A veces, puede parecer más fácil analizar un conjunto de puntos de datos y generar conocimientos a partir de ellos, pero, por lo general, este proceso puede no generar buenos resultados. Podrían quedar muchas cosas sin descubrir como resultado de este proceso. Además, la mayoría de los conjuntos de datos utilizados en la vida real son demasiado grandes para realizar un análisis manual. Aquí es esencialmente donde interviene la visualización de datos.
La visualización de datos es una forma más fácil de presentar los datos, por complejos que sean, para analizar tendencias y relaciones entre variables con la ayuda de representaciones pictóricas.
Las siguientes son las ventajas de la visualización de datos
- Representación más fácil de los datos compels
- Destaca las áreas de buen y mal desempeño
- Explora la relación entre los puntos de datos
- Identifica patrones de datos incluso para puntos de datos más grandes
Al construir la visualización, siempre es una buena práctica tener en cuenta algunos de los puntos mencionados a continuación.
- Asegure el uso apropiado de formas, colores y tamaños mientras construye la visualización
- Los diagramas/gráficos que usan un sistema de coordenadas son más pronunciados
- El conocimiento de la trama adecuada con respecto a los tipos de datos aporta más claridad a la información.
- El uso de etiquetas, títulos, leyendas y punteros transmite información fluida a una audiencia más amplia
Bibliotecas de Python
Hay muchas bibliotecas de Python que podrían usarse para crear visualizaciones como matplotlib, vispy, bokeh, seaborn, pygal, folium, plotly, cufflinks y networkx . De los muchos, matplotlib y seaborn parecen ser muy utilizados para visualizaciones de nivel básico a intermedio.
matplotlib
Es una increíble biblioteca de visualización en Python para gráficos 2D de arrays. Es una biblioteca de visualización de datos multiplataforma basada en arrays NumPy y diseñada para funcionar con la pila SciPy más amplia. Fue presentado por John Hunter en el año 2002. Tratemos de entender algunos de los beneficios y características de matplotlib.
- Es rápido, eficiente ya que se basa en numpy y también es más fácil de construir .
- Ha experimentado muchas mejoras de la comunidad de código abierto desde el inicio y, por lo tanto, una mejor biblioteca que también tiene funciones avanzadas.
- La salida de visualización bien mantenida con gráficos de alta calidad atrae a muchos usuarios.
- Los gráficos básicos y avanzados se pueden construir muy fácilmente.
- Desde el punto de vista de los usuarios/desarrolladores, dado que tiene un gran apoyo de la comunidad, la resolución de problemas y la depuración se vuelven mucho más fáciles.
nacido en el mar
Conceptualizada y construida originalmente en la Universidad de Stanford, esta biblioteca se encuentra sobre matplotlib . En cierto sentido, tiene algunos sabores de matplotlib mientras que, desde el punto de vista de la visualización, es mucho mejor que matplotlib y también tiene funciones adicionales. A continuación se muestran sus ventajas.
- Los temas incorporados ayudan a una mejor visualización
- Funciones estadísticas que ayudan a comprender mejor los datos
- Mejor estética y tramas integradas
- Documentación útil con ejemplos efectivos
Naturaleza de la visualización
Según la cantidad de variables utilizadas para trazar la visualización y el tipo de variables, podría haber diferentes tipos de gráficos que podríamos usar para comprender la relación. Basándonos en el recuento de variables, podríamos tener
- Gráfica univariada (involucra solo una variable)
- Gráfica bivariada (se requiere más de una variable)
Una gráfica univariada podría ser para una variable continua para comprender la dispersión y distribución de la variable, mientras que para una variable discreta podría decirnos el conteo.
De manera similar, un gráfico bivariado para una variable continua podría mostrar una estadística esencial como la correlación, ya que una variable continua versus una variable discreta podría llevarnos a conclusiones muy importantes, como comprender la distribución de datos en diferentes niveles de una variable categórica. También se podría desarrollar una gráfica bivariada entre dos variables discretas.
diagrama de caja
Un diagrama de caja, también conocido como diagrama de caja y bigotes, el cuadro y el bigote se muestran claramente en la imagen a continuación. Es una muy buena representación visual cuando se trata de medir la distribución de datos. Traza claramente los valores medianos, los valores atípicos y los cuartiles. Comprender la distribución de datos es otro factor importante que conduce a una mejor construcción de modelos. Si los datos tienen valores atípicos, el diagrama de caja es una forma recomendada de identificarlos y tomar las medidas necesarias.
Sintaxis: seaborn.boxplot(x=Ninguno, y=Ninguno, hue=Ninguno, data=Ninguno, order=Ninguno, hue_order=Ninguno, orient=Ninguno, color=Ninguno, palette=Ninguno, saturación=0.75, ancho=0.8, dodge=True, fliersize=5, linewidth=Ninguno, whis=1.5, ax=Ninguno, **kwargs)
Parámetros:
x, y, hue: Entradas para trazar datos de formato largo.
datos: conjunto de datos para el trazado. Si x e y están ausentes, esto se interpreta como formato ancho.
color: Color para todos los elementos.Devoluciones: Devuelve el objeto Axes con la trama dibujada en él.
El gráfico de caja y bigotes muestra cómo se distribuyen los datos. En general, se incluyen cinco piezas de información en el gráfico.
- El mínimo se muestra en el extremo izquierdo del gráfico, al final del ‘bigotes’ izquierdo
- El primer cuartil, Q1, es el extremo izquierdo de la caja (bigotes izquierdos)
- La mediana se muestra como una línea en el centro de la caja.
- Tercer cuartil, Q3, que se muestra en el extremo derecho del cuadro (bigot derecho)
- El máximo está en el extremo derecho de la caja.
Como se puede ver en las siguientes representaciones y gráficos, se puede trazar un diagrama de caja para una o más de una variable, lo que proporciona una muy buena perspectiva de nuestros datos.
Representación de diagrama de caja.
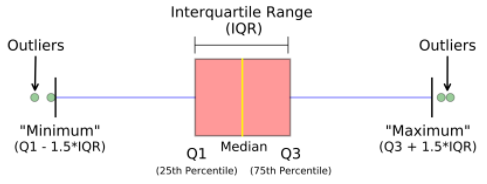
Diagrama de caja que representa variables categóricas de múltiples variables
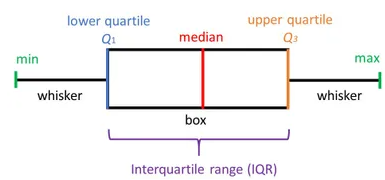
Diagrama de caja que representa variables categóricas de múltiples variables
Python3
# import required modules import matplotlib as plt import seaborn as sns # Box plot and violin plot for Outcome vs BloodPressure _, axes = plt.subplots(1, 2, sharey=True, figsize=(10, 4)) # box plot illustration sns.boxplot(x='Outcome', y='BloodPressure', data=diabetes, ax=axes[0]) # violin plot illustration sns.violinplot(x='Outcome', y='BloodPressure', data=diabetes, ax=axes[1])
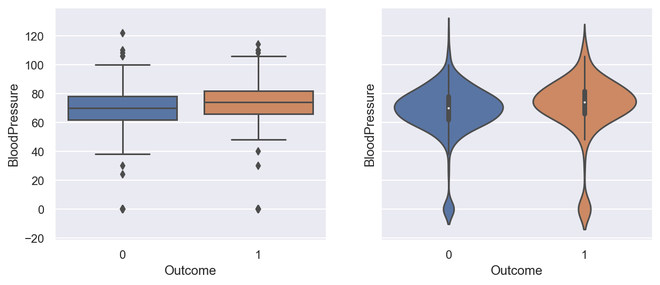
Salida para Box Plot y Violin Plot
Python3
# Box plot for all the numerical variables
sns.set(rc={'figure.figsize': (16, 5)})
# multiple box plot illustration
sns.boxplot(data=diabetes.select_dtypes(include='number'))
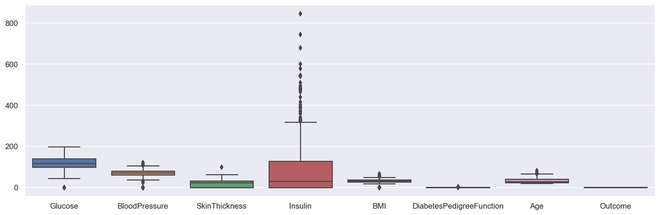
Gráfica de caja múltiple de salida
Gráfico de dispersión
Los diagramas de dispersión o gráficos de dispersión son diagramas bivariados que se parecen más a los gráficos de líneas en la forma en que se construyen. Un gráfico de líneas usa una línea en un eje XY para trazar una función continua, mientras que un gráfico de dispersión se basa en puntos para representar datos individuales. Estos gráficos son muy útiles para ver si dos variables están correlacionadas. El diagrama de dispersión puede ser bidimensional o tridimensional.
Sintaxis: seaborn.scatterplot(x=Ninguno, y=Ninguno, hue=Ninguno, estilo=Ninguno, tamaño=Ninguno, datos=Ninguno, palette=Ninguno, hue_order=Ninguno, hue_norm=Ninguno, tamaños=Ninguno, size_order=Ninguno, size_norm=Ninguno, marcadores=Verdadero, style_order=Ninguno, x_bins=Ninguno, y_bins=Ninguno, unidades=Ninguno, estimador=Ninguno, ci=95, n_boot=1000, alpha=’auto’, x_jitter=Ninguno, y_jitter=Ninguno, legend=’brief’, ax=Ninguno, **kwargs)
Parámetros:
x, y: Variables de datos de entrada que deben ser numéricas.datos : marco de datos donde cada columna es una variable y cada fila es una observación.
size : Variable de agrupación que producirá puntos con diferentes tamaños.
estilo : variable de agrupación que producirá puntos con diferentes marcadores.
paleta : variable de agrupación que producirá puntos con diferentes marcadores.
marcadores : Objeto que determina cómo dibujar los marcadores para diferentes niveles.
alfa : Opacidad proporcional de los puntos.
Devoluciones: este método devuelve el objeto Axes con el gráfico dibujado en él.
Ventajas de un diagrama de dispersión
- Muestra la correlación entre las variables
- Adecuado para grandes conjuntos de datos
- Más fácil de encontrar grupos de datos
- Mejor representación de cada punto de datos
Python3
# import module import matplotlib.pyplot as plt # scatter plot illustration plt.scatter(diabetes['DiabetesPedigreeFunction'], diabetes['BMI'])
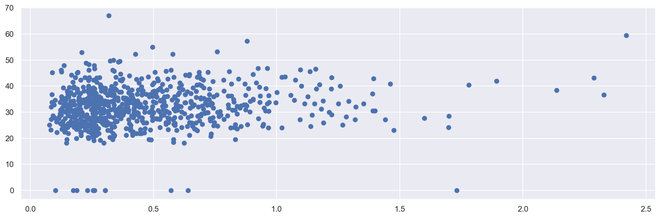
Gráfico disperso 2D de salida
Python3
# import required modules
from mpl_toolkits.mplot3d import Axes3D
# assign axis values
x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
y = [5, 6, 2, 3, 13, 4, 1, 2, 4, 8]
z = [2, 3, 3, 3, 5, 7, 9, 11, 9, 10]
# adjust size of plot
sns.set(rc={'figure.figsize': (8, 5)})
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(x, y, z, c='r', marker='o')
# assign labels
ax.set_xlabel('X Label'), ax.set_ylabel('Y Label'), ax.set_zlabel('Z Label')
# display illustration
plt.show()
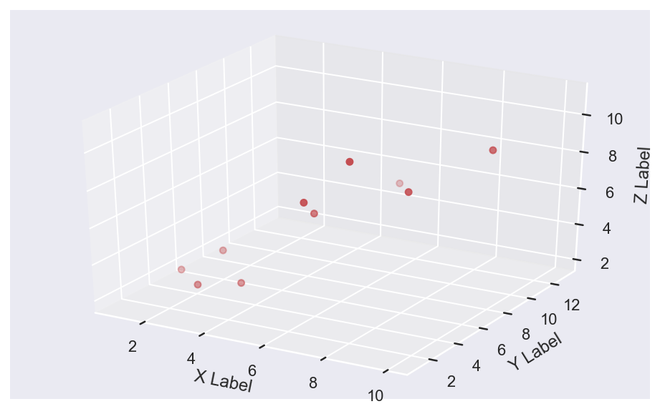
Gráfico disperso 3D de salida
Histograma
Los histogramas muestran recuentos de datos y, por lo tanto, son similares a un gráfico de barras. Un gráfico de histograma también puede decirnos qué tan cerca está una distribución de datos de una curva normal. Al trabajar con el método estadístico, es muy importante que tengamos datos que sean normales o cercanos a una distribución normal. Sin embargo, los histogramas son de naturaleza univariada y los gráficos de barras bivariados .
Un gráfico de barras traza los conteos reales contra las categorías, por ejemplo, la altura de la barra indica el número de artículos en esa categoría, mientras que un histograma muestra las mismas variables categóricas en contenedores .
Los contenedores son una parte integral mientras construyen un histograma, controlan los puntos de datos que están dentro de un rango. Como opción ampliamente aceptada, generalmente limitamos el contenedor a un tamaño de 5 a 20; sin embargo, esto se rige totalmente por los puntos de datos presentes.
Python3
# illustrate histogram features = ['BloodPressure', 'SkinThickness'] diabetes[features].hist(figsize=(10, 4))
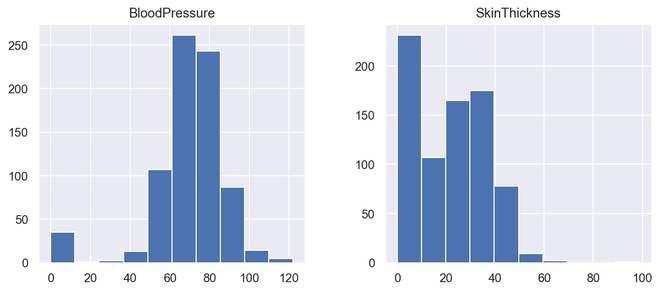
Histograma de salida
conteo
Una gráfica de conteo es una gráfica entre una variable categórica y una continua. La variable continua en este caso es el número de veces que el categórico está presente o simplemente la frecuencia. En cierto sentido, se puede decir que el gráfico de conteo está estrechamente relacionado con un histograma o un gráfico de barras.
Sintaxis: seaborn.countplot(x=Ninguno, y=Ninguno, hue=Ninguno, data=Ninguno, order=Ninguno, hue_order=Ninguno, orient=Ninguno, color=Ninguno, palette=Ninguno, saturación=0.75, dodge=True, ax=Ninguno, **kwargs)
Parámetros: este método acepta los siguientes parámetros que se describen a continuación:
- x, y: Este parámetro toma nombres de variables en datos o datos vectoriales, opcional, Entradas para graficar datos de formato largo.
- matiz: (opcional) Este parámetro toma el nombre de la columna para la codificación de colores.
- datos: (opcional) este parámetro toma DataFrame, array o lista de arrays, conjunto de datos para trazar. Si x e y están ausentes, esto se interpreta como formato ancho. De lo contrario, se espera que sea de formato largo.
- order, hue_order : (opcional) Este parámetro toma listas de strings. Orden para trazar los niveles categóricos; de lo contrario, los niveles se deducen de los objetos de datos.
- orient : (opcional)Este parámetro toma “v” | “h”, Orientación de la parcela (vertical u horizontal). Por lo general, esto se deduce del dtype de las variables de entrada, pero se puede usar para especificar cuándo la variable «categórica» es numérica o cuando se grafican datos de formato ancho.
- color : (opcional) Este parámetro toma matplotlib color, Color para todos los elementos o semilla para una paleta de degradado.
- paleta: (opcional) Este parámetro toma el nombre de la paleta, lista o dictado, Colores para usar para los diferentes niveles de la variable de tono. Debería ser algo que pueda ser interpretado por color_palette(), o un diccionario que mapee los niveles de tono a los colores matplotlib.
- saturación: (opcional) Este parámetro toma valor flotante, proporción de la saturación original para dibujar colores. Los parches grandes a menudo se ven mejor con colores ligeramente desaturados, pero establezca esto en 1 si desea que los colores de la trama coincidan perfectamente con la especificación de color de entrada.
- dodge: (opcional) este parámetro toma valor bool, cuando se usa el anidamiento de tonos, si los elementos deben desplazarse a lo largo del eje categórico.
- hacha: (opcional) este parámetro toma matplotlib Axes, el objeto Axes para dibujar el gráfico, de lo contrario, usa los ejes actuales.
- kwargs: este parámetro toma la clave, las asignaciones de valores, otros argumentos de palabras clave se pasan a través de matplotlib.axes.Axes.bar().
Devoluciones: devuelve el objeto Axes con el gráfico dibujado en él.
Simplemente muestra el número de apariciones de un elemento en función de un determinado tipo de categoría. En Python, podemos crear un complot utilizando la biblioteca Seaborn . Seaborn es un módulo en Python que se basa en matplotlib y se usa para gráficos estadísticos visualmente atractivos.
Python3
# import required module import seaborn as sns # assign required values _, axes = plt.subplots(nrows=1, ncols=2, figsize=(12, 4)) # illustrate count plots sns.countplot(x='Outcome', data=diabetes, ax=axes[0]) sns.countplot(x='BloodPressure', data=diabetes, ax=axes[1])
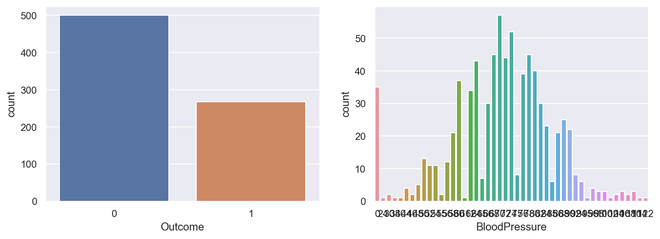
Gráfico de conteo de salida
Gráfica de correlación
El gráfico de correlación es un análisis de múltiples variables que resulta muy útil para observar la relación con los puntos de datos. Los diagramas de dispersión ayudan a comprender el efecto de una variable sobre la otra. La correlación se podría definir como el efecto que tiene una variable sobre otra.
La correlación podría calcularse entre dos variables o también podría ser una versus muchas correlaciones, que podríamos ver en el gráfico a continuación. La correlación puede ser positiva, negativa o neutra y el rango matemático de correlaciones es de -1 a 1. Comprender la correlación podría tener un efecto muy significativo en la etapa de construcción del modelo y también en la comprensión de los resultados del modelo.
Python3
# Finding and plotting the correlation for
# the independent variables
# import required module
import seaborn as sns
# adjust plot
sns.set(rc={'figure.figsize': (14, 5)})
# assign data
ind_var = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM',
'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT']
# illustrate heat map.
sns.heatmap(diabetes.select_dtypes(include='number').corr(),
cmap=sns.cubehelix_palette(20, light=0.95, dark=0.15))
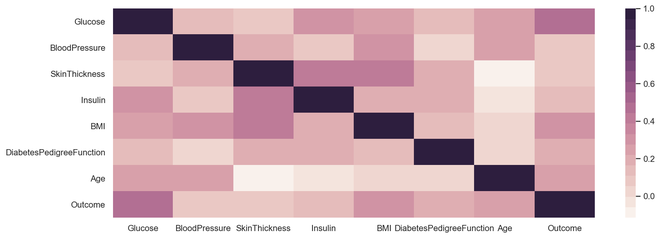
Gráfica de correlación de salida
Mapas de calor
El mapa de calor es una representación de datos de múltiples variables. La intensidad del color en las pantallas de un mapa de calor se convierte en un factor importante para comprender el efecto de los puntos de datos. Los mapas de calor son más fáciles de entender y de explicar también. Cuando se trata de análisis de datos mediante visualización, es muy importante que el mensaje deseado se transmita con la ayuda de gráficos.
Sintaxis:
seaborn.heatmap( data , * , vmin=Ninguno , vmax=Ninguno , cmap=Ninguno , center=Ninguno , robusto=Falso , annot=Ninguno , fmt=’.2g’ , annot_kws=Ninguno , linewidths=0 , linecolor=’ white’ , cbar=True , cbar_kws=Ninguno , cbar_ax=Ninguno , square=False , xticklabels=’auto’ , yticklabels=’auto’ , mask=Ninguno , ax=Ninguno , **kwargs )
Parámetros: este método acepta los siguientes parámetros que se describen a continuación:
- x, y: Este parámetro toma nombres de variables en datos o datos vectoriales, opcional, Entradas para graficar datos de formato largo.
- matiz: (opcional) Este parámetro toma el nombre de la columna para la codificación de colores.
- datos: (opcional) este parámetro toma DataFrame, array o lista de arrays, conjunto de datos para trazar. Si x e y están ausentes, esto se interpreta como formato ancho. De lo contrario, se espera que sea de formato largo.
- color : (opcional) Este parámetro toma matplotlib color, Color para todos los elementos o semilla para una paleta de degradado.
- paleta: (opcional) Este parámetro toma el nombre de la paleta, lista o dictado, Colores para usar para los diferentes niveles de la variable de tono. Debería ser algo que pueda ser interpretado por color_palette(), o un diccionario que mapee los niveles de tono a los colores matplotlib.
- hacha: (opcional) este parámetro toma matplotlib Axes, el objeto Axes para dibujar el gráfico, de lo contrario, usa los ejes actuales.
- kwargs: este parámetro toma la clave, las asignaciones de valores, otros argumentos de palabras clave se pasan a través de matplotlib.axes.Axes.bar().
Devoluciones: devuelve el objeto Axes con el gráfico dibujado en él.
Python3
# import required module import seaborn as sns import numpy as np # assign data data = np.random.randn(50, 20) # illustrate heat map ax = sns.heatmap(data, xticklabels=2, yticklabels=False)
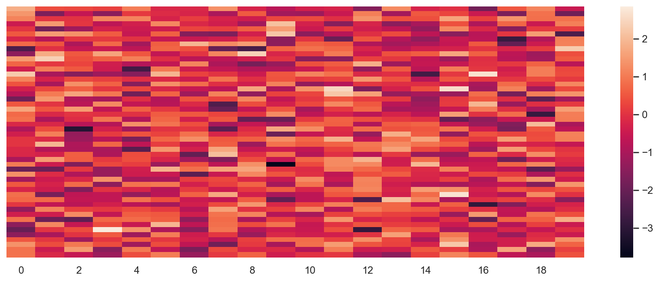
Mapa de calor de salida
Gráfico circular
El gráfico circular es un análisis univariado y normalmente se usa para mostrar datos porcentuales o proporcionales. La distribución porcentual de cada clase en una variable se proporciona junto a la porción correspondiente del pastel. Las bibliotecas de python que podrían usarse para construir un gráfico circular son matplotlib y seaborn.
Sintaxis: matplotlib.pyplot.pie(datos, explotar=Ninguno, etiquetas=Ninguno, colores=Ninguno, autopct=Ninguno, sombra=Falso)
Parámetros:
data representa la array de valores de datos que se trazarán, el área fraccionaria de cada sector se representa mediante data/sum(data) . Si sum(data)<1, entonces los valores de datos devuelven el área fraccionaria directamente, por lo que el pastel resultante tendrá una cuña vacía de tamaño 1-sum(data).
etiquetas es una lista de secuencias de strings que establece la etiqueta de cada cuña.
El atributo de color se utiliza para dar color a las cuñas.
autopct es una string que se usa para etiquetar la cuña con su valor numérico.
shadow se utiliza para crear una sombra de cuña.
A continuación se muestran las ventajas de un gráfico circular.
- Resumen visual más fácil de grandes puntos de datos
- El efecto y el tamaño de las diferentes clases se pueden entender fácilmente.
- Los puntos porcentuales se utilizan para representar las clases en los puntos de datos.
Python3
# import required module import matplotlib.pyplot as plt # Creating dataset cars = ['AUDI', 'BMW', 'FORD', 'TESLA', 'JAGUAR', 'MERCEDES'] data = [23, 17, 35, 29, 12, 41] # Creating plot fig = plt.figure(figsize=(10, 7)) plt.pie(data, labels=cars) # Show plot plt.show()
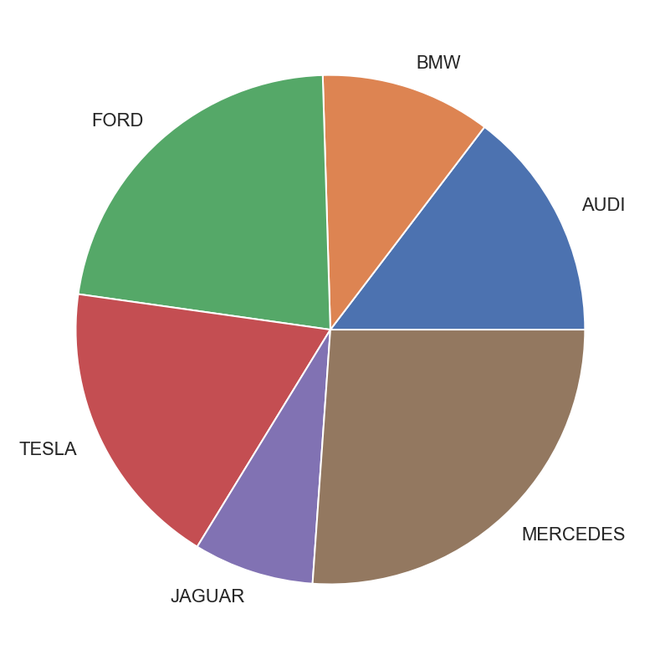
Gráfico circular de salida
Python3
# Import required module
import matplotlib.pyplot as plt
import numpy as np
# Creating dataset
cars = ['AUDI', 'BMW', 'FORD', 'TESLA', 'JAGUAR', 'MERCEDES']
data = [23, 17, 35, 29, 12, 41]
# Creating explode data
explode = (0.1, 0.0, 0.2, 0.3, 0.0, 0.0)
# Creating color parameters
colors = ("orange", "cyan", "brown", "grey", "indigo", "beige")
# Wedge properties
wp = {'linewidth': 1, 'edgecolor': "green"}
# Creating autocpt arguments
def func(pct, allvalues):
absolute = int(pct / 100.*np.sum(allvalues))
return "{:.1f}%\n({:d} g)".format(pct, absolute)
# Creating plot
fig, ax = plt.subplots(figsize=(10, 7))
wedges, texts, autotexts = ax.pie(data, autopct=lambda pct: func(pct, data), explode=explode, labels=cars,
shadow=True, colors=colors, startangle=90, wedgeprops=wp,
textprops=dict(color="magenta"))
# Adding legend
ax.legend(wedges, cars, title="Cars", loc="center left",
bbox_to_anchor=(1, 0, 0.5, 1))
plt.setp(autotexts, size=8, weight="bold")
ax.set_title("Customizing pie chart")
# Show plot
plt.show()
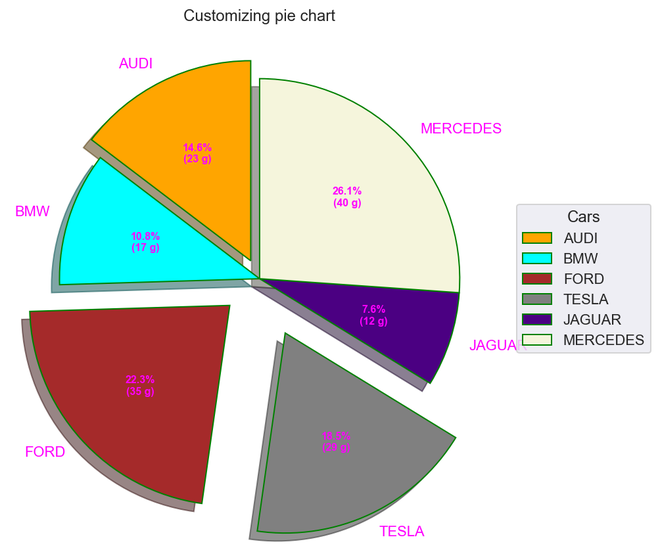
Producción
Barras de error
Las barras de error podrían definirse como una línea que pasa por un punto en un gráfico, paralela a uno de los ejes, que representa la incertidumbre o error de la coordenada correspondiente del punto. Este tipo de gráficos son muy útiles para comprender y analizar las desviaciones del objetivo. Una vez que se identifican los errores, podría conducir fácilmente a un análisis más profundo de los factores que los causan.
- La desviación de los puntos de datos del umbral podría capturarse fácilmente
- Captura fácilmente las desviaciones de un conjunto más grande de puntos de datos
- Define los datos subyacentes.
Python3
# Import required module
import matplotlib.pyplot as plt
import numpy as np
# Assign axes
x = np.linspace(0,5.5,10)
y = 10*np.exp(-x)
# Assign errors regarding each axis
xerr = np.random.random_sample(10)
yerr = np.random.random_sample(10)
# Adjust plot
fig, ax = plt.subplots()
ax.errorbar(x, y, xerr=xerr, yerr=yerr, fmt='-o')
# Assign labels
ax.set_xlabel('x-axis'), ax.set_ylabel('y-axis')
ax.set_title('Line plot with error bars')
# Illustrate error bars
plt.show()
Gráfico de error de salida
Publicación traducida automáticamente
Artículo escrito por digitarun27 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA