las filas del segundo marco de datos y solo las filas coincidentes del primer marco de datos con respecto al segundo marco de datos. Podemos realizar este tipo de unión usando right y rightouter.
Sintaxis :
- derecha : dataframe1.join(dataframe2,dataframe1.column_name == dataframe2.column_name,”right”)
- exterior derecho : dataframe1.join(dataframe2,dataframe1.column_name == dataframe2.column_name,”rightouter”)
Ejemplo 1: Ejecutar unión a la derecha
En este ejemplo, vamos a realizar la combinación correcta utilizando la palabra clave correcta en función de la columna de ID en ambos marcos de datos.
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# list of employee data
data1 = [["1", "45000", "IT"],
["2", "145000", "Manager"],
["6", "45000", "HR"],
["5", "34000", "Sales"]]
# specify column names
columns = ['ID', 'salary', 'department']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data1, columns)
# right join on two dataframes
dataframe.join(dataframe1,
dataframe.ID == dataframe1.ID,
"right").show()
Producción:

Ejemplo 2: Realice una unión exterior derecha
En este ejemplo, vamos a realizar la unión correcta utilizando la palabra clave rightouter en función de la columna ID en ambos marcos de datos.
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# list of employee data
data1 = [["1", "45000", "IT"],
["2", "145000", "Manager"],
["6", "45000", "HR"],
["5", "34000", "Sales"]]
# specify column names
columns = ['ID', 'salary', 'department']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data1, columns)
# right join on two dataframes
dataframe.join(dataframe1,
dataframe.ID == dataframe1.ID,
"rightouter").show()
Producción:
Unión semi izquierda
Esta unión incluirá todas las filas del primer marco de datos y devolverá solo las filas coincidentes del segundo marco de datos
Sintaxis: dataframe1.join(dataframe2,dataframe1.column_name == dataframe2.column_name,”leftsemi”)
Ejemplo: en este ejemplo, vamos a realizar una combinación de semiizquierda utilizando la palabra clave semiizquierda en función de la columna ID en ambos marcos de datos.
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# list of employee data
data1 = [["1", "45000", "IT"],
["2", "145000", "Manager"],
["6", "45000", "HR"],
["5", "34000", "Sales"]]
# specify column names
columns = ['ID', 'salary', 'department']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data1, columns)
# leftsemi join on two dataframes
dataframe.join(dataframe1,
dataframe.ID == dataframe1.ID,
"leftsemi").show()
Producción:

LeftAnti unirse
Esta combinación devuelve solo columnas del primer marco de datos para registros no coincidentes del segundo marco de datos
Sintaxis : dataframe1.join(dataframe2,dataframe1.column_name == dataframe2.column_name,”leftanti”)
Ejemplo: en este ejemplo, vamos a realizar la combinación leftanti utilizando la palabra clave leftanti en función de la columna ID en ambos marcos de datos.
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# list of employee data
data1 = [["1", "45000", "IT"],
["2", "145000", "Manager"],
["6", "45000", "HR"],
["5", "34000", "Sales"]]
# specify column names
columns = ['ID', 'salary', 'department']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data1, columns)
# leftanti join on two dataframes
dataframe.join(dataframe1,
dataframe.ID == dataframe1.ID,
"leftanti").show()
Producción:

expresión SQL
Podemos realizar todos los tipos de combinaciones anteriores usando una expresión SQL, tenemos que mencionar el tipo de combinación en esta expresión. Para hacer esto, tenemos que crear una vista temporal.
Sintaxis : dataframe.createOrReplaceTempView(“nombre”)
dónde
- dataframe es el dataframe de entrada
- nombre es el nombre de la vista
Ahora podemos unir estas vistas usando spark.sql().
Sintaxis : spark.sql(“select * from dataframe1, dataframe2 where dataframe1.column_name == dataframe2.column_name “)
dónde,
- dataframe1 es el primer marco de datos de vista
- dataframe2 es el marco de datos de la segunda vista
- column_name es la columna que se unirá
Ejemplo 1: en este ejemplo, uniremos dos marcos de datos según la columna ID.
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# list of employee data
data1 = [["1", "45000", "IT"],
["2", "145000", "Manager"],
["6", "45000", "HR"],
["5", "34000", "Sales"]]
# specify column names
columns = ['ID', 'salary', 'department']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data1, columns)
# create a view for dataframe named student
dataframe.createOrReplaceTempView("student")
# create a view for dataframe1 named department
dataframe1.createOrReplaceTempView("department")
#use sql expression to select ID column
spark.sql(
"select * from student, department\
where student.ID == department.ID").show()
Producción:

También podemos realizar las uniones anteriores usando esta expresión SQL:
Sintaxis : spark.sql(“select * from dataframe1 JOIN_TYPE dataframe2 ON dataframe1.column_name == dataframe2.column_name “)
donde, JOIN_TYPE se refiere a todos los tipos de uniones
Ejemplo 2: Realice una unión interna en la columna ID usando expresión
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# list of employee data
data1 = [["1", "45000", "IT"],
["2", "145000", "Manager"],
["6", "45000", "HR"],
["5", "34000", "Sales"]]
# specify column names
columns = ['ID', 'salary', 'department']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data1, columns)
# create a view for dataframe named student
dataframe.createOrReplaceTempView("student")
# create a view for dataframe1 named department
dataframe1.createOrReplaceTempView("department")
# inner join on id column using sql expression
spark.sql(
"select * from student INNER JOIN \
department on student.ID == department.ID").show()
Producción:
Publicación traducida automáticamente
Artículo escrito por sravankumar8128 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA