El web scraping es una tarea que normalmente se realiza para extraer datos estructurados de los sitios web que luego se almacenan en consecuencia, este tipo de datos es lo suficientemente valioso como para abrir las puertas a una variedad de campos, desde cosas relacionadas con la minería de datos hasta aplicaciones relacionadas con la ciencia de datos donde Se requieren grandes cantidades de datos para tomar decisiones comerciales.
Y en cuanto a este artículo, vamos a discutir cómo usar web scrapers para extraer correos electrónicos basados en palabras clave y ubicaciones.
Entonces surge la pregunta, ¿por qué necesitaríamos algo así? Bueno, los correos electrónicos extraídos en función de temas y regiones específicos pueden ser una forma muy productiva de hacer publicidad y promoción de productos, aunque uno diría que esto podría usarse para black hat SEO, en realidad depende de cómo lo use.
Requisitos:
- Módulo Scrapy: se utiliza como un marco de trabajo de Python para el desguace web. Obtener datos de un sitio web normal es más fácil y se puede lograr simplemente extrayendo HTML del sitio web y obteniendo datos filtrando etiquetas. Se puede instalar usando el siguiente comando.
pip install scrapy
- Módulo Selenium: Es una poderosa herramienta para controlar un navegador web a través del programa. Es funcional para todos los navegadores, funciona en todos los principales sistemas operativos y sus scripts están escritos en varios idiomas, es decir, Python, Java, C#, etc. Se puede instalar con el siguiente comando.
pip install selenium
- Módulo Scrapy-Selenium: Es un middleware scrapy para manejar páginas JavaScript usando selenium . Se puede instalar usando el siguiente comando.
pip install scrapy-selenium
- Módulo de Google: al usar el paquete google de python, podemos obtener el resultado de la búsqueda de google a partir de un script de python. Se puede instalar usando el siguiente comando.
pip install google
Enfoque paso a paso:
Paso 1: crear un proyecto scrapy con el siguiente comando:
scrapy startproject email_extraction
Después de ejecutar el comando anterior, verá una carpeta con el árbol como este
├── email_extraction │ ├── __init__.py │ ├── items.py │ ├── middlewares.py │ ├── pipelines.py │ ├── __pycache__ │ ├── settings.py │ └── spiders │ ├── email_extractor.py │ ├── __init__.py │ └── __pycache__ └── scrapy.cfg 4 directories, 8 files
Cree un archivo python en el directorio de arañas y ábralo en cualquier editor.
Paso 2: Importación de las bibliotecas requeridas
Python3
# import required modules import scrapy from scrapy.spiders import CrawlSpider, Request from googlesearch import search import re from scrapy_selenium import SeleniumRequest from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC
Ahora que se han importado las bibliotecas requeridas, podemos pasar al siguiente paso de nuestro script.
Paso 3: Configuración de los parámetros necesarios para el rastreador
Python3
# create class to extract email ids class email_extractor(CrawlSpider): # adjusting parameters name = 'email_ex' def __init__(self, *args, **kwargs): super(email_extractor, self).__init__(*args, **kwargs) self.email_list = [] self.query = " 'market places'.gmail.com "
En esto, estamos creando la clase email_extractor y heredando la clase CrawlSpider del módulo scrapy , en la siguiente línea le estamos dando un nombre único a nuestro rastreador que usaremos más adelante para ejecutar nuestra araña, no necesitamos establecer el parámetro de dominio permitido como estaremos saltando de un dominio de sitio web a otro para extraer correos electrónicos, luego estamos creando un constructor de python y declarando una lista y una variable de string, el valor de string dado aquí se enviará al motor de búsqueda de Google, que es nuestra consulta real definición de palabra clave (salud), ubicación (EE. UU.) y .gmail.com para obtener resultados de búsqueda orientados al correo electrónico.
Paso 4: Obtener resultados y enviar requests
Python3
# sending requests def start_requests(self): for results in search(self.query, num=10, stop=None, pause=2): yield SeleniumRequest( url=results, callback=self.parse, wait_until=EC.presence_of_element_located( (By.TAG_NAME, "html")), dont_filter=True )
Aquí, estamos creando nuestro método start_requests y luego estamos usando el método search() del módulo googlesearch con parámetros de
- variable de consulta que tiene la consulta de búsqueda real que declaramos antes.
- 10 resultados después de cada 2 segundos de pausa.
- Obtenemos todos los resultados que existen para la consulta con el parámetro de parada establecido en Ninguno.
Después de eso, estamos generando una solicitud con el método SeleniumRequest del módulo scrapy_selenium con parámetros de:
- Obtener la primera URL de forma secuencial a partir de los resultados de búsqueda.
- Recuperar un método para cada URL para su posterior procesamiento, que veremos en un minuto.
- Usando el parámetro wait_until para verificar si la etiqueta con el nombre html apareció en la página web o no, seguirá verificando hasta que aparezca en la página web.
- Don’t_filter establecido como True permitirá volver a visitar el sitio web con el mismo nombre de dominio.
Paso 5: Extraer correos electrónicos de la página principal de cada sitio web
Python3
# extracting emails
def parse(self, response):
EMAIL_REGEX = r'[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+'
emails = re.finditer(EMAIL_REGEX, str(response.text))
for email in emails:
self.email_list.append(email.group())
for email in set(self.email_list):
yield{
"emails": email
}
self.email_list.clear()
En este paso estamos creando un método llamado parse()con la respuesta del parámetro para obtener el objeto de solicitud del método start_request , en la siguiente línea estamos creando nuestro sistema de expresión regular para analizar los correos electrónicos del HTML de respuesta, luego agregamos los correos electrónicos en la variable de lista lista_correo electrónico que declaramos en el constructor y luego estamos iterando sobre el conjunto y produciendo un diccionario donde los correos electrónicos son la clave o el encabezado de la columna y el correo electrónico es un iterador o un valor de correo electrónico relativo y, al final, estamos limpiando la lista para que no se escriban valores duplicados en el archivo. cuando arrancamos el rastreador.
A continuación se muestra el programa completo basado en el enfoque anterior:
Python3
# import required modules
import scrapy
from scrapy.spiders import CrawlSpider, Request
from googlesearch import search
import re
from scrapy_selenium import SeleniumRequest
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
# create class to extract email ids
class email_extractor(CrawlSpider):
# adjusting parameters
name = 'email_ex'
def __init__(self, *args, **kwargs):
super(email_extractor, self).__init__(*args, **kwargs)
self.email_list = []
self.query = " 'market places'.gmail.com "
# sending requests
def start_requests(self):
for results in search(self.query, num=10, stop=None, pause=2):
yield SeleniumRequest(
url=results,
callback=self.parse,
wait_until=EC.presence_of_element_located(
(By.TAG_NAME, "html")),
dont_filter=True
)
# extracting emails
def parse(self, response):
EMAIL_REGEX = r'[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+'
emails = re.finditer(EMAIL_REGEX, str(response.text))
for email in emails:
self.email_list.append(email.group())
for email in set(self.email_list):
yield{
"emails": email
}
self.email_list.clear()
Ahora es el momento de ejecutar el código, abra la terminal y vaya al directorio raíz del proyecto donde se encuentra el archivo scrapy.cfg y ejecute este comando:
scrapy crawl email_ex -o emails.csv
Scraper comenzará a extraer y almacenar todos los correos electrónicos en el archivo emails.csv que se crea automáticamente.
Y así los resultados son:
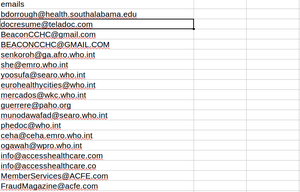
Los correos electrónicos extraídos se almacenan en un archivo csv
Publicación traducida automáticamente
Artículo escrito por ahmadwaqar y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA