Hashing se refiere al proceso de generar una salida de tamaño fijo a partir de una entrada de tamaño variable utilizando fórmulas matemáticas conocidas como funciones hash. Esta técnica determina un índice o ubicación para el almacenamiento de un elemento en una estructura de datos.

que es hashing
- que es hashing
- Necesidad de estructura de datos hash
- Componentes de hashing
- ¿Cómo funciona Hashing?
- ¿Qué es una función hash?
- Problema con Hashing:
- ¿Qué se entiende por factor de carga en hashing?
- ¿Qué es Rehashing?
- Aplicaciones de la estructura de datos hash
- Aplicaciones en tiempo real de la estructura de datos hash
- Ventajas de la estructura de datos hash
- Desventajas de la estructura de datos hash
- Conclusión
Necesidad de estructura de datos hash
Todos los días, los datos en Internet se multiplican y siempre es difícil almacenar estos datos de manera eficiente. En la programación diaria, esta cantidad de datos puede no ser tan grande, pero aun así, debe almacenarse, accederse y procesarse de manera fácil y eficiente. Una estructura de datos muy común que se utiliza para tal fin es la estructura de datos Array.
Ahora surge la pregunta si Array ya estaba allí, ¡cuál era la necesidad de una nueva estructura de datos! La respuesta a esto está en la palabra “ eficiencia ”. Aunque almacenar en Array toma tiempo O(1), buscar en él toma al menos O(log n) tiempo. Este tiempo parece ser pequeño, pero para un gran conjunto de datos, puede causar muchos problemas y esto, a su vez, hace que la estructura de datos Array sea ineficiente.
Así que ahora estamos buscando una estructura de datos que pueda almacenar los datos y buscarlos en tiempo constante, es decir, en tiempo O(1). Así es como entró en juego la estructura de datos Hashing. Con la introducción de la estructura de datos Hash, ahora es posible almacenar datos fácilmente en tiempo constante y recuperarlos también en tiempo constante.
Componentes de hashing
Hay principalmente tres componentes de hashing:
- Clave: una clave puede ser cualquier string o entero que se alimenta como entrada en la función hash, la técnica que determina un índice o ubicación para el almacenamiento de un elemento en una estructura de datos.
- Función hash: la función hash recibe la clave de entrada y devuelve el índice de un elemento en una array llamada tabla hash. El índice se conoce como índice hash .
- Tabla hash: la tabla hash es una estructura de datos que asigna claves a valores mediante una función especial llamada función hash. Hash almacena los datos de manera asociativa en una array donde cada valor de datos tiene su propio índice único.
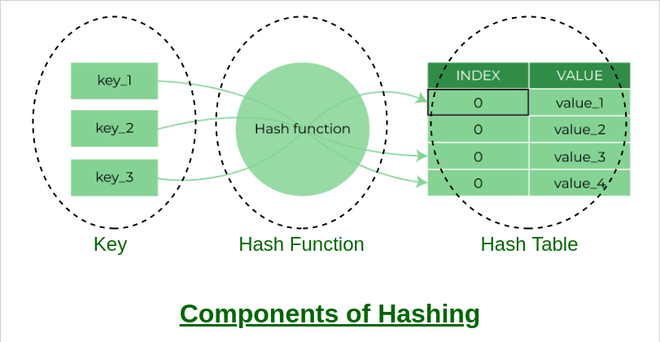
Componentes de hashing
¿Cómo funciona Hashing?
Supongamos que tenemos un conjunto de strings {“ab”, “cd”, “efg”} y nos gustaría almacenarlo en una tabla.
Nuestro principal objetivo aquí es buscar o actualizar los valores almacenados en la tabla rápidamente en tiempo O(1) y no nos preocupa el orden de las strings en la tabla. Entonces, el conjunto dado de strings puede actuar como una clave y la string en sí misma actuará como el valor de la string, pero ¿cómo almacenar el valor correspondiente a la clave?
- Paso 1: sabemos que las funciones hash (que es una fórmula matemática) se utilizan para calcular el valor hash que actúa como índice de la estructura de datos donde se almacenará el valor.
- Paso 2: Entonces, asignemos
- “a” = 1,
- “b”=2, .. etc, a todos los caracteres alfabéticos.
- Paso 3: Por lo tanto, el valor numérico por suma de todos los caracteres de la string:
- “ab” = 1 + 2 = 3,
- “cd” = 3 + 4 = 7 ,
- “efg” = 5 + 6 + 7 = 18
- Paso 4: Ahora, supongamos que tenemos una tabla de tamaño 7 para almacenar estas strings. La función hash que se usa aquí es la suma de los caracteres en el tamaño de la tabla mod clave . Podemos calcular la ubicación de la string en la array tomando la suma(string) mod 7 .
- Paso 5: entonces almacenaremos
- “ab” en 3 mod 7 = 3,
- “cd” en 7 mod 7 = 0, y
- “efg” en 18 mod 7 = 4.

Clave de mapeo con índices de array
La técnica anterior nos permite calcular la ubicación de una string dada usando una función hash simple y encontrar rápidamente el valor que está almacenado en esa ubicación. Por lo tanto, la idea de hashing parece una excelente manera de almacenar pares (clave, valor) de los datos en una tabla.
¿Qué es una función hash?
La función hash crea un mapeo entre clave y valor, esto se hace mediante el uso de fórmulas matemáticas conocidas como funciones hash. El resultado de la función hash se denomina valor hash o hash. El valor hash es una representación de la string original de caracteres, pero normalmente es más pequeño que el original.
Por ejemplo: considere una array como un mapa donde la clave es el índice y el valor es el valor en ese índice. Entonces, para una array A, si tenemos un índice i que será tratado como la clave, entonces podemos encontrar el valor simplemente mirando el valor en A[i].
simplemente buscando A[i].
Tipos de funciones hash:
Hay muchas funciones hash que usan claves numéricas o alfanuméricas. Este artículo se centra en discutir diferentes funciones hash :
Propiedades de una buena función hash
Una función hash que mapea cada elemento en su propia ranura única se conoce como función hash perfecta. Podemos construir una función hash perfecta si conocemos los elementos y la colección nunca cambiará, pero el problema es que no existe una forma sistemática de construir una función hash perfecta dada una colección arbitraria de elementos. Afortunadamente, seguiremos ganando eficiencia en el rendimiento incluso si la función hash no es perfecta. Podemos lograr una función hash perfecta aumentando el tamaño de la tabla hash para que se puedan acomodar todos los valores posibles. Como resultado, cada artículo tendrá una ranura única. Aunque este enfoque es factible para una pequeña cantidad de artículos, no es práctico cuando la cantidad de posibilidades es grande.
Entonces, podemos construir nuestra función hash para hacer lo mismo, pero las cosas con las que debemos tener cuidado al construir nuestra propia función hash.
Una buena función hash debe tener las siguientes propiedades:
- Eficientemente computable.
- Debe distribuir uniformemente las llaves (Cada posición de la mesa es igualmente probable para cada uno.
- Debe minimizar las colisiones.
- Debe tener un factor de carga bajo (número de elementos en la tabla dividido por el tamaño de la tabla).
Complejidad de calcular el valor hash usando la función hash
- Complejidad temporal: O(n)
- Complejidad del espacio: O(1)
Problema con hash
Si consideramos el ejemplo anterior, la función hash que usamos es la suma de las letras, pero si examinamos la función hash de cerca, entonces el problema se puede visualizar fácilmente de que para diferentes strings, la función hash comienza a generar el mismo valor hash.
Por ejemplo: {“ab”, “ba”} ambos tienen el mismo valor hash, y la string {“cd”,”be”} también genera el mismo valor hash, etc. Esto se conoce como colisión y crea problemas en la búsqueda. , inserción, eliminación y actualización de valor.
¿Qué es la colisión?
El proceso de hashing genera un número pequeño para una clave grande, por lo que existe la posibilidad de que dos claves produzcan el mismo valor. La situación en la que la tecla recién insertada se asigna a una ya ocupada y debe manejarse utilizando alguna tecnología de manejo de colisiones.

¿Qué es la colisión en hashing?
¿Cómo manejar las colisiones?
Existen principalmente dos métodos para manejar la colisión:
- Enstringmiento separado:
- Direccionamiento abierto:
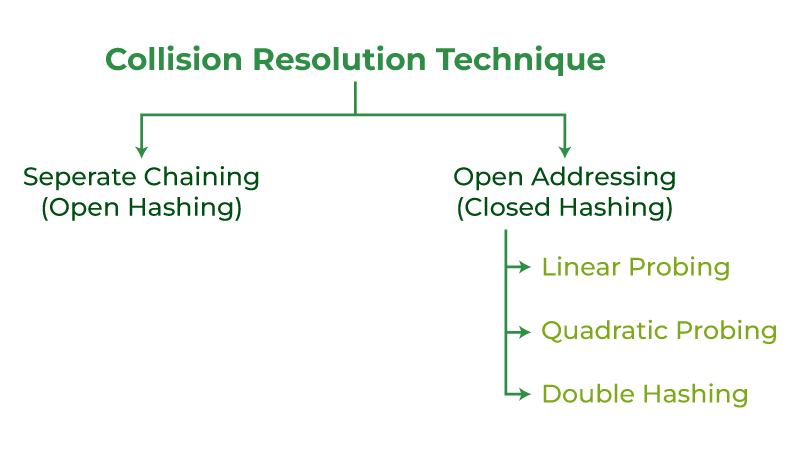
Técnica de resolución de colisiones
1) Enstringmiento separado
La idea es hacer que cada celda de la tabla hash apunte a una lista enlazada de registros que tienen el mismo valor de función hash. El enstringmiento es simple pero requiere memoria adicional fuera de la tabla.
Ejemplo: hemos dado una función hash y tenemos que insertar algunos elementos en la tabla hash usando un método de enstringmiento separado para la técnica de resolución de colisiones.
Hash function = key % 5, Elements = 12, 15, 22, 25 and 37.
Veamos el enfoque paso a paso de cómo resolver el problema anterior:
- Paso 1: Primero dibuje la tabla hash vacía que tendrá un posible rango de valores hash de 0 a 4 según la función hash proporcionada.
Tabla de picadillo
- Paso 2: ahora inserte todas las claves en la tabla hash una por una. La primera clave que se inserta es 12, que se asigna al depósito número 2, que se calcula mediante la función hash 12%5=2.
Inserte la clave 12 en la tabla hash
- Paso 3: La siguiente clave es 15. Se asignará a la ranura número 0 porque 15%5=0. Así que insértelo en el cubo número 5.
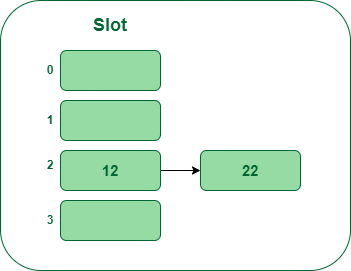
Inserte la clave 15 en la tabla hash
- Paso 4: ahora la siguiente clave es 22. Se asignará al depósito número 2 porque 22%5=2. Pero el cubo 2 ya está ocupado por la clave 12. Por lo tanto, el método de enstringmiento separado manejará esta colisión creando una lista vinculada al cubo 2.
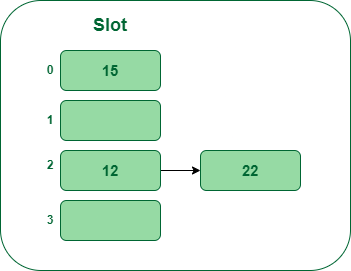
Inserte la clave 22 en la tabla hash
- Paso 5: Ahora la siguiente clave es 25. Su número de cubo será 25%5=0. Pero el cubo 0 ya está ocupado por la clave 25. Por lo tanto, el método de enstringmiento separado manejará nuevamente la colisión creando una lista vinculada al cubo 0.
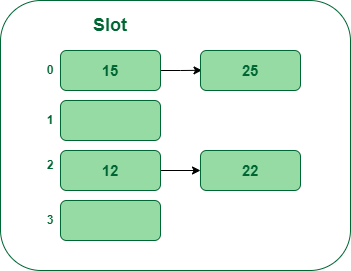
Inserte la clave 25 en la tabla hash
Por lo tanto, de esta manera, el método de enstringmiento separado se utiliza como técnica de resolución de colisiones.
2) Direccionamiento abierto
En el direccionamiento abierto, todos los elementos se almacenan en la propia tabla hash. Cada entrada de la tabla contiene un registro o NIL. Al buscar un elemento, examinamos las ranuras de la tabla una por una hasta que se encuentra el elemento deseado o está claro que el elemento no está en la tabla.
2.a) Sondeo lineal
En el sondeo lineal, la tabla hash se busca secuencialmente desde la ubicación original del hash. Si en caso de que la ubicación que obtengamos ya esté ocupada, buscamos la siguiente ubicación.
Algoritmo:
- Calcular la clave hash. es decir , clave = tamaño de % de datos
- Compruebe si hashTable[key] está vacío
- almacenar el valor directamente por hashTable[clave] = datos
- Si el índice hash ya tiene algún valor, entonces
- verifique el siguiente índice usando la tecla = (tecla + 1) % tamaño
- Verifique si el siguiente índice está disponible hashTable [clave] y luego almacene el valor. De lo contrario, intente con el siguiente índice.
- Haz el proceso anterior hasta que encontremos el espacio.
Ejemplo: Consideremos una función hash simple como «clave mod 5» y una secuencia de claves que se insertarán son 50, 70, 76, 85, 93.
- Paso 1: Primero dibuje la tabla hash vacía que tendrá un posible rango de valores hash de 0 a 4 según la función hash proporcionada.
Tabla de picadillo
- Paso 2: ahora inserte todas las claves en la tabla hash una por una. La primera clave es 50. Se asignará a la ranura número 0 porque 50%5=0. Así que insértelo en la ranura número 0.
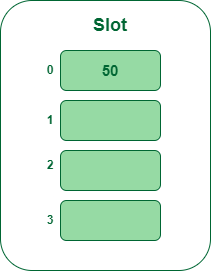
Inserte la clave 50 en la tabla hash
- Paso 3: La siguiente clave es 70. Se asignará a la ranura número 0 porque 70%5=0 pero 50 ya está en la ranura número 0, así que busque la siguiente ranura vacía e insértela.
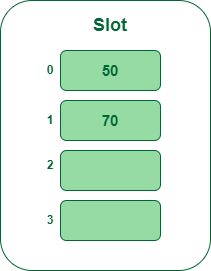
Inserte la clave 70 en la tabla hash
- Paso 4: La siguiente clave es 76. Se asignará a la ranura número 1 porque 76%5=1 pero 70 ya está en la ranura número 1, así que busque la siguiente ranura vacía e insértela.
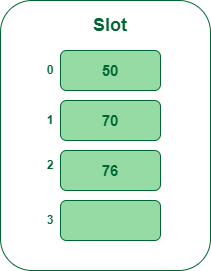
Inserte la clave 76 en la tabla hash
- Paso 5: La siguiente clave es 93. Se asignará a la ranura número 3 porque 93%5=3, así que insértela en la ranura número 3.
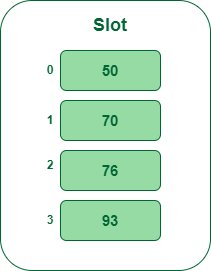
Inserte la clave 93 en la tabla hash
2.b) Sondeo cuadrático
El sondeo cuadrático es un esquema de direccionamiento abierto en la programación de computadoras para resolver colisiones hash en tablas hash. El sondeo cuadrático opera tomando el índice hash original y agregando valores sucesivos de un polinomio cuadrático arbitrario hasta que se encuentra una ranura abierta.
Una secuencia de ejemplo que usa sondeo cuadrático es:
H + 1 2 , H + 2 2 , H + 3 2 , H + 4 2 …………………. H + k 2
Este método también se conoce como el método del cuadrado medio porque en este método buscamos i 2 ‘th sonda (ranura) en i’th iteración y el valor de i = 0, 1, . . . n – 1. Siempre comenzamos desde la ubicación hash original. Si solo la ubicación está ocupada, verificamos las otras ranuras.
Sea hash(x) el índice de ranura calculado mediante la función hash y n el tamaño de la tabla hash.
Si la ranura hash(x) % n está llena, entonces intentamos (hash(x) + 1 2 ) % n.
Si (hash(x) + 1 2 ) % n también está lleno, entonces intentamos (hash(x) + 2 2 ) % n.
Si (hash(x) + 2 2 ) % n también está lleno, entonces intentamos (hash(x) + 3 2 ) % n.
Este proceso se repetirá para todos los valores de i hasta que se encuentre una ranura vacía
Ejemplo: Consideremos el tamaño de la tabla = 7, la función hash como Hash(x) = x % 7 y la estrategia de resolución de colisiones como f(i) = i 2 . Insertar = 25, 33 y 105
- Paso 1: crea una tabla de tamaño 7.
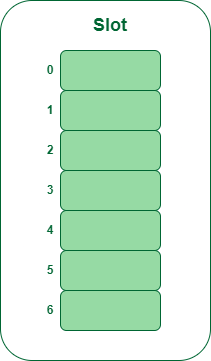
Tabla de picadillo
- Paso 2 : inserte 22 y 30
- Hash(25) = 22 % 7 = 1, dado que la celda en el índice 1 está vacía, podemos insertar fácilmente 22 en la ranura 1.
- Hash(30) = 30 % 7 = 2, dado que la celda en el índice 2 está vacía, podemos insertar fácilmente 30 en la ranura 2.
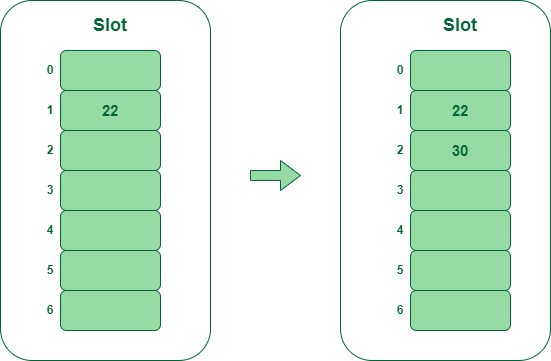
Insertar clave 22 y 30 en la tabla hash
- Paso 3: Insertar 50
- Hash(25) = 50 % 7 = 1
- En nuestra tabla hash, la ranura 1 ya está ocupada. Entonces, buscaremos la ranura 1+1 2 , es decir, 1+1 = 2,
- De nuevo, la ranura 2 se encuentra ocupada, por lo que buscaremos la celda 1+2 2 , es decir, 1+4 = 5,
- Ahora, la celda 5 no está ocupada, por lo que colocaremos 50 en la ranura 5.
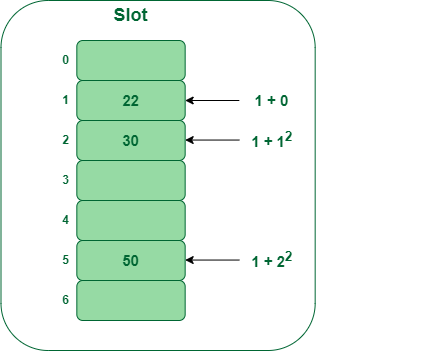
Inserte la clave 50 en la tabla hash
2.c) Hashing doble
El hashing doble es una técnica de resolución de colisiones en las tablas hash abiertas dirigidas . El hash doble hace uso de dos funciones hash,
- La primera función hash es h1(k) que toma la clave y proporciona una ubicación en la tabla hash. Pero si la nueva ubicación no está ocupada o vacía, podemos colocar nuestra llave fácilmente.
- Pero en caso de que la ubicación esté ocupada (colisión), usaremos la función hash secundaria h2(k) en combinación con la primera función hash h1(k) para encontrar la nueva ubicación en la tabla hash.
Esta combinación de funciones hash es de la forma
h(k, i) = h1(k) + i * h2(k)) % n
dónde
- i es un número entero no negativo que indica un número de colisión,
- k = elemento/clave que se está procesando
- n = tamaño de la tabla hash.
Complejidad del algoritmo de hash doble:
Time complexity: O(n)
Ejemplo: inserte las claves 27, 43, 98, 72 en la tabla hash de tamaño 7, donde la primera función hash es h1(k) = k mod 7 y la segunda función hash es h2(k) = 1 + (k modelo 5)
- Paso 1: Insertar 27
- 27 % 7 = 6, la ubicación 6 está vacía, así que inserte 27 en la ranura 6.
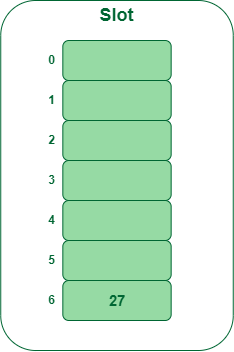
Inserte la clave 27 en la tabla hash
- Paso 2: Insertar 43
- 43 % 7 = 1, la ubicación 1 está vacía, así que inserte 43 en 1 ranura.
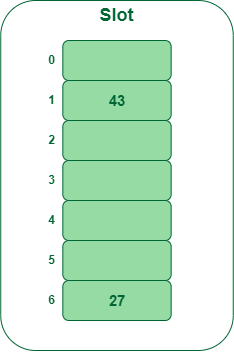
Inserte la clave 43 en la tabla hash
- Paso 3: Insertar 92
- 92 % 7 = 6, pero la ubicación 6 ya está ocupada y esto es una colisión
- Entonces, necesitamos resolver esta colisión usando doble hash.
hnew = [h1(92) + i * (h2(92)] % 7 = [6 + 1 * (1 + 92 % 5)] % 7 = 9 % 7 = 2 Now, as 2 is an empty slot, so we can insert 92 into 2nd slot.
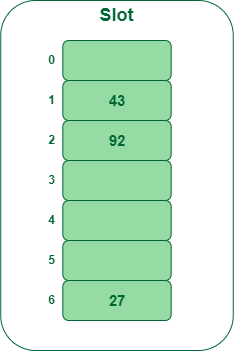
Inserte la clave 92 en la tabla hash
- Paso 4: Insertar 72
- 72 % 7 = 2, pero la ubicación 2 ya está ocupada y esto es una colisión.
- Entonces, necesitamos resolver esta colisión usando doble hash.
hnew = [h1(72) + i * (h2(72)] % 7 = [2 + 1 * (1 + 72 % 5)] % 7 = 5 % 7 = 5, Now, as 5 is an empty slot, so we can insert 72 into 5th slot.

Inserte la clave 72 en la tabla hash
¿Qué se entiende por factor de carga en hashing?
El factor de carga de la tabla hash se puede definir como el número de elementos que contiene la tabla hash dividido por el tamaño de la tabla hash. El factor de carga es el parámetro decisivo que se utiliza cuando queremos repetir la función hash anterior o queremos agregar más elementos a la tabla hash existente.
Nos ayuda a determinar la eficacia de la función hash, es decir, indica si la función hash que estamos utilizando distribuye las claves de manera uniforme o no en la tabla hash.
Load Factor = Total elements in hash table/ Size of hash table
¿Qué es Rehashing?
Como sugiere el nombre, repetir significa volver a hacer hash. Básicamente, cuando el factor de carga aumenta por encima de su valor predefinido (el valor predeterminado del factor de carga es 0,75), la complejidad aumenta. Entonces, para superar esto, el tamaño de la array aumenta (se duplica) y todos los valores se vuelven a codificar y se almacenan en la nueva array de tamaño doble para mantener un factor de carga bajo y una complejidad baja.
Aplicaciones de la estructura de datos hash
- Hash se utiliza en bases de datos para la indexación.
- Hash se utiliza en estructuras de datos basadas en disco.
- En algunos lenguajes de programación como Python, el hash de JavaScript se usa para implementar objetos.
Aplicaciones en tiempo real de la estructura de datos hash
- Hash se utiliza para el mapeo de caché para un acceso rápido a los datos.
- Hash se puede utilizar para la verificación de contraseña.
- Hash se usa en criptografía como un resumen de mensaje.
Ventajas de la estructura de datos hash
- Hash proporciona una mejor sincronización que otras estructuras de datos.
- Las tablas hash son más eficientes que los árboles de búsqueda u otras estructuras de datos
- Hash proporciona un tiempo constante para las operaciones de búsqueda, inserción y eliminación en promedio.
Desventajas de la estructura de datos hash
- Hash es ineficiente cuando hay muchas colisiones.
- Las colisiones hash prácticamente no se evitan para un gran conjunto de claves posibles.
- Hash no permite valores nulos.
Conclusión
De la discusión anterior, concluimos que el objetivo del hash es resolver el desafío de encontrar un elemento rápidamente en una colección. Por ejemplo, si tenemos una lista de millones de palabras en inglés y deseamos encontrar un término en particular, usaríamos hash para ubicarlo y encontrarlo de manera más eficiente. Sería ineficiente verificar cada elemento en millones de listas hasta que encontremos una coincidencia. Hashing reduce el tiempo de búsqueda al restringir la búsqueda a un conjunto más pequeño de palabras al principio.
Publicación traducida automáticamente
Artículo escrito por harendrakumar123 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA