Realizar varias operaciones en los datos guardados en SQL puede llevar a realizar consultas muy complejas que no son fáciles de escribir. Entonces, para facilitar esta tarea, a menudo es útil hacer el trabajo usando pandas, que están especialmente diseñados para el preprocesamiento de datos y son más simples y fáciles de usar que SQL.
Puede haber casos en los que, a veces, los datos se almacenan en SQL y queremos obtener esos datos de SQL en python y luego realizar operaciones usando pandas. Entonces, veamos cómo podemos interactuar con bases de datos SQL usando pandas.
Esta es la base de datos con la que vamos a trabajar
diabetes_data
Nota: suponiendo que los datos se almacenen en sqlite3
leyendo los datos
# import the libraries
import sqlite3
import pandas as pd
# create a connection
con = sqlite3.connect('Diabetes.db')
# read data from SQL to pandas dataframe.
data = pd.read_sql_query('Select * from Diabetes;', con)
# show top 5 rows
data.head()
Producción
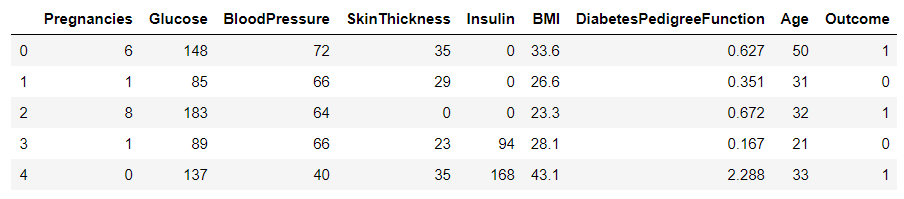
Operación básica
- corte de filas
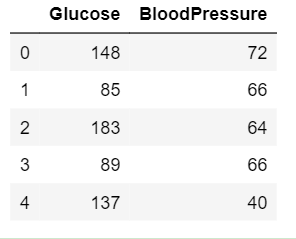
- Selección de columnas específicas
Para seleccionar una columna en particular o para seleccionar el número de columnas del marco de datos para el procesamiento posterior de los datos.# read the data from sql to# pandas dataframe.data=pd.read_sql_query('Select * from Diabetes;', con)# selecting specific columns.df2=data.loc[:, ['Glucose','BloodPressure']].head()df2Producción:
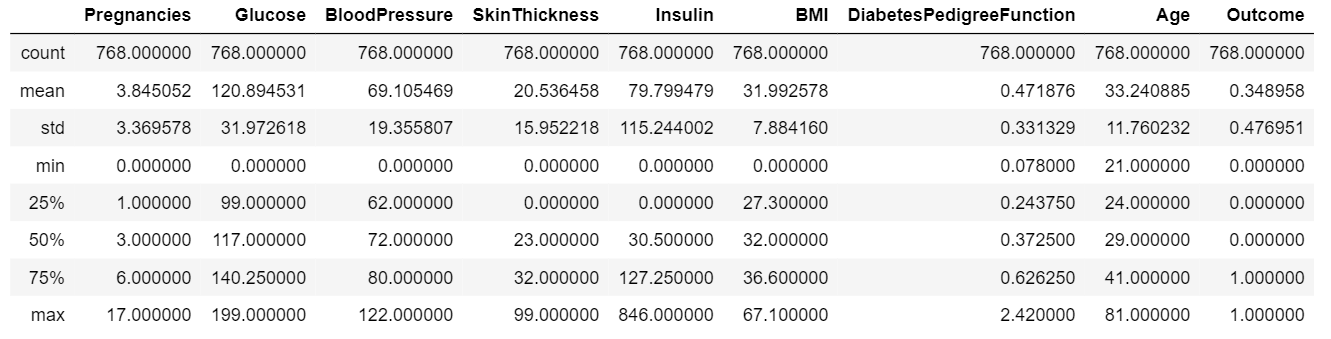
- Resumir los datos
Para obtener información de los datos, debemos tener un resumen estadístico de los datos. Para mostrar un resumen estadístico de los datos, como media, mediana, moda, estándar, etc. Realizamos la siguiente operación# read the data from sql# to pandas dataframe.data=pd.read_sql_query('Select * from Diabetes;', con)# summarize the datadata.describe()Producción:
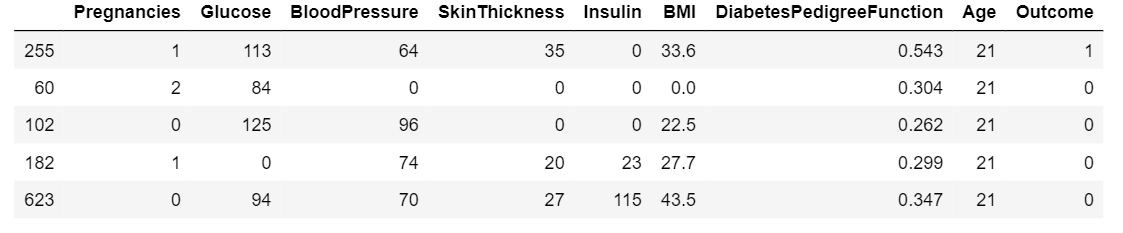
- Ordenar datos con respecto a una columna
Para ordenar el marco de datos con respecto a los valores de una columna dada# read the data from sql# to pandas dataframe.data=pd.read_sql_query('Select * from Diabetes;', con)# sort data with respect# to particular column.data.sort_values(by='Age').head()Producción:
- Mostrar la media de cada columna
Para Mostrar la media de cada columna del marco de datos.# read the data from sql# to pandas dataframe.data=pd.read_sql_query('Select * from Diabetes;', con)# count number of rows and columnsdata.mean()Producción:

Podemos realizar operaciones de corte para obtener el número deseado de filas dentro de un rango determinado.
Con la ayuda del corte, podemos realizar varias operaciones solo en el subconjunto específico de los datos.
# read the data from sql to pandas dataframe.data = pd.read_sql_query('Select * from Diabetes;', con) # slicing the number of rows df1 = data[10:15]df1 |
Producción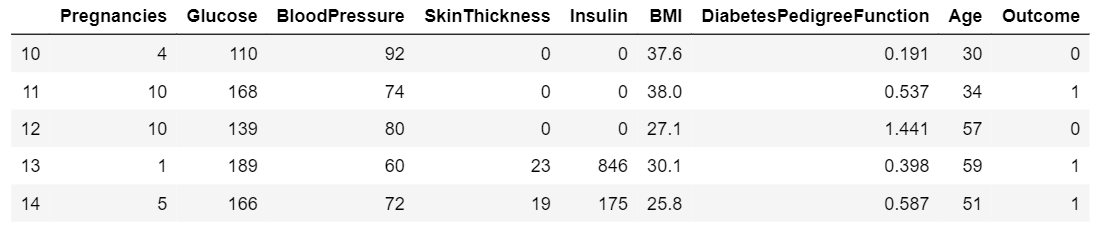
Publicación traducida automáticamente
Artículo escrito por KaranGupta5 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA