Prerrequisitos: Web Scraping usando BeautifulSoap
Los casos de coronavirus están aumentando rápidamente en todo el mundo. Este artículo lo guiará sobre cómo raspar datos de coronavirus en la web y en Ms-excel.
¿Qué es el raspado web?
Si alguna vez ha copiado y pegado información de un sitio web, ha realizado la misma función que cualquier web scraper, solo que en una escala manual microscópica. El raspado web, también conocido como minería de datos en línea, es el método para extraer o raspar datos de un sitio web. Este conocimiento se recopila y luego se traduce a un medio que es más accesible para el usuario. Es una hoja de cálculo o una API.
Acercarse:
- Solicitud de respuesta desde la página web.
- Analice y extraiga con la ayuda del método de clase BeautifulSoup() y el módulo lxml .
- Descarga y exporta los datos con pandas a Excel.
La fuente de datos:
Necesitamos una página web para obtener los datos del coronavirus. Así que usaremos el sitio web de Worldometer aquí. La página web de Worldometer se verá así:
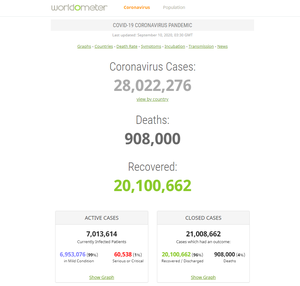
fuente de datos
Implementación Programática
Necesitará algunas bibliotecas, por lo que primero debe instalarlas.
Vaya a su línea de comando e instálelos.
pip install requests pip install lxml pip install bs4
Ahora veamos qué podemos hacer con estas bibliotecas.
A continuación se muestran los pasos para el raspado web de datos de coronavirus en Excel:
Paso 1) Use la biblioteca de requests para capturar la página.
Python3
# Import required module
import requests
# Make requests from webpage
result = requests.get('https://www.worldometers.info/coronavirus/country/india/')
La biblioteca de requests que descargamos va y obtiene una respuesta, para obtener una solicitud de la página web, usamos el método request.get (URL del sitio web). Si la solicitud tiene éxito, se almacenará como una string de Python gigante. Podremos obtener el código fuente completo de la página web cuando ejecutemos result.text. Pero el código no estará estructurado.
Nota: Esto puede fallar si tiene un firewall que bloquea Python/Jupyter. A veces es necesario ejecutar esto dos veces si falla la primera vez.
Paso 2) Utilice el método BeautifulSoap() para extraer datos de sitios web.
La biblioteca bs4 ya tiene muchas herramientas y métodos integrados para obtener información de una string de esta naturaleza (básicamente un archivo HTML). Es una biblioteca de Python para extraer datos de archivos HTML y XML. Usando el método BeautifulSoup() del módulo bs4 , podemos crear un objeto de sopa que contenga todos los ingredientes de la página web.
Python3
# Import required modules import bs4 # Creating soap object soup = bs4.BeautifulSoup(result.text,'lxml')
Importar bs4 es crear un objeto BeautifulSoup . Y vamos a pasar dos cosas aquí, result.text string y lxml como una string como argumento constructor. lxml revisa este documento HTML y luego descubre diferentes clases de CSS , ids , elementos HTML y etiquetas, etc.
Al extraer los datos, para encontrar el elemento, debe hacer clic derecho y presionar inspeccionar en la cantidad de casos. Consulte la instantánea adjunta a continuación.
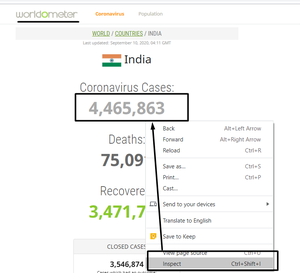
inspeccionando el sitio web
Necesitamos encontrar la clase correcta, es decir, class_= ‘maincounter-number’ sirve para nuestro propósito. Consulte la instantánea adjunta a continuación.
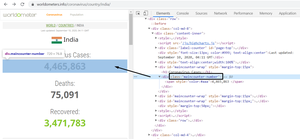
Encontrar la clase adecuada
El objeto BeautifulSoup se creó en nuestro script de Python y los datos HTML del sitio web se eliminaron de la página. A continuación, necesitamos obtener los datos que nos interesan del código HTML.
Python3
# Searching div tags having maincounter-number class
cases = soup.find_all('div' ,class_= 'maincounter-number')
Captura de pantalla de entrada (elemento de inspección):

Todavía hay mucho código HTML que no queremos. Nuestras entradas de datos deseadas están envueltas en el elemento HTML div y dentro de class_= ‘maincounter-number’ . Podemos usar este conocimiento para limpiar aún más los datos raspados.
Paso 3) Almacenar los datos
Necesitamos guardar los datos raspados de alguna forma que se pueda usar de manera efectiva. Para este proyecto, todos los datos se guardarán en una lista de Python.
Python3
# List to store number of cases
data = []
# Find the span and get data from it
for i in cases:
span = i.find('span')
data.append(span.string)
# Display number of cases
print(data)
Captura de pantalla de entrada (elemento de inspección):

Producción:

Usaremos span para obtener datos de div . Solo necesitamos el número de casos, no las etiquetas. Así que usaremos span.string para obtener esos números, y luego se almacenarán en data[].
Ahora que tenemos el número de casos, estamos listos para exportar nuestros datos a un archivo de Excel.
Paso 4) Procesamiento de los datos
Nuestro último paso es exportar los datos a Ms-Excel, para lo cual vamos a utilizar el módulo pandas . Para cargar el módulo pandas y comenzar a trabajar con él, importe el paquete.
Python3
import pandas as pd
# Creating dataframe
df = pd.DataFrame({"CoronaData": data})
# Naming the columns
df.index = ['TotalCases', ' Deaths', 'Recovered']
DataFrame es una estructura de datos etiquetada en 2D, una estructura de datos tabular potencialmente heterogénea con ejes etiquetados (filas y columnas).
df = pd.DataFrame({“CoronaData”: data}) se usa para crear un DataFrame y darle un nombre y asignarlo a la lista de datos que creamos anteriormente.
A continuación, daremos nombres de columna con df.index .
Producción:

Paso 5) Exportación de datos a Excel
Estamos listos para exportar los datos a Excel. Usaremos el método df.to_csv() para esta tarea.
Python3
# Exporting data into Excel
df.to_csv('Corona_Data.csv')
Producción:

A continuación se muestra el programa completo de los pasos anteriores:
Python3
# Import required modules
import requests
import bs4
import pandas as pd
# Make requests from webpage
url = 'https://www.worldometers.info/coronavirus/country/india/'
result = requests.get(url)
# Creating soap object
soup = bs4.BeautifulSoup(result.text,'lxml')
# Searching div tags having maincounter-number class
cases = soup.find_all('div' ,class_= 'maincounter-number')
# List to store number of cases
data = []
# Find the span and get data from it
for i in cases:
span = i.find('span')
data.append(span.string)
# Display number of cases
print(data)
# Creating dataframe
df = pd.DataFrame({"CoronaData": data})
# Naming the columns
df.index = ['TotalCases', ' Deaths', 'Recovered']
# Exporting data into Excel
df.to_csv('Corona_Data.csv')
Resultado final:
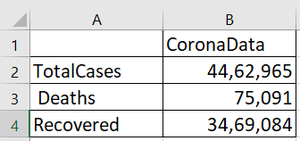
Publicación traducida automáticamente
Artículo escrito por ayushi7rawat y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA