Una serie de tiempo es la serie de puntos de datos enumerados en orden de tiempo. Una serie de tiempo es una secuencia de puntos sucesivos de intervalos iguales en el tiempo. Un análisis de series temporales consta de métodos para analizar datos de series temporales con el fin de extraer información significativa y otras características útiles de los datos. El análisis de datos de series temporales se está volviendo muy importante en muchas industrias, como las industrias financieras, farmacéuticas, empresas de redes sociales, proveedores de servicios web, investigación y muchas más. Para comprender los datos de series temporales, las visualizaciones son esenciales. Cualquier tipo de análisis de datos no está completo sin visualizaciones. Porque una buena visualización puede proporcionar información significativa e interesante sobre los datos.
Hacer cualquier tipo de conjunto de datos de análisis de datos es el requisito más importante y básico. Sin un conjunto de datos, no podemos realizar análisis. Aquí estamos tomando datos de stock para la visualización de datos de series temporales. Haga clic aquí para ver el conjunto de datos completo. Para visualizar datos de series temporales, necesitamos importar algunos paquetes:
Python3
import pandas as pd import numpy as np import matplotlib.pyplot as plt
Ahora cargando el conjunto de datos creando un marco de datos df.
Python3
# reading the dataset using read_csv
df = pd.read_csv("stock_data.csv",
parse_dates=True,
index_col="Date")
# displaying the first five rows of dataset
df.head()
Producción:
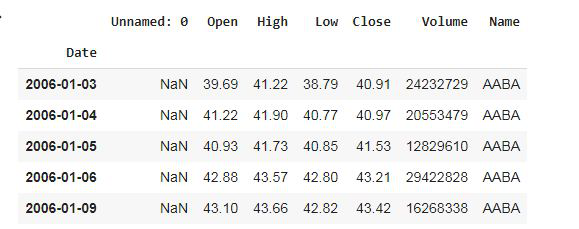
Hemos utilizado el parámetro ‘parse_dates’ en la función read_csv para convertir la columna ‘Date’ al formato DatetimeIndex. De forma predeterminada, las fechas se almacenan en formato de string, que no es el formato adecuado para el análisis de datos de series temporales.
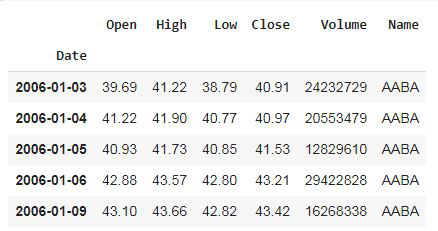
Ahora, eliminando las columnas no deseadas del marco de datos, es decir, ‘Sin nombre: 0’.
Python3
# deleting column df.drop(columns='Unnamed: 0')
Producción:
Ejemplo 1: Trazado de un diagrama de línea simple para datos de series de tiempo.
Python3
df['Volume'].plot()
Producción:
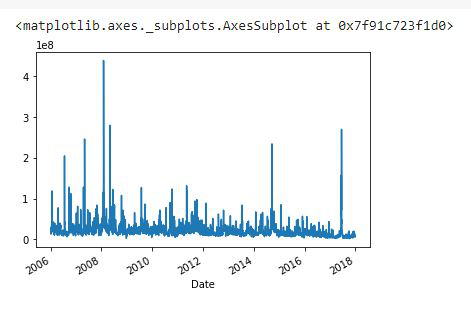
Aquí, hemos trazado los datos de la columna ‘Volumen’.
Ejemplo 2: ahora tracemos todas las demás columnas usando subplot.
Python3
df.plot(subplots=True, figsize=(10, 12))
Producción:
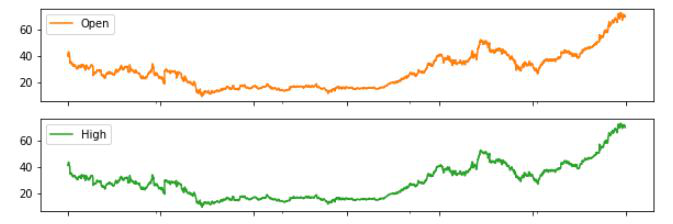
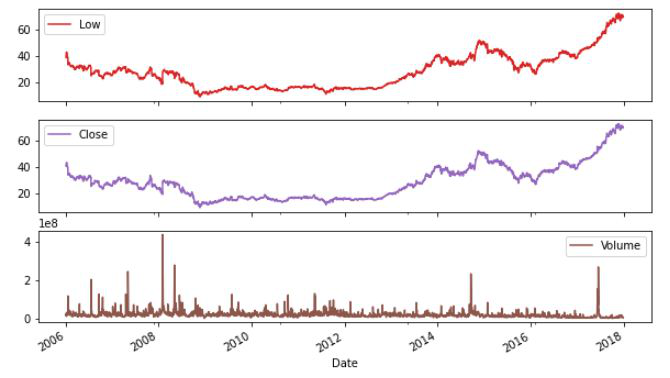
Los diagramas de líneas utilizados anteriormente son buenos para mostrar la estacionalidad.
Estacionalidad: en los datos de series de tiempo, la estacionalidad es la presencia de variaciones que ocurren en intervalos de tiempo regulares específicos de menos de un año, como semanales, mensuales o trimestrales.
Remuestreo : El remuestreo es una metodología de uso económico de una muestra de datos para mejorar la precisión y cuantificar la incertidumbre de un parámetro de población. Remuestrear durante meses o semanas y hacer diagramas de barras es otro método muy simple y ampliamente utilizado para encontrar la estacionalidad. Aquí vamos a hacer un gráfico de barras de datos mensuales para 2016 y 2017.
Ejemplo 3:
Python3
# Resampling the time series data based on monthly 'M' frequency
df_month = df.resample("M").mean()
# using subplot
fig, ax = plt.subplots(figsize=(10, 6))
# plotting bar graph
ax.bar(df_month['2016':].index,
df_month.loc['2016':, "Volume"],
width=25, align='center')
Producción:
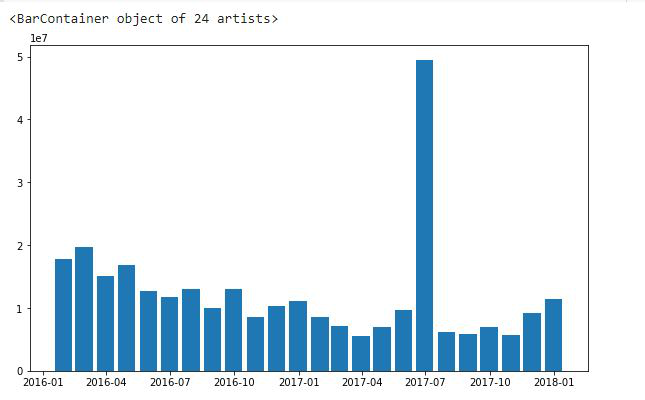
Hay 24 barras en el gráfico y cada barra representa un mes.
Diferenciación: la diferenciación se utiliza para hacer la diferencia en los valores de un intervalo específico. Por defecto, es uno, podemos especificar diferentes valores para las parcelas. Es el método más popular para eliminar tendencias en los datos.
Ejemplo 4:
Python3
df.Low.diff(2).plot(figsize=(10, 6))
Producción:
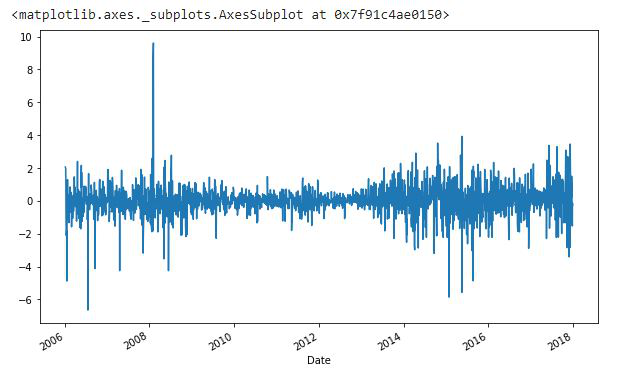
Python3
df.High.diff(2).plot(figsize=(10, 6))
Producción:
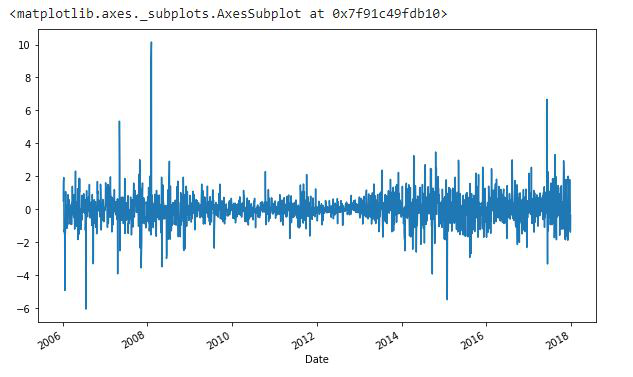
Trazado de los cambios en los datos
También podemos trazar los cambios que ocurrieron en los datos a lo largo del tiempo. Hay algunas formas de trazar cambios en los datos.
Desplazamiento: la función de desplazamiento se puede utilizar para desplazar los datos antes o después del intervalo de tiempo especificado. Podemos especificar la hora y cambiará los datos un día de forma predeterminada. Eso significa que obtendremos los datos del día anterior. Es útil ver los datos del día anterior y los datos de hoy simultáneamente uno al lado del otro.
Python3
df['Change'] = df.Close.div(df.Close.shift()) df['Change'].plot(figsize=(10, 8), fontsize=16)
En este código, la función .div() ayuda a completar los valores de datos que faltan. En realidad, div() significa división. Si tomamos df. div(6) dividirá cada elemento en df por 6. Hacemos esto para evitar los valores nulos o faltantes que son creados por la operación ‘shift()’.
Aquí, hemos tomado .div(df.Close.shift()), dividirá cada valor de df a df.Close.shift() para eliminar los valores nulos.
Producción:
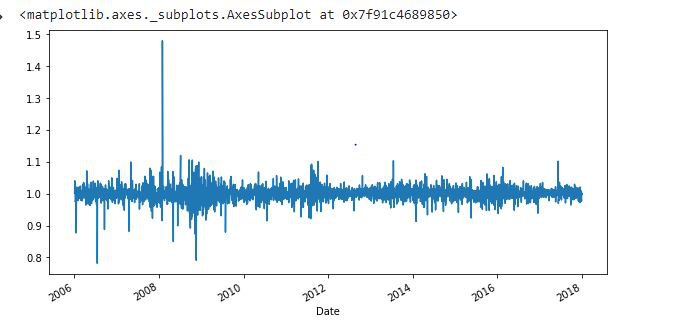
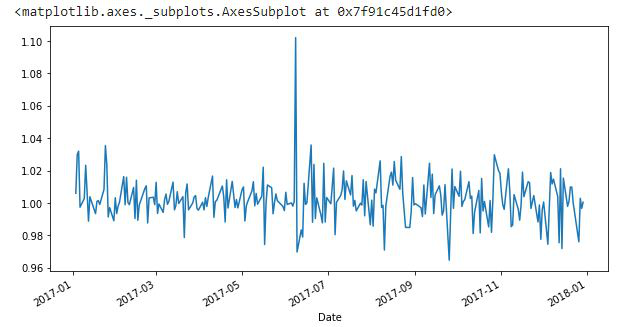
También podemos tomar un intervalo de tiempo específico y trazar para tener una visión más clara. Aquí estamos trazando los datos de solo 2017.
Python3
df['2017']['Change'].plot(figsize=(10, 6))
Producción:
Publicación traducida automáticamente
Artículo escrito por neelutiwari y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA