Los datos espaciales , también conocidos como datos geoespaciales, datos GIS o geodatos, son un tipo de datos numéricos que definen la ubicación geográfica de un objeto físico, como un edificio, una calle, un pueblo, una ciudad, un país u otro. objetos físicos, utilizando un sistema de coordenadas geográficas. Puede determinar no solo la posición de un objeto, sino también su longitud, tamaño, área y forma utilizando datos espaciales.
Para trabajar con datos geoespaciales en python necesitamos la biblioteca GeoPandas & GeoPlot
GeoPandas es un proyecto de código abierto para facilitar el trabajo con datos geoespaciales en python. GeoPandas amplía los tipos de datos utilizados por pandas para permitir operaciones espaciales en tipos geométricos. Las operaciones geométricas se realizan con forma. Geopandas depende además de fiona para el acceso a los archivos y de matplotlib para el trazado. GeoPandas depende de su funcionalidad espacial en una gran pila de bibliotecas geoespaciales de código abierto (GEOS, GDAL y PROJ). Consulte la sección Dependencias a continuación para obtener más detalles.
Dependencias requeridas:
- entumecido
- pandas (versión 0.24 o posterior)
- bien formado (interfaz a GEOS)
- fiona (interfaz a GDAL)
- pyproj (interfaz para PROJ; versión 2.2.0 o posterior)
Además, las dependencias opcionales son:
- rtree (opcional; índice espacial para mejorar el rendimiento y requerido para operaciones de superposición; interfaz para libspatialindex)
- psycopg2 (opcional; para conexión PostGIS)
- GeoAlchemy2 (opcional; para escribir en PostGIS)
- geopy (opcional; para trazar, estos adicionales para geocodificación)
Se pueden usar paquetes:
- matplotlib (>= 2.2.0)
- mapclassify (>= 2.2.0)
Geoplot es una biblioteca de visualización de datos geoespaciales para científicos de datos y analistas geoespaciales que desean hacer las cosas rápidamente. A continuación, cubriremos los conceptos básicos de Geoplot y exploraremos cómo se aplica. Geoplot es solo para versiones de Python 3.6+.
Nota: Instale todas las dependencias y módulos para el correcto funcionamiento de los códigos proporcionados.
Instalación
- La instalación se puede hacer a través de Anaconda:
Sintaxis:
conda install geopandas conda install geoplot
- conda-forge es un esfuerzo de la comunidad que proporciona paquetes conda para una amplia gama de software. Proporciona el canal de paquetes conda-forge para conda desde el cual se pueden instalar paquetes, además del canal «predeterminado» proporcionado por Anaconda. GeoPandas y todas sus dependencias están disponibles en el canal conda-forge y se pueden instalar como:
Sintaxis:
conda install --channel conda-forge geopandas conda install geoplot -c conda-forge
- GeoPandas también se puede instalar con pip si también se pueden instalar todas las dependencias:
Sintaxis:
pip install geopandas pip install geoplot
- Puede instalar la última versión de desarrollo clonando el repositorio de GitHub y usando pip para instalar desde el directorio local:
Sintaxis:
git clone https://github.com/geopandas/geopandas.git cd geopandas pip install
- También es posible instalar la última versión de desarrollo directamente desde el repositorio de GitHub con:
Sintaxis:
pip install git+git://github.com/geopandas/geopandas.git
Después de instalar los paquetes junto con sus dependencias, abra un editor de python como spyder. Antes de comenzar con el código, necesitamos descargar algunos archivos de forma (extensión .shp). Puede descargar datos a nivel de país, así como datos a nivel mundial desde aquí en «Datos espaciales gratuitos». Para obtener el archivo de forma utilizado en el tutorial , haga clic aquí .
Leer archivo de forma
Primero, importaremos la biblioteca de geopandas y luego leeremos nuestro archivo de forma usando la variable «world_data». Geopandas puede leer casi cualquier formato de datos espaciales basados en vectores, incluido el archivo de forma ESRI, archivos GeoJSON y más usando el comando:
Sintaxis: geopandas.read_file()
Parámetros
- nombre de archivo: str, objeto de ruta u objeto similar a un archivo. Ya sea la ruta absoluta o relativa al archivo o URL que se abrirá o cualquier objeto con un método read() (como un archivo abierto o StringIO)
- bbox: tupla | GeoDataFrame o GeoSeries | Geometría bien formada, por defecto Ninguno. Filtre las características por un cuadro delimitador dado, GeoSeries, GeoDataFrame o una geometría bien formada. Las discrepancias de CRS se resuelven si se proporciona un GeoSeries o GeoDataFrame. No se puede usar con mascarilla.
- máscara: dict | GeoDataFrame o GeoSeries | Geometría bien formada, por defecto Ninguno. Filtre las entidades que intersecan con la geometría geojson similar a un dictado, GeoSeries, GeoDataFrame o geometría proporcionada. Las discrepancias de CRS se resuelven si se proporciona un GeoSeries o GeoDataFrame. No se puede utilizar con bbox.
- filas: int o slice, predeterminado Ninguno. Cargue en filas específicas pasando un número entero (primeras n filas) o un objeto slice().
- **kwargs: argumentos de palabras clave que se pasarán al método open o BytesCollection en la biblioteca fiona al abrir el archivo. Para obtener más información sobre posibles palabras clave, escriba: import fiona; ayuda(fiona.abrir)
Ejemplo:
Python3
import geopandas as gpd # Reading the world shapefile world_data = gpd.read_file(r'world.shp') world_data
Producción:
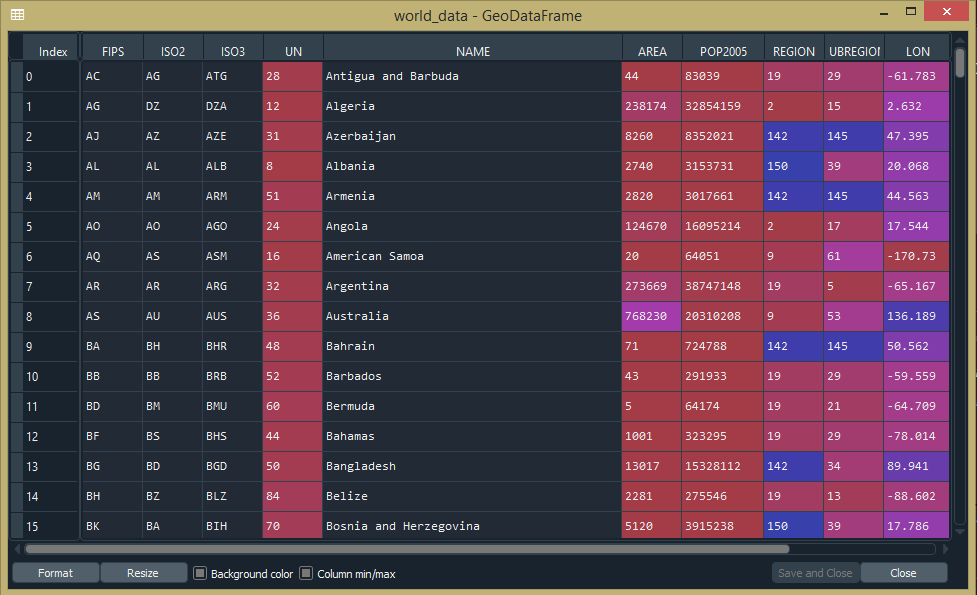
Graficado
Si desea verificar qué tipo de datos está utilizando, vaya a la consola y escriba «type (world_data)», lo que le indica que no son datos de pandas, son geodatos de geopandas. A continuación, vamos a trazar esos GeoDataFrames usando el método plot().
Sintaxis: GeoDataFrame.plot()
Ejemplo:
Python3
import geopandas as gpd # Reading the world shapefile world_data = gpd.read_file(r'world.shp') world_data.plot()
Producción:
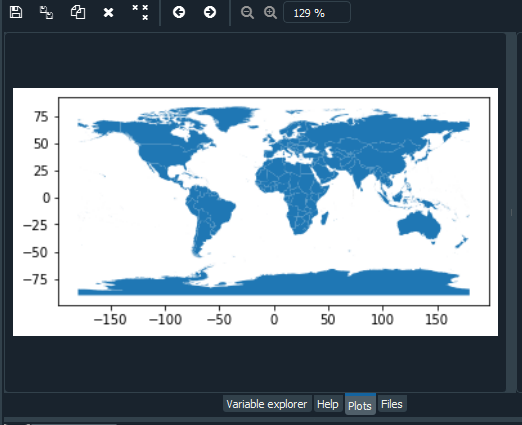
Selección de columnas
Si vemos el GeoDataFrame «world_data», hay muchas columnas (Geoseries) que se muestran, puede elegir Geoseries específicas por:
Sintaxis:
datos[[‘atributo 1’, ‘atributo 2’]]
Ejemplo:
Python3
import geopandas as gpd # Reading the world shapefile world_data = gpd.read_file(r'world.shp') world_data = world_data[['NAME', 'geometry']]
Producción:
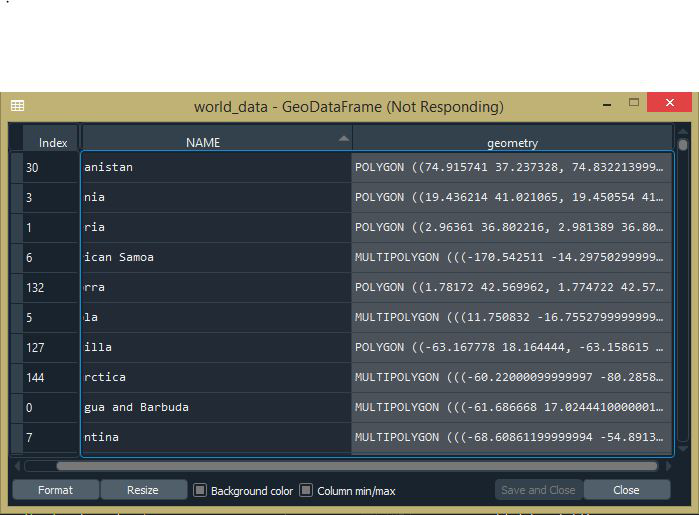
Área de cálculo
Podemos calcular el área de cada país usando geopandas creando una nueva columna «área» y usando la propiedad del área.
Sintaxis:
GeoSeries.area
Devuelve una Serie que contiene el área de cada geometría en GeoSeries expresada en las unidades del CRS.
Ejemplo:
Python3
import geopandas as gpd # Reading the world shapefile world_data = gpd.read_file(r'world.shp') world_data = world_data[['NAME', 'geometry']] # Calculating the area of each country world_data['area'] = world_data.area
Producción:
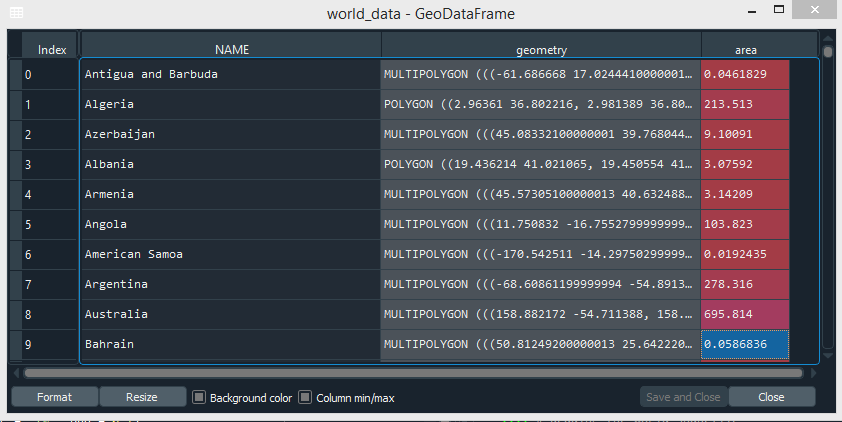
Eliminar un continente
Podemos eliminar un elemento específico de la Geoserie. Aquí estamos eliminando el continente llamado «Antártida» de la Geoserie «Nombre».
Sintaxis:
datos[datos[‘atributo’] != ‘elemento’]
Ejemplo:
Python3
import geopandas as gpd # Reading the world shapefile world_data = gpd.read_file(r'world.shp') world_data = world_data[['NAME', 'geometry']] # Calculating the area of each country world_data['area'] = world_data.area # Removing Antarctica from GeoPandas GeoDataframe world_data = world_data[world_data['NAME'] != 'Antarctica'] world_data.plot()
Producción:
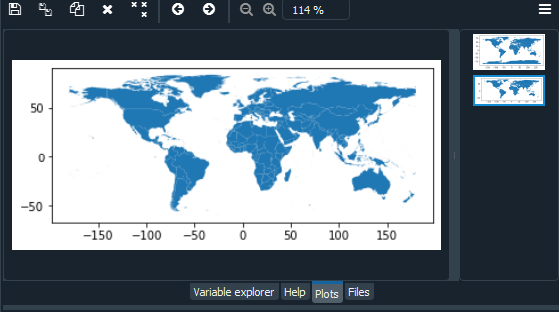
Visualización de un país específico
Podemos visualizar/trazar un país específico seleccionándolo. En el siguiente ejemplo, estamos seleccionando «India» de la columna «NOMBRE».
Sintaxis:
datos[datos.atributo==”elemento”].plot()
Ejemplo:
Python3
import geopandas as gpd import matplotlib.pyplot as plt from mpl_toolkits.axes_grid1 import make_axes_locatable # Reading the world shapefile world_data = gpd.read_file(r'world.shp') world_data = world_data[['NAME', 'geometry']] # Calculating the area of each country world_data['area'] = world_data.area # Removing Antarctica from GeoPandas GeoDataframe world_data = world_data[world_data['NAME'] != 'Antarctica'] world_data[world_data.NAME=="India"].plot()
Producción:
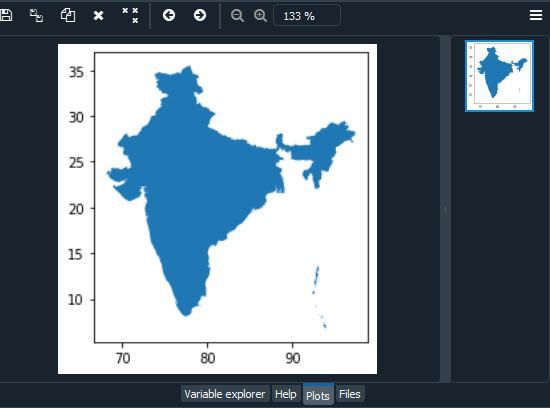
Sistema de referencia de coordenadas
Podemos verificar nuestro Sistema de coordenadas actual utilizando Geopandas CRS, es decir, el Sistema de referencia de coordenadas. Además, podemos cambiarlo a un sistema de coordinación de proyección. El Sistema de referencia de coordenadas (CRS) se representa como un objeto pyproj.CRS. Podemos verificar el CRS actual usando la siguiente sintaxis.
Sintaxis:
GeoDataFrame.crs
El método to_crs() transforma geometrías a un nuevo sistema de referencia de coordenadas. Transforme todas las geometrías en una columna de geometría activa a un sistema de referencia de coordenadas diferente. Se debe establecer el atributo CRS en el GeoSeries actual. Se puede especificar CRS o epsg para la salida. Este método transformará todos los puntos en todos los objetos. No tiene noción ni proyección de geometrías enteras. Se supone que todos los puntos de unión de segmentos están alineados en la proyección actual, no geodésicas. Los objetos que crucen la línea de fecha (u otro límite de proyección) tendrán un comportamiento no deseado.
Sintaxis: GeoDataFrame.to_crs(crs=Ninguno, epsg=Ninguno, inplace=False)
Parámetros
- crs: pyproj.CRS, opcional si se especifica epsg. El valor puede ser cualquier cosa aceptada por pyproj.CRS.from_user_input(), como una string de autoridad (por ejemplo, «EPSG:4326») o una string WKT.
- epsg: int, opcional si se especifica crs. Código EPSG que especifica la proyección de salida.
- en lugar: booleano, opcional, predeterminado: Falso. Ya sea para devolver un nuevo GeoDataFrame o hacer la transformación en el lugar.
Ejemplo:
Python3
import geopandas as gpd # Reading the world shapefile world_data = gpd.read_file(r'world.shp') world_data = world_data[['NAME', 'geometry']] # Calculating the area of each country world_data['area'] = world_data.area # Removing Antarctica from GeoPandas GeoDataframe world_data = world_data[world_data['NAME'] != 'Antarctica'] # Changing the projection current_crs = world_data.crs world_data.to_crs(epsg=3857, inplace=True) world.plot()
Producción:
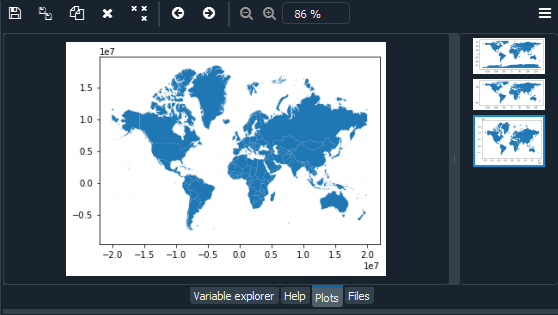
Uso de mapas de colores (cmap)
Podemos colorear cada país del mundo usando una columna de encabezado y un cmap. Para averiguar la columna de encabezado, escriba «world_data.head()» en la consola. Podemos elegir diferentes mapas de color (cmap) disponibles en matplotlib. En el siguiente código, tenemos países coloreados usando la columna de argumentos plot() y cmap.
Ejemplo:
Python3
import geopandas as gpd # Reading the world shapefile world_data = gpd.read_file(r'world.shp') world_data = world_data[['NAME', 'geometry']] # Calculating the area of each country world_data['area'] = world_data.area # Removing Antarctica from GeoPandas GeoDataframe world_data = world_data[world_data['NAME'] != 'Antarctica'] # Changing the projection current_crs = world_data.crs world_data.to_crs(epsg=3857, inplace=True) world_data.plot(column='NAME', cmap='hsv')
Producción:
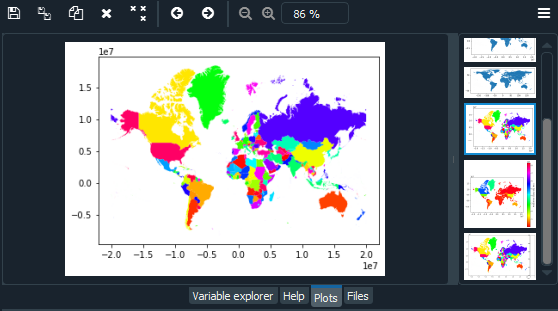
Agregar una leyenda
A continuación, vamos a convertir el área en kilómetros cuadrados dividiéndola por 10^6, es decir, (1000000). La salida se puede ver en el explorador de variables en la variable «world_data».
Podemos agregar una leyenda a nuestro mapa mundial junto con una etiqueta usando argumentos plot()
- Leyenda: bool (por defecto Falso). Trazar una leyenda. Se ignora si no se proporciona ninguna columna o si se proporciona un color.
- legend_kwds: dict (predeterminado Ninguno). Argumentos de palabras clave para pasar a matplotlib.pyplot.legend() o matplotlib.pyplot.colorbar(). Palabras clave adicionales aceptadas cuando se especifica el esquema:
- fmt: string. Una especificación de formato para los bordes del contenedor de las clases en la leyenda. Por ejemplo, para no tener decimales: {“fmt”: “{:.0f}”}.
- etiquetas: en forma de lista. Una lista de etiquetas de leyenda para anular las etiquetas generadas automáticamente. Necesita tener el mismo número de elementos que el número de clases (k).
- intervalo: booleano (falso predeterminado). Una opción para controlar los corchetes desde la leyenda mapclassify. Si es Verdadero, los paréntesis de intervalo abierto/cerrado se muestran en la leyenda.
Ejemplo:
Python3
import geopandas as gpd
# Reading the world shapefile
world_data = gpd.read_file(r'world.shp')
world_data = world_data[['NAME', 'geometry']]
# Calculating the area of each country
world_data['area'] = world_data.area
# Removing Antarctica from GeoPandas GeoDataframe
world_data = world_data[world_data['NAME'] != 'Antarctica']
world_data.plot()
# Changing the projection
current_crs = world_data.crs
world_data.to_crs(epsg=3857, inplace=True)
world_data.plot(column='NAME', cmap='hsv')
# Re-calculate the areas in Sq. Km.
world_data['area'] = world_data.area/1000000
# Adding a legend
world_data.plot(column='area', cmap='hsv', legend=True,
legend_kwds={'label': "Area of the country (Sq. Km.)"},
figsize=(7, 7))
Producción:
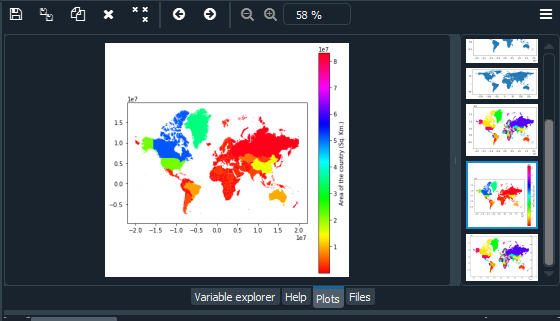
Cambiar el tamaño de la leyenda
También podemos cambiar el tamaño de la leyenda usando los argumentos ax y cax de plot().
- hacha: matplotlib.pyplot. Artista (predeterminado Ninguno). ejes sobre los que dibujar el gráfico.
- cax: matplotlib.pyplot Artista (predeterminado Ninguno). ejes sobre los que dibujar la leyenda en caso de mapa a color.
Para esto, necesitamos la biblioteca matplotlib.
La función axes_divider.make_axes_locatable toma los ejes existentes, los agrega a un nuevo AxesDivider y devuelve el AxesDivider. El método append_axes de AxesDivider se puede usar para crear nuevos ejes en un lado determinado («arriba», «derecha», «abajo» o «izquierda») de los ejes originales. Para crear ejes en la posición dada con la misma altura (o ancho) de los ejes principales-
Sintaxis:
append_axes(self, position, size, pad=Ninguno, add_to_figure=True, **kwargs)
La posición puede tomar cualquier valor de: «izquierda», «derecha», «abajo» o «arriba».
size y pad deben ser compatibles con axes_grid.axes_size.
Ejemplo:
Python3
import geopandas as gpd
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1 import make_axes_locatable
# Reading the world shapefile
world_data = gpd.read_file(r'world.shp')
world_data = world_data[['NAME', 'geometry']]
# Calculating the area of each country
world_data['area'] = world_data.area
# Removing Antarctica from GeoPandas GeoDataframe
world_data = world_data[world_data['NAME'] != 'Antarctica']
world_data.plot()
# Changing the projection
current_crs = world_data.crs
world_data.to_crs(epsg=3857, inplace=True)
world_data.plot(column='NAME', cmap='hsv')
# Re-calculate the areas in Sq. Km.
world_data['area'] = world_data.area/1000000
# Adding a legend
world_data.plot(column='area', cmap='hsv', legend=True,
legend_kwds={'label': "Area of the country (Sq. Km.)"},
figsize=(7, 7))
# Resizing the legend
fig, ax = plt.subplots(figsize=(10, 10))
divider = make_axes_locatable(ax)
cax = divider.append_axes("right", size="7%", pad=0.1)
world_data.plot(column='area', cmap='hsv', legend=True,
legend_kwds={'label': "Area of the country (Sq. Km.)"},
ax=ax, cax=cax)
Producción:
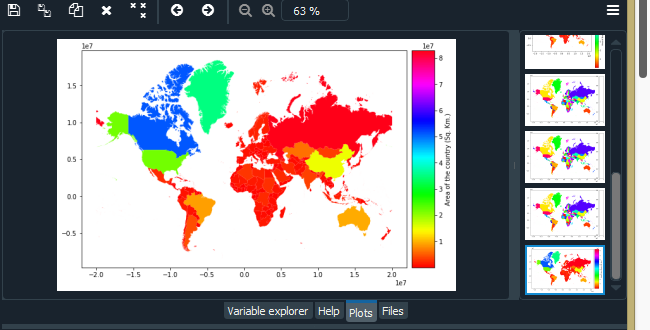
Polyplot y Pointplot utilizando la biblioteca Geoplot
Primero, importaremos la biblioteca Geoplot. A continuación, cargaremos uno de los conjuntos de datos de muestra (archivo geojson) presente en geoplot. En el siguiente ejemplo, vamos a utilizar los conjuntos de datos «world», «contiguous_usa», «usa_cities», «melbourne» y «melbourne_schools». La lista de conjuntos de datos presentes en geoplot se menciona a continuación:
- usa_cities
- Estados Unidos_contiguos
- factores_de_colisión_de_nyc
- nyc_boroughs
- ny_census
- obesidad_por_estado
- la_vuelos
- dc_carreteras
- nyc_map_pluto_sample
- nyc_collisiones_muestra
- boston_zip_codes
- boston_airbnb_listings
- napoleon_troop_movements
- colisiones_fatales_nyc
- nyc_injurious_collisions
- precintos_de_la_policia_de_nyc
- nyc_parking_tickets
- mundo
- melbourne
- colegios_melbourne
- San Francisco
- san_francisco_street_trees_sample
- distritos_del_congreso_de_california
Podemos agregar nuestros propios conjuntos de datos editando el archivo datasets.py. Haga clic aquí para obtener algunos conjuntos de datos de muestra gratuitos.
- Si tiene datos poligonales, puede trazarlos usando un poligráfico geoplot.
- Si sus datos consisten en un montón de puntos, puede mostrar esos puntos usando un diagrama de puntos.
Sintaxis:
geoplot.datasets.get_path(str)
Sintaxis para el trazado:
geoplot.polyplot(var) geoplot.pointplot(var)
Ejemplo:
Python3
import geoplot as gplt
import geopandas as gpd
# Reading the world shapefile
path = gplt.datasets.get_path("world")
world = gpd.read_file(path)
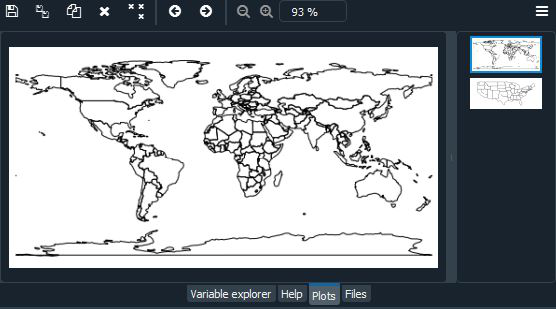
gplt.polyplot(world)
path = gplt.datasets.get_path("contiguous_usa")
contiguous_usa = gpd.read_file(path)
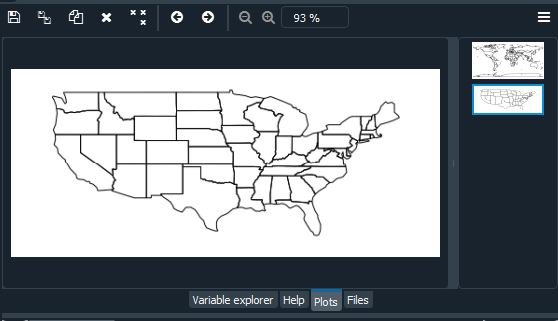
gplt.polyplot(contiguous_usa)
path = gplt.datasets.get_path("usa_cities")
usa_cities = gpd.read_file(path)
gplt.pointplot(usa_cities)
path = gplt.datasets.get_path("melbourne")
melbourne = gpd.read_file(path)
gplt.polyplot(melbourne)
path = gplt.datasets.get_path("melbourne_schools")
melbourne_schools = gpd.read_file(path)
gplt.pointplot(melbourne_schools)
Conjunto de datos mundial:
Conjunto de datos de EE. UU.:
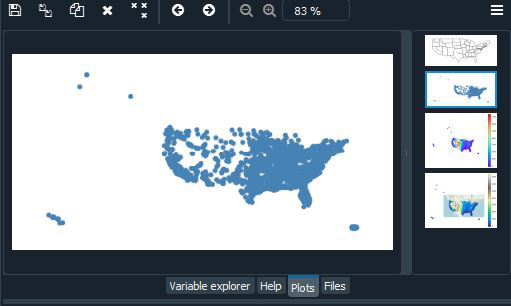
Conjunto de datos de ciudades de EE. UU.:
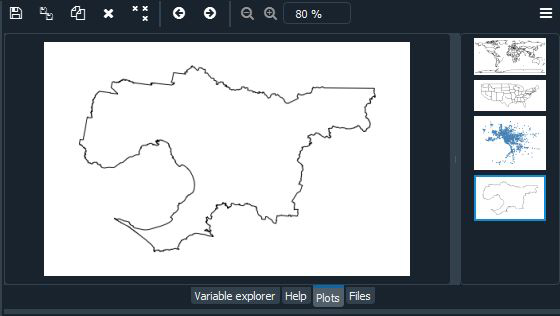
Conjunto de datos de Melbourne:
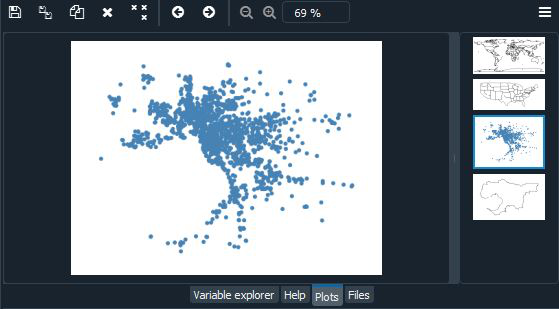
Conjunto de datos de las escuelas de Melbourne:
Podemos combinar estas dos gráficas usando overplotting. Overplotting es el acto de apilar varios gráficos diferentes uno encima del otro, útil para proporcionar contexto adicional para nuestros gráficos:
Ejemplo:
Python3
import geoplot as gplt
import geopandas as gpd
# Reading the world shapefile
path = gplt.datasets.get_path("usa_cities")
usa_cities = gpd.read_file(path)
path = gplt.datasets.get_path("contiguous_usa")
contiguous_usa = gpd.read_file(path)
path = gplt.datasets.get_path("melbourne")
melbourne = gpd.read_file(path)
path = gplt.datasets.get_path("melbourne_schools")
melbourne_schools = gpd.read_file(path)
ax = gplt.polyplot(contiguous_usa)
gplt.pointplot(usa_cities, ax=ax)
ax = gplt.polyplot(melbourne)
gplt.pointplot(melbourne_schools, ax=ax)
Producción:
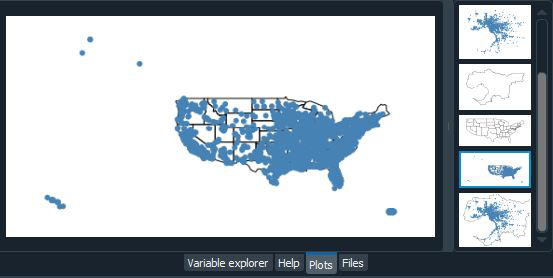
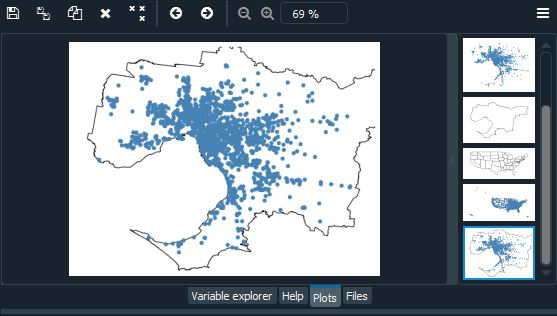
Es posible que hayas notado que este mapa de los Estados Unidos parece extraño. Debido a que la Tierra es una esfera, es difícil representarla en dos dimensiones. Como resultado, usamos algún tipo de proyección, o medio para aplanar la esfera, cada vez que tomamos datos de la esfera y los colocamos en un mapa. Cuando traza datos sin una proyección, o «carta blanca», su mapa se distorsionará. Podemos «corregir» las distorsiones eligiendo un método de proyección. Aquí vamos a utilizar la proyección de áreas iguales de Albers y WebMercator.
Junto con esto, también agregaremos algunos otros parámetros, como tono, leyenda, cmap y esquema.
- El parámetro de tono aplica un mapa de colores a una columna de datos.
- El parámetro de leyenda alterna una leyenda.
- Cambie el mapa de colores usando cmap de matplotlib.
- Para un mapa de colores categórico, use un esquema.
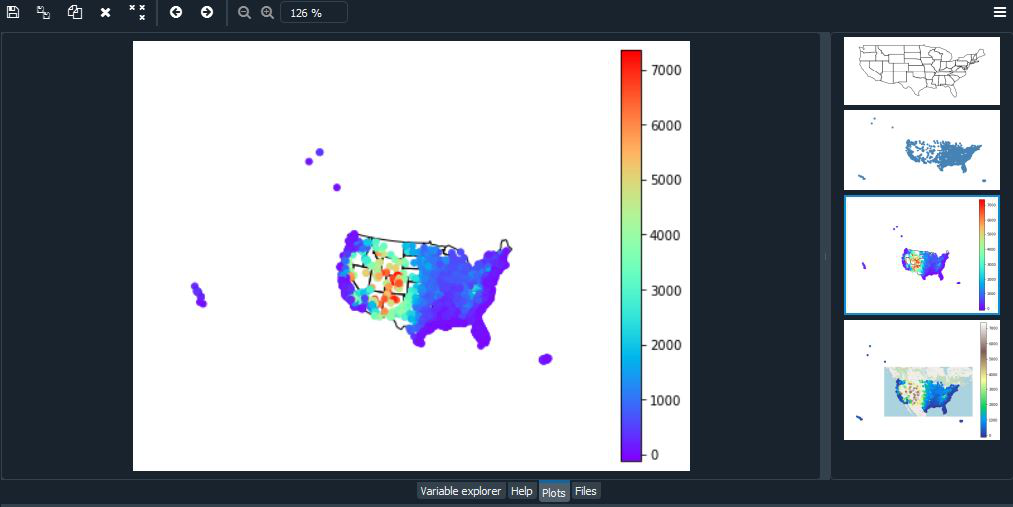
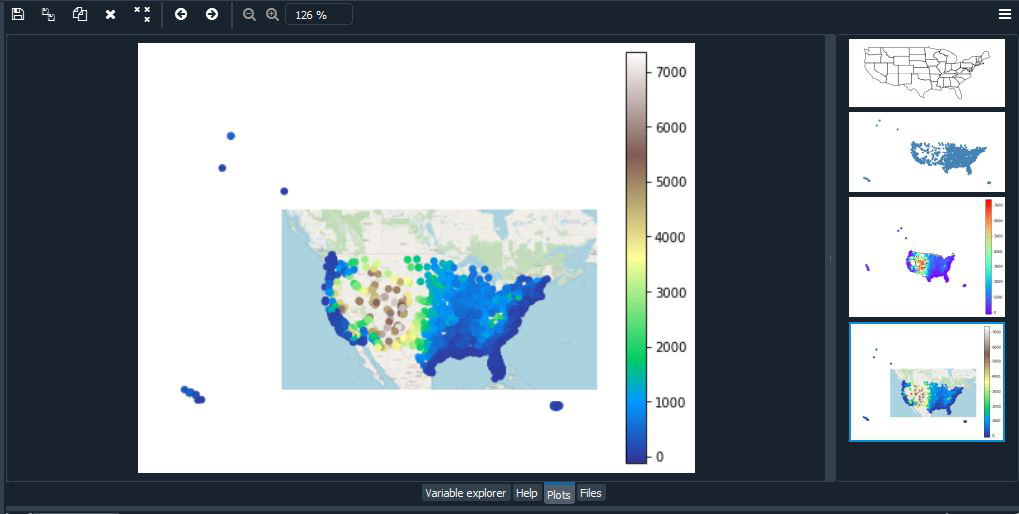
Ejemplo:
Python3
import geoplot as gplt
import geopandas as gpd
import geoplot.crs as gcrs
# Reading the world shapefile
path = gplt.datasets.get_path("contiguous_usa")
contiguous_usa = gpd.read_file(path)
path = gplt.datasets.get_path("usa_cities")
usa_cities = gpd.read_file(path)
ax = gplt.polyplot(contiguous_usa, projection=gcrs.AlbersEqualArea())
gplt.pointplot(usa_cities, ax=ax, hue="ELEV_IN_FT",cmap='rainbow',
legend=True)
ax = gplt.webmap(contiguous_usa, projection=gcrs.WebMercator())
gplt.pointplot(usa_cities, ax=ax, hue='ELEV_IN_FT', cmap='terrain',
legend=True)
Producción:
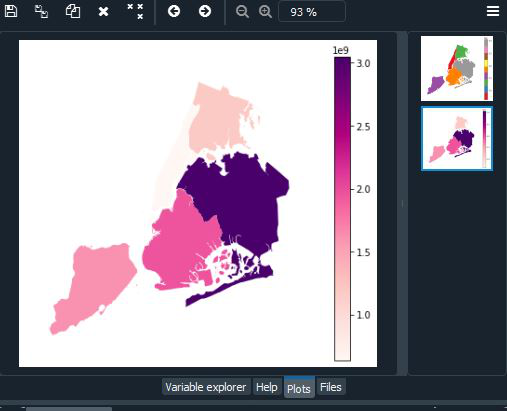
Coropletas en Geoplot
Una coropleta toma datos que se han agregado en algún nivel poligonal significativo (p. ej., distrito censal, estado, país o continente) y usa colores para mostrárselos al lector. Es un tipo de trama muy conocido, y es quizás el más conocido y de propósito general de los tipos de trama espacial. Una coropleta básica requiere geometrías poligonales y una variable de tono. Cambie el mapa de colores usando cmap de matplotlib. El parámetro de leyenda alterna la leyenda.
Sintaxis:
geoplot.choropleth(var)
Ejemplo:
Python3
import geoplot as gplt
import geopandas as gpd
import geoplot.crs as gcrs
# Reading the world shapefile
boroughs = gpd.read_file(gplt.datasets.get_path('nyc_boroughs'))
gplt.choropleth(boroughs, hue='Shape_Area',
projection=gcrs.AlbersEqualArea(),
cmap='RdPu', legend=True)
Producción:
Para pasar el argumento de palabra clave a la leyenda, utilice el argumento legend_kwargs. Para especificar un mapa de colores categórico, utilice un esquema. Utilice legend_labels y legend_values para personalizar las etiquetas y los valores que aparecen en la leyenda. Aquí vamos a utilizar mapclassify, que es una biblioteca de Python de código abierto para la clasificación de mapas de Choropleth. Para instalar mapclassify use:
- mapclassify está disponible en conda a través del canal conda-forge:
Sintaxis:
conda install -c conda-forge mapclassify
- mapclassify también está disponible en el índice de paquetes de Python:
Sintaxis:
pip install -U clasificación de mapa
Ejemplo:
Python3
import geoplot as gplt
import geopandas as gpd
import geoplot.crs as gcrs
import mapclassify as mc
# Reading the world shapefile
contiguous_usa = gpd.read_file(gplt.datasets.get_path('contiguous_usa'))
scheme = mc.FisherJenks(contiguous_usa['population'], k=5)
gplt.choropleth(
contiguous_usa, hue='population', projection=gcrs.AlbersEqualArea(),
edgecolor='white', linewidth=1,
cmap='Reds', legend=True, legend_kwargs={'loc': 'lower left'},
scheme=scheme, legend_labels=[
'<3 million', '3-6.7 million', '6.7-12.8 million',
'12.8-25 million', '25-37 million'
]
)
Producción:
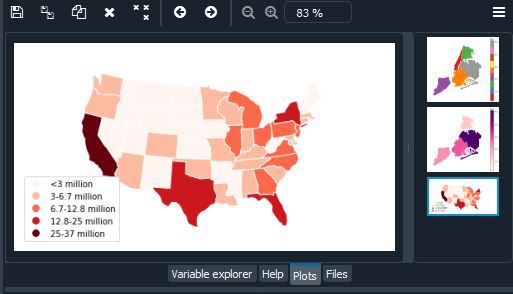
Gráfico de KDE en Geoplot
La estimación de densidad kernel es una técnica que estima de forma no paramétrica una función de distribución para un conjunto de observaciones puntuales sin utilizar parámetros. Los KDE son un método popular para examinar distribuciones de datos; en esta figura, la técnica se aplica a una situación geoespacial. Un KDEplot básico toma datos puntuales como entrada.
Sintaxis:
geoplot.kdeplot(var)
Ejemplo:
Python3
import geoplot as gplt
import geopandas as gpd
import geoplot.crs as gcrs
# Reading the world shapefile
boroughs = gpd.read_file(gplt.datasets.get_path('nyc_boroughs'))
collisions = gpd.read_file(gplt.datasets.get_path('nyc_collision_factors'))
ax = gplt.polyplot(boroughs, projection=gcrs.AlbersEqualArea())
gplt.kdeplot(collisions, ax=ax)
Producción:
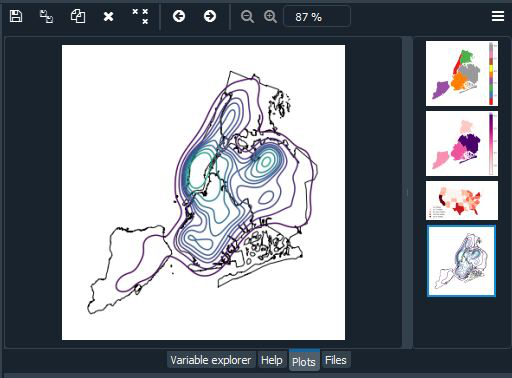
Sankey en Geoplot
Un diagrama de Sankey representa el flujo de información a través de una red. Es útil para mostrar las magnitudes de los datos que fluyen a través de un sistema. Esta figura coloca el diagrama de Sankey en un contexto geoespacial, lo que lo hace útil para monitorear cargas de tráfico en una red de carreteras o volúmenes de viajes entre aeropuertos, por ejemplo. Un Sankey básico requiere un GeoDataFrame de geometrías LineString o MultiPoint. hue agrega una gradación de color al mapa. Use cmap de matplotlib para controlar el mapa de colores. Para un mapa de colores categórico, especifique el esquema. leyenda alterna una leyenda. Aquí estamos usando la proyección de Mollweide
Sintaxis;
geoplot.sankey(var)
Ejemplo:
Python3
import geoplot as gplt
import geopandas as gpd
import geoplot.crs as gcrs
import mapclassify as mc
# Reading the world shapefile
la_flights = gpd.read_file(gplt.datasets.get_path('la_flights'))
world = gpd.read_file(gplt.datasets.get_path('world'))
scheme = mc.Quantiles(la_flights['Passengers'], k=5)
ax = gplt.sankey(la_flights, projection=gcrs.Mollweide(),
scale='Passengers', hue='Passengers',
scheme=scheme, cmap='Oranges', legend=True)
gplt.polyplot(world, ax=ax, facecolor='lightgray', edgecolor='white')
ax.set_global(); ax.outline_patch.set_visible(True)
Producción:
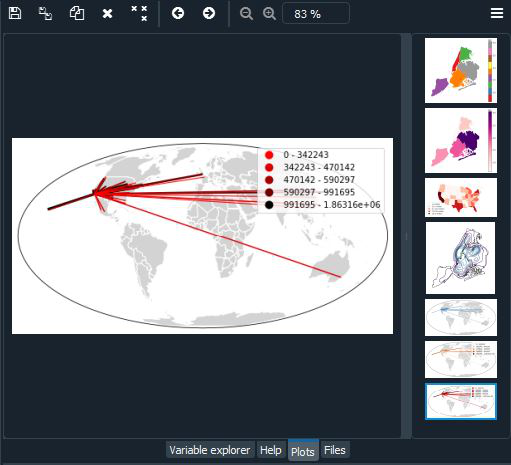
Publicación traducida automáticamente
Artículo escrito por meetpopat09 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA