En este artículo, veremos cómo obtener un resumen del modelo de regresión de sci-kit learn.
Se puede hacer de estas formas:
- Paquetes de aprendizaje de Scikit
- Paquete de modelo de estadísticas
Ejemplo 1: uso de scikit-learn .
Es posible que desee extraer un resumen de un modelo de regresión creado en Python con Scikit-learn. Scikit-learn no tiene muchas funciones integradas para analizar el resumen de un modelo de regresión porque generalmente se usa para la predicción. Scikit learn tiene diferentes atributos y métodos para obtener el resumen del modelo.
Importamos los paquetes necesarios. Luego, el conjunto de datos del iris se carga desde sklearn.datasets. Y se crean arrays de características y objetivos, luego se crean conjuntos de prueba y entrenamiento usando el método train_test_split() y se crea el modelo de regresión lineal simple, luego se ajustan los datos de entrenamiento en el modelo y se llevan a cabo predicciones en el conjunto de prueba usando .predict( ) método.
Python3
# Import packages
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
# Load the data
irisData = load_iris()
# Create feature and target arrays
X = irisData.data
y = irisData.target
# Split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42)
model = LinearRegression()
model.fit(X_train, y_train)
# predicting on the X_test data set
print(model.predict(X_test))
# summary of the model
print('model intercept :', model.intercept_)
print('model coefficients : ', model.coef_)
print('Model score : ', model.score(X, y))
Producción:
[ 1.23071715 -0.04010441 2.21970287 1.34966889 1.28429336 0.02248402
1.05726124 1.82403704 1.36824643 1.06766437 1.70031437 -0.07357413
-0.15562919 -0.06569402 -0.02128628 1.39659966 2.00022876 1.04812731
1.28102792 1.97283506 0.03184612 1.59830192 0.09450931 1.91807547
1.83296682 1.87877315 1.78781234 2.03362373 0.03594506 0.02619043]
intercepción del modelo: 0.2525275898181484
coeficientes del modelo: [-0.11633479 -0.05977785 0.25491375 0.54759598]
Puntuación del modelo: 0.9299538012397455
Ejemplo 2: Usar el método summary() del paquete del modelo Stats
En este método, usamos statsmodels. Paquete fórmula.api. Si desea extraer un resumen de un modelo de regresión en Python, debe usar el paquete statsmodels. El siguiente código demuestra cómo usar este paquete para ajustar el mismo modelo de regresión lineal múltiple que en el ejemplo anterior y obtener el resumen del modelo.
Para acceder y descargar el archivo CSV haga clic aquí .
Python3
# import packages
import numpy as np
import pandas as pd
import statsmodels.formula.api as smf
# loading the csv file
df = pd.read_csv('headbrain1.csv')
print(df.head())
# fitting the model
df.columns = ['Head_size', 'Brain_weight']
model = smf.ols(formula='Head_size ~ Brain_weight',
data=df).fit()
# model summary
print(model.summary())
Producción:
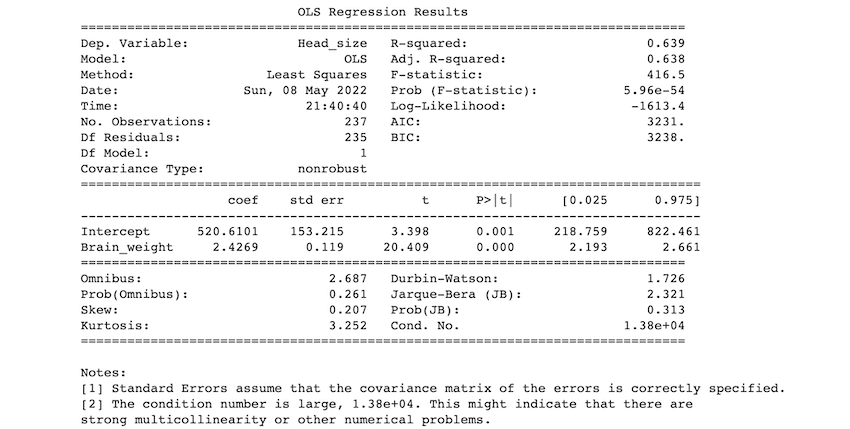
Descripción de algunos de los términos de la tabla:
- Valor de R-cuadrado: El valor de R-cuadrado varía de 0 a 1. Un R-cuadrado de 100% indica que los cambios en la variable independiente explican completamente todos los cambios en la(s) variable(s) dependiente(s). Si el valor de r-cuadrado es 1, indica un ajuste perfecto. El valor de r-cuadrado en nuestro ejemplo es 0,638.
- Estadística F: La estadística F compara el efecto combinado de todas las variables. En pocas palabras, si su nivel alfa es mayor que su valor p, debe rechazar la hipótesis nula.
- coef: los coeficientes de las variables independientes de la ecuación de regresión.
Nuestras predicciones:
Si usamos 0.05 como nuestro nivel de significancia, rechazamos la hipótesis nula y aceptamos la hipótesis alternativa como p< 0.05. Como resultado, podemos concluir que existe una relación entre el tamaño de la cabeza y el peso del cerebro.
Publicación traducida automáticamente
Artículo escrito por isitapol2002 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA