La función pandas dataframe.groupby() es una de las funciones más útiles de la biblioteca, divide los datos en grupos según las columnas/condiciones y luego aplica algunas operaciones, por ejemplo. size() que cuenta el número de entradas/filas en cada grupo. El groupby() también se puede aplicar en series.
Sintaxis: DataFrame.groupby(by=Ninguno, eje=0, nivel=Ninguno, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)
Parámetros:
by: mapeo, función, string o iterable
eje: int, nivel predeterminado 0
: si el eje es un índice múltiple (jerárquico), agrupar por un nivel o niveles particulares
as_index: para la salida agregada, devolver el objeto con etiquetas de grupo como índice. Solo relevante para la entrada de DataFrame. as_index=False es efectivamente una ordenación de salida agrupada de «estilo SQL»
: Ordenar claves de grupo. Obtenga un mejor rendimiento desactivando esto. Tenga en cuenta que esto no influye en el orden de las observaciones dentro de cada grupo. groupby conserva el orden de las filas dentro de cada grupo.
grupo_claves:Al llamar a apply, agregue claves de grupo al índice para identificar piezas
squeeze: reduzca la dimensionalidad del tipo de devolución si es posible; de lo contrario, devuelva un tipo consistente
Devoluciones: objeto GroupBy
En el siguiente ejemplo, vamos a hacer uso de dos bibliotecas seaborn y pandas donde se usa seaborn para trazar y pandas para leer datos. Vamos a utilizar los métodos load_dataset() de seaborn para cargar el conjunto de datos penguins.csv.
Python3
# import the module
import seaborn as sns
dataset = sns.load_dataset('penguins')
# displaying the data
print(dataset.head())
Producción :
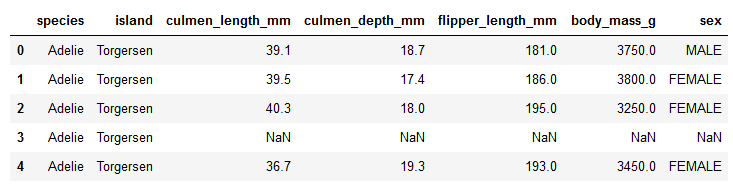
Las cinco primeras filas del conjunto de datos
Python3
# display the number of columns and their data types dataset.info()
Producción :

Información sobre el conjunto de datos
Estaremos agrupando los datos usando el método groupby() de acuerdo con la ‘isla’ y representándolos.
Python3
# apply groupby on the island column # plotting dataset.groupby(['island']).size().plot(kind = "bar")
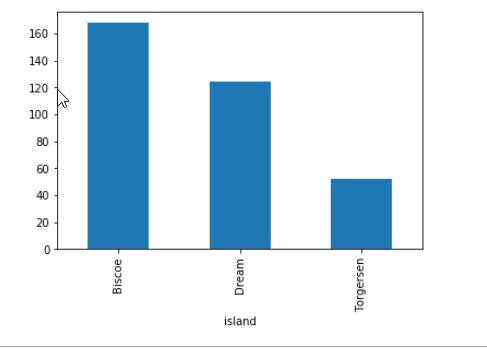
Gráfico del tamaño de groupby() usando Pandas
Python3
# use the groupby() function to group island column # and apply size() function # size() is equivalent to counting the distinct rows result = dataset.groupby(['island']).size() # plot the result sns.barplot(x = result.index, y = result.values)
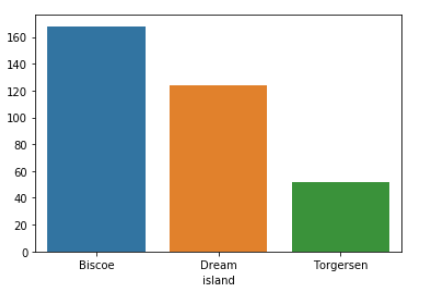
Parcela de tamaño usando
Seaborn
Publicación traducida automáticamente
Artículo escrito por clivefernandes777 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA