Una de las cosas más importantes en el campo de la ciencia de datos es la habilidad de obtener los datos correctos para el problema que desea resolver. Los científicos de datos no siempre tienen una base de datos preparada para trabajar, sino que tienen que extraer datos de las fuentes correctas. Para ello se utilizan APIs y Web Scraping.
- API (interfaz de programa de aplicación) : una API es un conjunto de métodos y herramientas que permite consultar y recuperar datos de forma dinámica. Reddit, Spotify, Twitter, Facebook y muchas otras empresas ofrecen API gratuitas que permiten a los desarrolladores acceder a la información que almacenan en sus servidores; otros cobran por acceder a sus API.
- Web Scraping : no se puede acceder a una gran cantidad de datos a través de conjuntos de datos o API, sino que existen en Internet como páginas web. Entonces, a través del web-scraping, uno puede acceder a los datos sin esperar a que el proveedor cree una API.
¿Qué es Web Scraping?
El raspado web es una técnica para obtener datos de sitios web. Mientras navega por la web, muchos sitios web no permiten que el usuario guarde datos para uso privado. Una forma es copiar y pegar manualmente los datos, lo cual es tedioso y requiere mucho tiempo. Web Scraping es el proceso automático de extracción de datos de sitios web. Este proceso se realiza con la ayuda de un software de web scraping conocido como web scrapers. Cargan y extraen automáticamente datos de los sitios web según los requisitos del usuario. Estos se pueden crear a medida para que funcionen en un sitio o se pueden configurar para que funcionen con cualquier sitio web.
Implementación de Web Scraping usando R
Existen varias herramientas de raspado web para realizar la tarea y también varios idiomas, con bibliotecas que admiten el raspado web. Entre todos estos lenguajes, R se considera como uno de los lenguajes de programación para Web Scraping debido a características como: una biblioteca rica, fácil de usar, tipado dinámicamente, etc. La herramienta de Web Scraping comúnmente utilizada para R es rvest .
Instale el paquete rvest en su R Studio usando el siguiente código.
install.packages('rvest')
Tener conocimientos de HTML y CSS será una ventaja añadida. Se observa que la mayoría de los Data Scientists no están muy familiarizados con los conocimientos técnicos de HTML y CSS. Por lo tanto, usemos un software de código abierto llamado Selector Gadget que será más que suficiente para que cualquier persona pueda realizar Web scraping. Se puede acceder y descargar la extensión Selector Gadget (https://selectorgadget.com/). Considere que uno tiene esta extensión instalada siguiendo las instrucciones del sitio web. Además, considere uno que use Google Chrome y él / ella puede acceder a la extensión en la barra de extensión en la parte superior derecha.
Web Scraping en R con rvest
rvest mantenido por el legendario Hadley Wickham. Podemos extraer fácilmente datos de la página web de esta biblioteca.
Importar bibliotecas rvest
Antes de comenzar, importaremos la biblioteca rvest a su código.
R
library(rvest)
Leer código HTML
Lea el código HTML de la página web usando read_html() . Considere esta página web.
R
webpage = read_html("https://www.geeksforgeeks.org /\
data-structures-in-r-programming")
Extraer datos del código HTML
Ahora, comencemos raspando el campo de encabezado. Para eso, use el gadget selector para obtener los selectores de CSS específicos que encierran el encabezado. Uno puede hacer clic en la extensión en su navegador y seleccionar el campo de encabezado con el cursor.
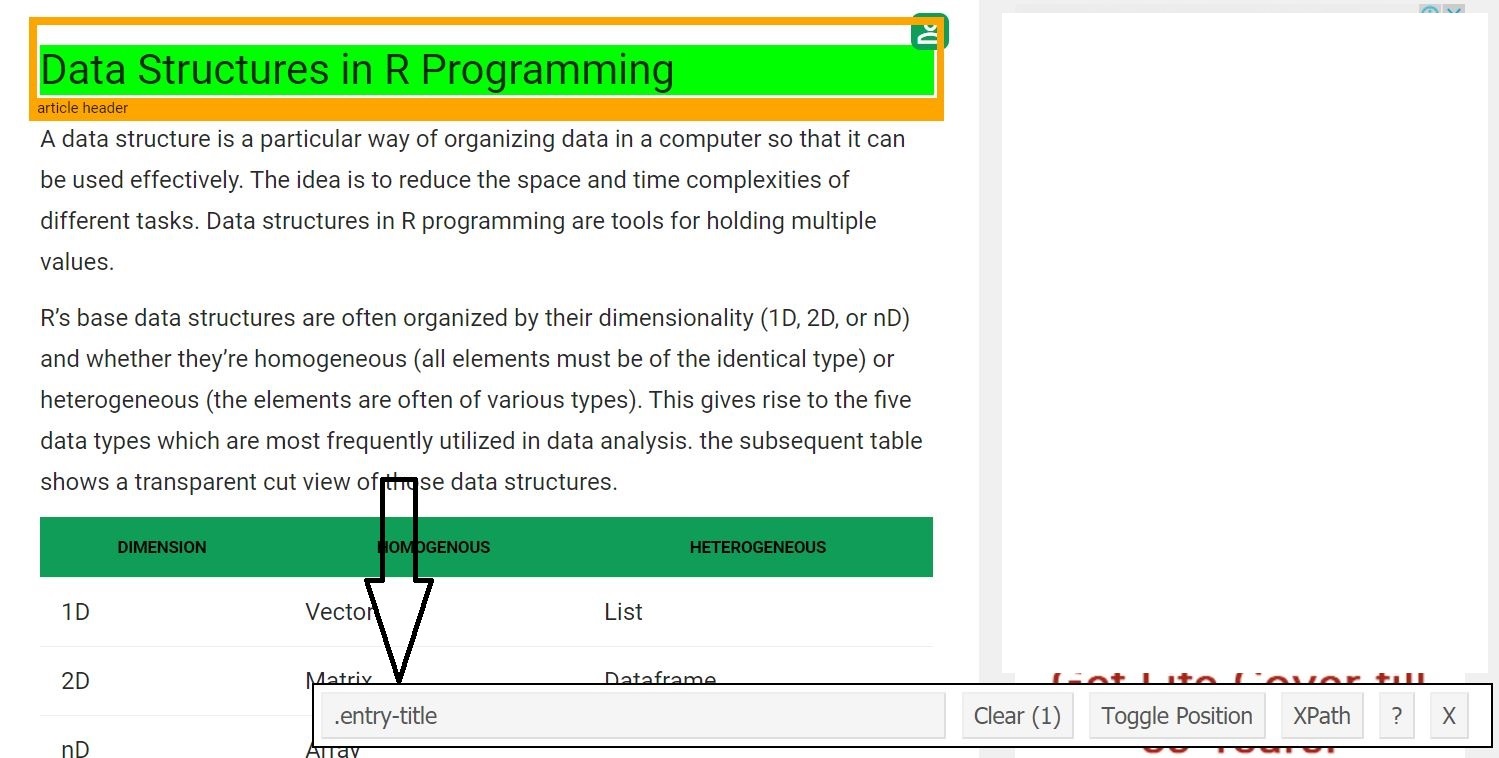
Una vez que uno conoce el selector CSS que contiene el encabezado, puede usar este código R simple para obtener el encabezado.
R
# Using CSS selectors to scrape the heading section heading = html_node(webpage, '.entry-title') # Converting the heading data to text text = html_text(heading) print(text)
Producción:
[1] "Data Structures in R Programming"
Ahora, raspamos todos los campos de párrafo. Para eso hicimos el mismo procedimiento que hicimos antes.
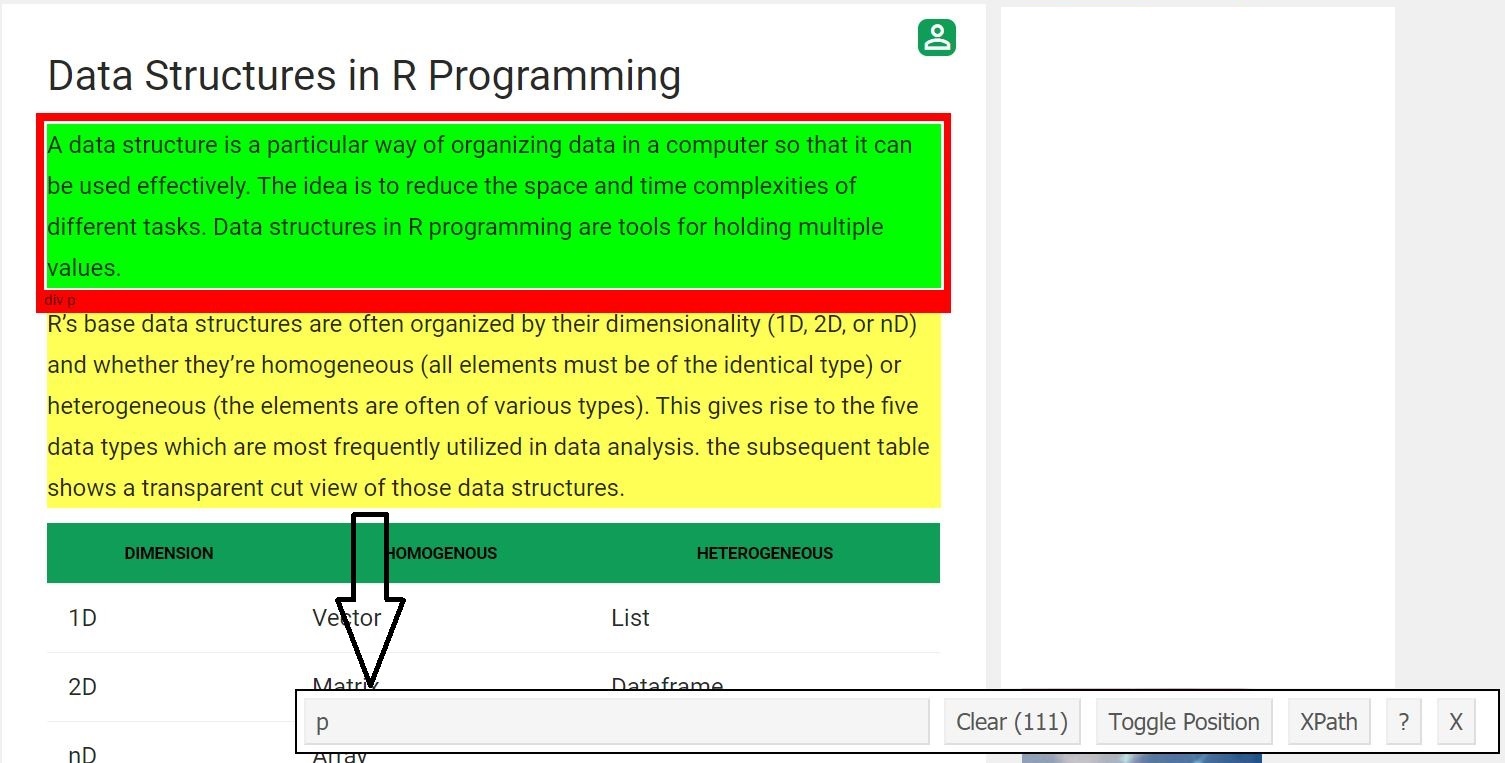
Una vez que uno conoce el selector CSS que contiene los párrafos, puede usar este código R simple para obtener todos los párrafos.
R
# Using CSS selectors to scrape # all the paragraph section # Note that we use html_nodes() here paragraph = html_nodes(webpage, 'p') # Converting the heading data to text pText = html_text(paragraph) # Print the top 6 data print(head(pText))
Producción:
[1] “Una estructura de datos es una forma particular de organizar los datos en una computadora para que pueda usarse de manera efectiva. La idea es reducir las complejidades de espacio y tiempo de las diferentes tareas. Las estructuras de datos en la programación R son herramientas para contener múltiples valores. ”
[2] “Las estructuras de datos base de R a menudo se organizan por su dimensionalidad (1D, 2D o nD) y si son homogéneas (todos los elementos deben ser del mismo tipo) o heterogéneas (los elementos suelen ser de varios tipos) . Esto da lugar a los cinco tipos de datos que se utilizan con mayor frecuencia en el análisis de datos. la siguiente tabla muestra una vista de corte transparente de esas estructuras de datos”.
[3] “Las estructuras de datos más esenciales utilizadas en R incluyen:”
[4] “”
[5] “Un vector es una colección ordenada de tipos de datos básicos de una longitud dada. La única clave aquí es que todos los elementos de un vector deben ser del mismo tipo de datos, por ejemplo, estructuras de datos homogéneas. Los vectores son estructuras de datos unidimensionales”.
[6] “Ejemplo:”
El código completo para Web Scraping usando R Language
R
# R program to illustrate
# Web Scraping
# Import rvest library
library(rvest)
# Reading the HTML code from the website
webpage = read_html("https://www.geeksforgeeks.org /
data-structures-in-r-programming")
# Using CSS selectors to scrape the heading section
heading = html_node(webpage, '.entry-title')
# Converting the heading data to text
text = html_text(heading)
print(text)
# Using CSS selectors to scrape
# all the paragraph section
# Note that we use html_nodes() here
paragraph = html_nodes(webpage, 'p')
# Converting the heading data to text
pText = html_text(paragraph)
# Print the top 6 data
print(head(pText))
Producción:
[1] “Estructuras de datos en programación R”
[1] “Una estructura de datos es una forma particular de organizar los datos en una computadora para que pueda usarse de manera efectiva. La idea es reducir las complejidades de espacio y tiempo de las diferentes tareas. Las estructuras de datos en la programación R son herramientas para contener múltiples valores. ” [2] “Las estructuras de datos base de R a menudo se organizan por su dimensionalidad (1D, 2D o nD) y si son homogéneas (todos los elementos deben ser del mismo tipo) o heterogéneas (los elementos suelen ser de varios tipos) . Esto da lugar a los cinco tipos de datos que se utilizan con mayor frecuencia en el análisis de datos. la siguiente tabla muestra una vista de corte transparente de esas estructuras de datos”. [3] “Las estructuras de datos más esenciales utilizadas en R incluyen:” [4] “” [5] “Un vector es una colección ordenada de tipos de datos básicos de una longitud dada. La única clave aquí es que todos los elementos de un vector deben ser del mismo tipo de datos, por ejemplo, estructuras de datos homogéneas. Los vectores son estructuras de datos unidimensionales”. [6] “Ejemplo:”
Publicación traducida automáticamente
Artículo escrito por AmiyaRanjanRout y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA