Los gráficos relacionales se utilizan para visualizar la relación estadística entre los puntos de datos. La visualización es necesaria porque le permite al ser humano ver tendencias y patrones en los datos. El proceso de comprender cómo las variables en el conjunto de datos se relacionan entre sí y sus relaciones se denomina análisis estadístico.
Seaborn, a diferencia de matplotlib, también proporciona algunos conjuntos de datos predeterminados. En este artículo, usaremos un conjunto de datos predeterminado llamado ‘consejos’. Este conjunto de datos brinda información sobre las personas que comieron en algún restaurante y si dejaron propina a los meseros o no, su género y si fuman o no, y más.
Echemos un vistazo al conjunto de datos.
python3
# importing the library
import seaborn as sns
# reading the dataset
data = sns.load_dataset('tips')
# printing first five entries
print(data.head())
Producción :
total_bill tip sex smoker day time size 0 16.99 1.01 Female No Sun Dinner 2 1 10.34 1.66 Male No Sun Dinner 3 2 21.01 3.50 Male No Sun Dinner 3 3 23.68 3.31 Male No Sun Dinner 2 4 24.59 3.61 Female No Sun Dinner 4
Dibujar las tramas relacionales seaborn proporciona tres funciones. Estos son:
- relplot()
- gráfico de dispersión()
- diagrama de line()
Seaborn.relplot()
Esta función nos proporciona acceso a otras funciones a nivel de ejes diferentes que muestran las relaciones entre dos variables con asignaciones semánticas de subconjuntos.
Sintaxis:
seaborn.relplot(x=None, y=None, data=None, **kwargs)
Parámetros:
| Parámetro | Valor | Usar |
|---|---|---|
| x, y | numérico | Variables de datos de entrada |
| Datos | Marco de datos | Conjunto de datos que se está utilizando. |
| tono, tamaño, estilo | nombre en datos; opcional | Variable de agrupación que producirá elementos con diferentes colores. |
| tipo | dispersión o línea; predeterminado: dispersión | define el tipo de gráfico, ya sea scatterplot() o lineplot() |
| fila, columna | nombres de variables en datos; opcional | Variables categóricas que determinarán el facetado de la grilla. |
| col_envoltura | En t; opcional | «Envuelva» la variable de la columna con este ancho, de modo que las facetas de la columna abarquen varias filas. |
| orden_filas, orden_col | listas de strings; opcional | Orden para organizar las filas y columnas de la grilla. |
| paleta | nombre, lista o dictado; opcional | Colores a utilizar para los diferentes niveles de la variable matiz. |
| tono_orden | lista; opcional | Orden especificado para la aparición de los niveles de la variable de matiz. |
| tono_norma | tupla o Normalizar objeto; opcional | Normalización en unidades de datos para mapa de colores aplicado a la variable matiz cuando es numérica. |
| tamaños | lista, dictado o tupla; opcional | determina el tamaño de cada punto en el gráfico. |
| tamaño_pedido | lista; opcional | Orden especificado para la aparición de los niveles de la variable de tamaño |
| tamaño_norma | tupla o Normalizar objeto; opcional | Normalización en unidades de datos para escalar objetos de trazado cuando la variable de tamaño es numérica. |
| leyenda | “breve”, “completo” o Falso; opcional | Si es «breve», las variables numéricas de tono y tamaño se representarán con una muestra de valores espaciados uniformemente. Si está «lleno», cada grupo obtendrá una entrada en la leyenda. Si es False, no se agregan datos de leyenda y no se dibuja ninguna leyenda. |
| altura | escalar; opcional | Altura (en pulgadas) de cada faceta. |
| Aspecto | escalar; opcional | Relación de aspecto de cada faceta, es decir, ancho/alto |
| faceta_kws | dictar; opcional | Diccionario de otros argumentos de palabras clave para pasar a FacetGrid. |
| kwargs | pares de clave y valor | Otros argumentos de palabras clave se pasan a la función de trazado subyacente. |
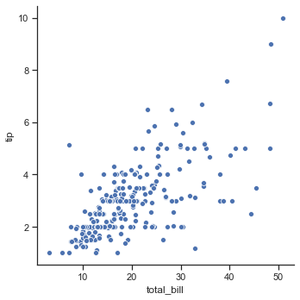
Ejemplo 1: visualización del gráfico más básico para mostrar todos los puntos de datos en el conjunto de datos de consejos.
Python3
# importing the library
import seaborn as sns
# selecting style
sns.set(style ="ticks")
# reading the dataset
tips = sns.load_dataset('tips')
# plotting a simple visualization of data points
sns.relplot(x ="total_bill", y ="tip", data = tips)
Producción :
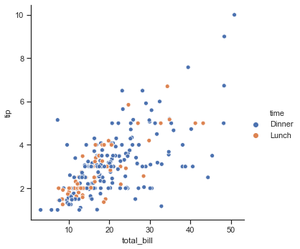
Ejemplo 2: Agrupación de puntos de datos en función de la categoría, aquí como tiempo.
Python3
# importing the library
import seaborn as sns
# selecting style
sns.set(style ="ticks")
# reading the dataset
tips = sns.load_dataset('tips')
sns.relplot(x="total_bill",
y="tip",
hue="time",
data=tips)
Producción :
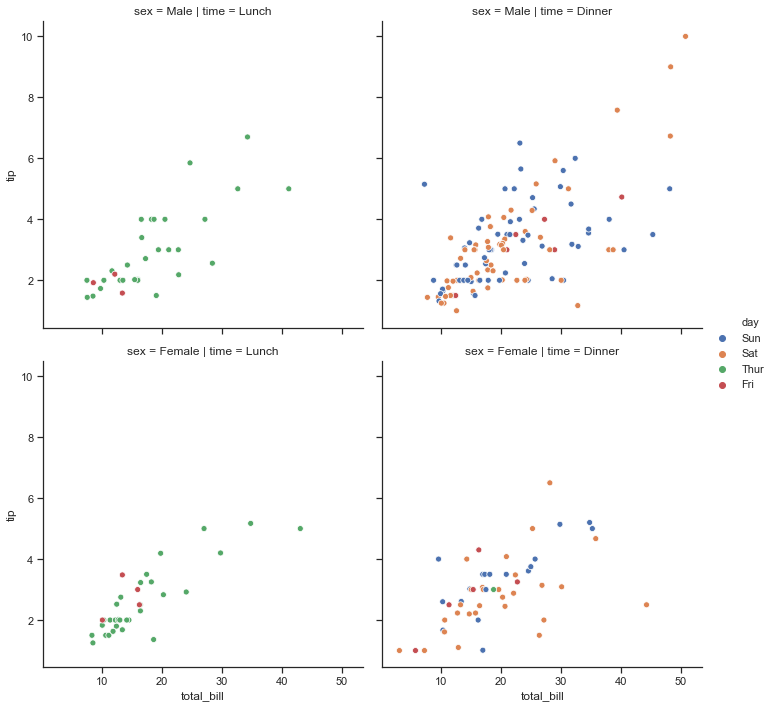
Ejemplo 3: usar el tiempo y el sexo para determinar la faceta de la cuadrícula.
Python3
# importing the library
import seaborn as sns
# selecting style
sns.set(style ="ticks")
# reading the dataset
tips = sns.load_dataset('tips')
sns.relplot(x="total_bill",
y="tip",
hue="day",
col="time",
row="sex",
data=tips)
Salida :
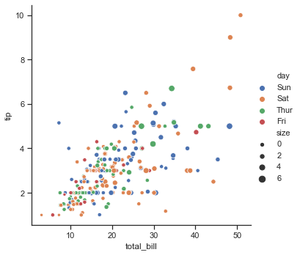
Ejemplo 4: usando el atributo de tamaño, podemos ver puntos de datos que tienen un tamaño diferente.
Python3
# importing the library
import seaborn as sns
# selecting style
sns.set(style ="ticks")
# reading the dataset
tips = sns.load_dataset('tips')
sns.relplot(x="total_bill",
y="tip",
hue="day",
size="size",
data=tips)
Salida :