La hoja de Excel es una de las formas de archivos más omnipresentes en la industria de TI. Todos los que usan una computadora en un momento u otro se han encontrado y trabajado con hojas de cálculo de Excel. Esta popularidad de Excel se debe a su amplia gama de aplicaciones en el campo del almacenamiento y manipulación de datos en forma tabular y sistemática. Además, las hojas de Excel son muy intuitivas y fáciles de usar, lo que las hace ideales para manipular grandes conjuntos de datos incluso para gente menos técnica. Si está buscando lugares para aprender a manipular y automatizar cosas en archivos de Excel usando Python, no busque más. Usted está en el lugar correcto.
En este artículo, aprenderá a usar Pandas para trabajar con hojas de cálculo de Excel. Al final del artículo, tendrá el conocimiento de:
- Módulos necesarios necesarios para esto y cómo configurarlos en su sistema.
- Lectura de datos de un archivo de Excel en pandas usando Python.
- Explorando los datos de los archivos de Excel en Pandas.
- Uso de funciones para manipular y remodelar los datos en Pandas.
Instalación
Para instalar pandas en Anaconda, podemos usar el siguiente comando en Anaconda Terminal:
conda install pandas
Para instalar pandas en Python regular (no Anaconda), podemos usar el siguiente comando en el símbolo del sistema:
pip install pandas
Empezando
En primer lugar, necesitamos importar el módulo pandas, lo que se puede hacer ejecutando el comando:
import pandas as pds
Archivo de entrada: supongamos que el archivo de Excel se ve así
Hoja 1: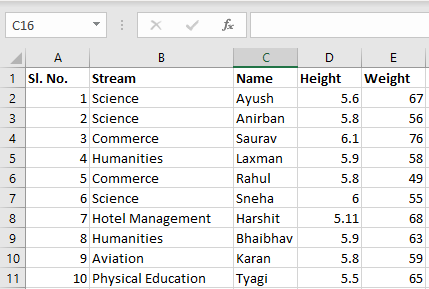
Hoja 2:
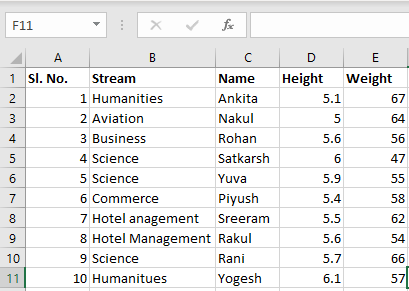
Ahora podemos importar el archivo de Excel usando la función read_excel en pandas, como se muestra a continuación:
file =('path_of_excel_file')
newData = pds.read_excel(file)
newData
Producción: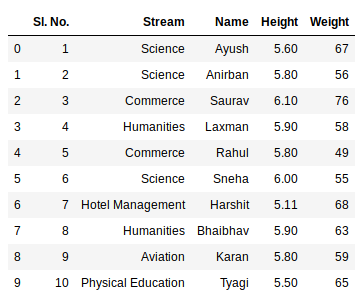
La segunda declaración lee los datos de Excel y los almacena en un marco de datos de pandas que está representado por la variable newData. Si hay varias hojas en el libro de Excel, el comando importará los datos de la primera hoja. Para crear un marco de datos con todas las hojas del libro de trabajo, el método más sencillo es crear diferentes marcos de datos por separado y luego concatenarlos. El método read_excel toma un argumento sheet_namey index_coldonde podemos especificar la hoja de la que debe estar hecho el marco de datos y index_colespecifica la columna de título.
Ejemplo:
sheet1 = pds.read_excel(file, sheet_name = 0, index_col = 0) sheet2 = pds.read_excel(file, sheet_name = 1, index_col = 0) newData = pds.concat([sheet1, sheet2])
La tercera instrucción concatena ambas hojas. Ahora, para verificar todo el marco de datos, simplemente podemos ejecutar el siguiente comando:
newData
Producción: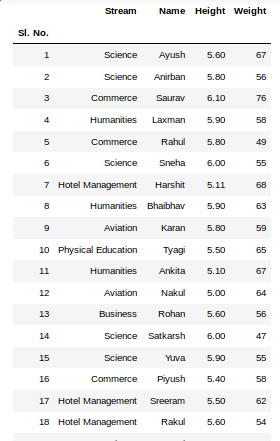
Para ver 5 columnas desde la parte superior y desde la parte inferior del marco de datos, podemos ejecutar el comando:
newData.head() newData.tail()
Producción:
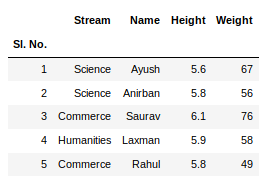
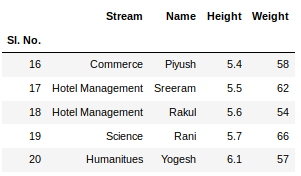
Este método head()también tail()toma argumentos como números para mostrar el número de columnas.
El shape()método se puede utilizar para ver el número de filas y columnas en el marco de datos de la siguiente manera:
newData.shape
Producción:
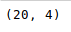
Si alguna columna contiene datos numéricos, podemos ordenar esa columna usando el sort_values()método en pandas de la siguiente manera:
sorted_column = newData.sort_values(['Height'], ascending = False)
Ahora, supongamos que queremos los 5 valores principales de la columna ordenada, podemos usar el head()método aquí:
sorted_column['Height'].head(5)
Producción: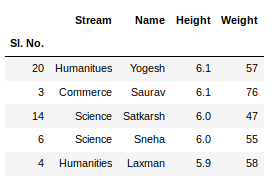
Podemos hacer eso con cualquier columna numérica del marco de datos como se muestra a continuación:
newData['Weight'].head()
Producción: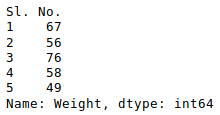
Ahora, supongamos que nuestros datos son principalmente numéricos. Podemos obtener información estadística como media, máx., mín., etc. sobre el marco de datos utilizando el describe()método que se muestra a continuación:
newData.describe()
Producción: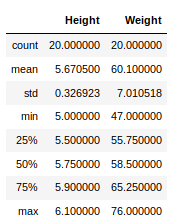
Esto también se puede hacer por separado para todas las columnas numéricas usando el siguiente comando:
newData['Weight'].mean()
Producción:
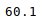
También se puede calcular otra información estadística utilizando los métodos respectivos.
Al igual que en Excel, también se pueden aplicar fórmulas y se pueden crear columnas calculadas de la siguiente manera:
newData['calculated_column']= newData[“Height”] + newData[“Weight”] newData['calculated_column'].head()
Producción: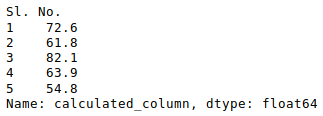
Después de operar con los datos en el marco de datos, podemos exportar los datos a un archivo de Excel usando el método to_excel. Para esto, necesitamos especificar un archivo de salida de Excel donde se escribirán los datos transformados, como se muestra a continuación:
newData.to_excel('Output File.xlsx')
Producción: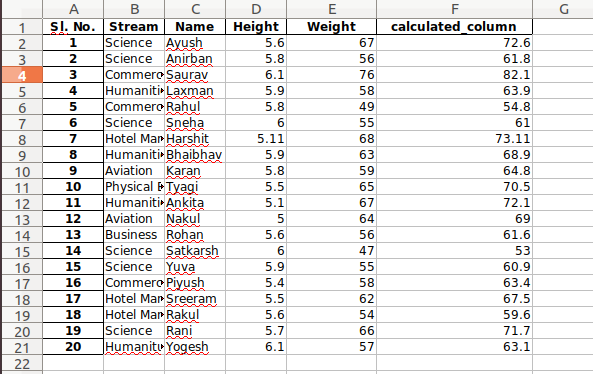
Publicación traducida automáticamente
Artículo escrito por javedju2019 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA