El conjunto de datos de flores de Tensorflow es un gran conjunto de datos de imágenes de flores. En este artículo, veremos cómo podemos usar Tensorflow para cargar el conjunto de datos de flores y trabajar con él.
Comencemos importando las bibliotecas necesarias. Aquí vamos a usar la biblioteca tensorflow_dataset para cargar el conjunto de datos. Es una biblioteca de conjuntos de datos públicos listos para usar con TensorFlow. Si no tiene ninguna de las bibliotecas mencionadas a continuación, puede instalarlas usando el comando pip, por ejemplo, para instalar la biblioteca tensorflow_datasets, debe escribir el siguiente comando:
pip install tensorflow-datasets
Python3
# Importing libraries import tensorflow as tf import numpy as np import pandas as pd import tensorflow_datasets as tfds
Para importar el conjunto de datos de flores, vamos a utilizar el método tfds.load(). Se utiliza para cargar el conjunto de datos con nombre, que se proporciona mediante el argumento de nombre, en un tf.data.Dataset. El nombre del conjunto de datos de flores es tf_flowers . En el método, también dividimos el conjunto de datos usando el argumento dividido con training_set tomando el 70% del conjunto de datos y el resto yendo a test_set.
Python3
(training_set, test_set), info = tfds.load( 'tf_flowers', split=['train[:70%]', 'train[70%:]'], with_info=True, as_supervised=True, )
Si imprimimos la información proporcionada por Tensorflow para el conjunto de datos usando el comando de impresión, obtendremos el siguiente resultado:
Python3
print(info)
Producción:
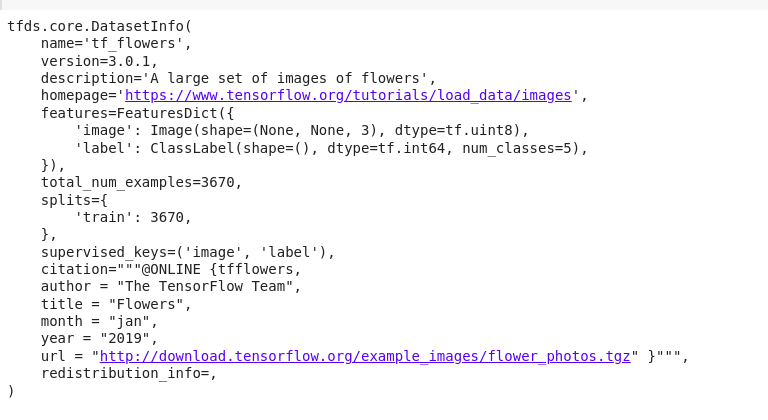
El conjunto de datos de flores contiene 3670 imágenes de flores, que se distribuyen de la siguiente manera en training_set y test_set.
Python3
print("Training Set Size: %d" % training_set.cardinality().numpy())
print("Test Set Size: %d" % test_set.cardinality().numpy())
Producción:

El conjunto de datos de flores consta de imágenes de 5 tipos diferentes de flores.
Python3
num_classes = info.features['label'].num_classes
print("Number of Classes: %d" % num_classes)
Producción:

Ahora visualicemos algunas de las imágenes en el conjunto de datos. El siguiente código muestra las primeras 5 imágenes en el conjunto de datos.
Python3
import matplotlib.pyplot as plt
ctr = 0
plt.rcParams["figure.figsize"] = [30, 15]
plt.rcParams["figure.autolayout"] = True
for image, label in training_set:
image = image.numpy()
plt.subplot(1, 5, ctr+1)
plt.title('Label {}'.format(label))
plt.imshow(image, cmap=plt.cm.binary)
ctr += 1
if ctr == 5:
break
plt.show()
Producción:

Si puede observar con atención, las diferentes imágenes no tienen el mismo tamaño sino que tienen diferentes tamaños. Podemos verificar esto imprimiendo los tamaños de las imágenes que visualizamos hace un momento. El siguiente código logra el objetivo:
Python3
for i, example in enumerate(training_set.take(5)):
shape = example[0].shape
print("Image %d -> shape: (%d, %d) label: %d" %
(i, shape[0], shape[1], example[1]))
Producción:

Como puede observar, las formas de las distintas imágenes son diferentes.
Sin embargo, con el fin de introducir este conjunto de datos en un modelo de aprendizaje automático, necesitaremos que todas las imágenes tengan el mismo tamaño. Para ello, preprocesaremos un poco las imágenes. Es decir, cambiaremos el tamaño de todas las imágenes a un tamaño fijo, que en este caso es 224, y normalizaremos las imágenes para que el valor de cada píxel esté en el rango de 0 a 1. El siguiente fragmento de código cumple el propósito deseado.
Python3
IMG_SIZE = 224 def format_image(image, label): image = tf.image.resize(image, (IMG_SIZE, IMG_SIZE)) # Normalisation image = image/255.0 return image, label batch_size = 32 training_set = training_set.shuffle(300).map( format_image).batch(batch_size).prefetch(1) test_set = test_set.map(format_image).batch(batch_size).prefetch(1)
La impresión de ambos conjuntos de datos revela que correctamente se ha cambiado el tamaño de cada imagen en el conjunto de datos, y cada imagen tiene un tamaño (224,224,3).
Python3
print(training_set) print(test_set)
Producción:

Ahora puede alimentar este conjunto de datos a cualquier modelo de aprendizaje automático adecuado.
Para fines de demostración, utilizaremos una versión modificada de MobileNet para entrenar con este conjunto de datos. El siguiente es el fragmento de código que describe el modelo, el optimizador, la función de pérdida y la métrica utilizada durante el entrenamiento del modelo.
Python3
def getModel(image_shape): mobileNet = tf.keras.applications.mobilenet.MobileNet(image_shape) X = mobileNet.layers[-2].output X_output = tf.keras.layers.Dense(1, activation='relu')(X) model = tf.keras.models.Model(inputs=mobileNet.input, outputs=X_output) return model model = getModel((IMG_SIZE, IMG_SIZE, 3)) optimizer = tf.keras.optimizers.Adam() loss = 'mean_squared_error' model.compile(optimizer=optimizer, loss=loss, metrics='accuracy') epochs = 5 model.fit(training_set, epochs=epochs, validation_data=test_set)
Producción:

El modelo funciona miserablemente en el conjunto de datos en este momento. Puede entrenar el modelo para una mayor cantidad de épocas, así como usar una codificación one-hot para la variable de salida para aumentar la precisión.
Publicación traducida automáticamente
Artículo escrito por aayushmohansinha y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA