El llamado formato CSV (Comma Separated Values) es el formato de importación y exportación más común para hojas de cálculo y bases de datos. Existieron varios formatos de CSV hasta su estandarización. La falta de un estándar bien definido significa que a menudo existen diferencias sutiles en los datos producidos y consumidos por diferentes aplicaciones. Estas diferencias pueden hacer que sea molesto procesar archivos CSV de múltiples fuentes. Para ese propósito, usaremos la biblioteca csv de Python para leer y escribir datos tabulares en formato CSV.
Para obtener un enlace al archivo CSV utilizado en el código, haga clic aquí .
Código #1: Usaremos la función csv.DictReader() para importar el archivo de datos al entorno de Python.
Python3
# importing the csv module
import csv
# Now let's read the file named 'auto-mpg.csv'
# After reading as a dictionary convert
# it to Python's list
with open('auto-mpg.csv') as csvfile:
mpg_data = list(csv.DictReader(csvfile))
# Let's visualize the data
# We are printing only first three elements
print(mpg_data[:3])
Producción :
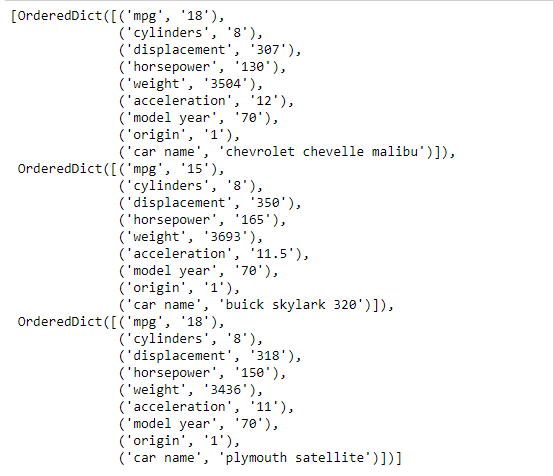
Como podemos ver, los datos se almacenan como una lista de diccionarios ordenados. Realicemos algunas operaciones en los datos para una mejor comprensión.
Código #2:
Python3
# Let's find all the keys in the dictionary print(mpg_data[0].keys) # Now we would like to find out the number of # unique values of cylinders in the car in our dataset # We create a set containing the cylinders value unique_cyl = set(data['cylinders'] for data in mpg_data) # Let's print the values print(unique_cyl)
Producción :
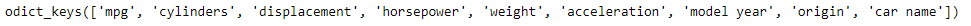
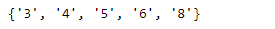
Como podemos ver en la salida, tenemos 5 valores únicos de cilindros en nuestro conjunto de datos.
Código #3: Ahora averigüemos el valor de mpg promedio para cada valor de cilindros.
Python3
# Let's create an empty list to store the values # of average mpg for each cylinder avg_mpg = [] # c is the current cylinder size for c in unique_cyl: # for storing the sum of mpg mpgbycyl = 0 # for storing the sum of cylinder # in each category cylcount = 0 # iterate over all the data in mpg for x in mpg_data: # Check if current value matches c if x['cylinders']== c: # Add the mpg values for c mpgbycyl += float(x['mpg']) # increment the count of cylinder cylcount += 1 # Find the average mpg for size c avg = mpgbycyl/cylcount # Append the average mpg to list avg_mpg.append((c, avg)) # Sort the list avg_mpg.sort(key = lambda x : x[0]) # Print the list print(avg_mpg)
Producción :
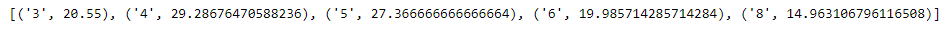
Como podemos ver en el resultado, el programa ha devuelto con éxito una lista de tuplas que contienen el promedio de millas por galón para cada tipo de cilindro único en nuestro conjunto de datos.
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA