¿Qué es el umbral de decisión?
sklearn no nos permite establecer el umbral de decisión directamente, pero nos da acceso a las puntuaciones de decisión (función de decisión o/p) que se utiliza para hacer la predicción. Podemos seleccionar la mejor puntuación de la salida de la función de decisión y establecerla como valor de umbral de decisión y considerar todos los valores de puntuación de decisión que son inferiores a este umbral de decisión como una clase negativa (0) y todos los valores de puntuación de decisión que son superiores a esta decisión. Valor umbral como clase positiva ( 1 ).
Usando la curva de precisión-recuperación para varios valores de umbral de decisión, podemos seleccionar el mejor valor para el umbral de decisión de modo que proporcione alta precisión (sin afectar mucho a la recuperación) o alta recuperación (sin afectar mucho a la precisión) en función de si nuestro proyecto está orientado a la precisión. o orientados al recuerdo respectivamente.
El objetivo principal de hacer esto es obtener un modelo ML de alta precisión, o un modelo ML de alta recuperación, en función de si nuestro proyecto ML está orientado a la precisión o al recuerdo, respectivamente.
Código: código de Python para crear un modelo de aprendizaje automático de alta precisión
# Import required modules. import pandas as pd import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.svm import SVC from sklearn.metrics import classification_report, recall_score, precision_score, accuracy_score # Get the data. data_set = datasets.load_breast_cancer() # Get the data into an array form. x = data_set.data # Input feature x. y = data_set.target # Input target variable y. # Get the names of the features. feature_list = data_set.feature_names # Convert the data into pandas data frame. data_frame = pd.DataFrame(x, columns = feature_list) # To insert an output column in data_frame. data_frame.insert(30, 'Outcome', y) # Run this line only once for every new training. # Data Frame. data_frame.head(7)
Producción:
Código: entrenar el modelo
# Train Test Split. x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, random_state = 42) # Create Classifier Object. clf = SVC() clf.fit(x_train, y_train) # Use decision_function method. decision_function = clf.decision_function(x_test)
Puntajes reales obtenidos:
# Actual obtained results without any manual setting of Decision Threshold. predict_actual = clf.predict(x_test) # Predict using classifier. accuracy_actual = clf.score(x_test, y_test) classification_report_actual = classification_report(y_test, predict_actual) print(predict_actual, accuracy_actual, classification_report_actual, sep ='\n')
Producción: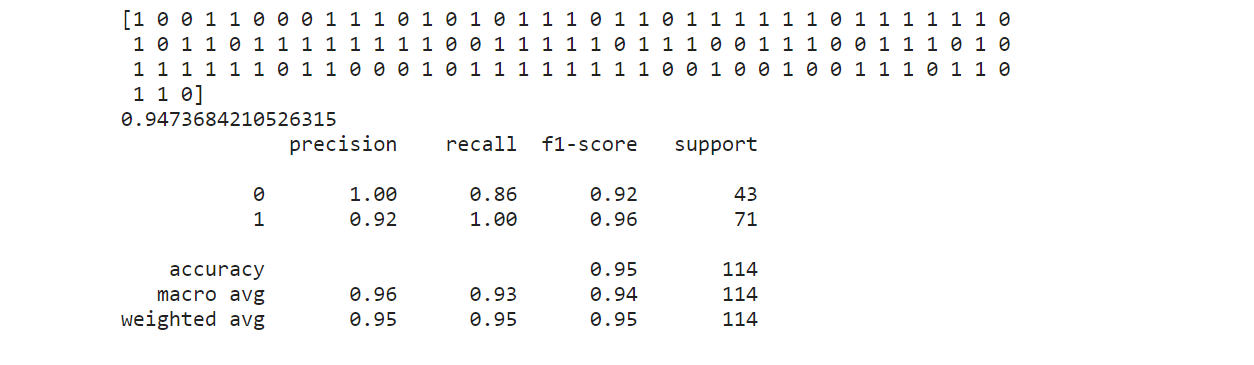
En el informe de clasificación anterior, podemos ver que el valor de precisión de nuestro modelo para (1) es 0,92 y el valor de recuperación para (1) es 1,00. Dado que nuestro objetivo en este artículo es construir un modelo ML de alta precisión para predecir (1) sin afectar mucho la recuperación, debemos seleccionar manualmente el mejor valor del valor de umbral de decisión de la siguiente curva de precisión-recuperación, para que podamos aumentar la precisión de este modelo.
Código:
# Plot Precision-Recall curve using sklearn.
from sklearn.metrics import precision_recall_curve
precision, recall, threshold = precision_recall_curve(y_test, decision_function)
# Plot the output.
plt.plot(threshold, precision[:-1], c ='r', label ='PRECISION')
plt.plot(threshold, recall[:-1], c ='b', label ='RECALL')
plt.grid()
plt.legend()
plt.title('Precision-Recall Curve')
Producción:
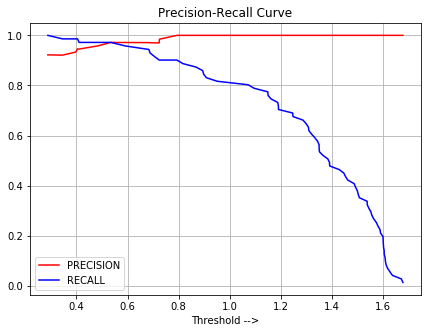
Aquí, en el gráfico anterior, podemos ver que si queremos un valor de alta precisión, entonces necesitamos aumentar el valor del umbral de decisión (eje x), pero esto disminuiría el valor de recuperación (que no es favorable). por lo tanto, debemos elegir ese valor de Umbral de decisión que aumentaría la Precisión pero no disminuiría mucho la Recuperación. Uno de esos valores del gráfico anterior es de alrededor de 0,6 Umbral de decisión.
Código:
# Implementing main logic. # Based on analysis of the Precision-Recall curve. # Let Decision Threshold value be around 0.6... to get high Precision without affecting recall much. # Desired results. # Decision Function output for x_test. df = clf.decision_function(x_test) # Set the value of decision threshold. decision_teshold = 0.5914643767268305 # Desired prediction to increase precision value. desired_predict =[] # Iterate through each value of decision function output # and if decision score is > than Decision threshold then, # append (1) to the empty list ( desired_prediction) else # append (0). for i in df: if i<decision_teshold: desired_predict.append(0) else: desired_predict.append(1)
Código: Comparación entre los valores de precisión antiguos y nuevos.
# Comparison
# Old Precision Value
print("old precision value:", precision_score(y_test, predict_actual))
# New precision Value
print("new precision value:", precision_score(y_test, desired_predict))
Producción:
old precision value: 0.922077922077922 new precision value: 0.9714285714285714
OBSERVACIONES:
- El valor de Precisión ha aumentado de 0,92 a 0,97.
- El valor de recuperación ha disminuido debido a la compensación de precisión-recuperación.
NOTA:
El código anterior no son datos preprocesados (limpieza de datos o ingeniería de características), lo que prolongaría este artículo. Esta es solo una idea de cómo utilizar Decision Threshold en la práctica.