En este artículo, veremos cómo convertir un conjunto de datos de sklearn en un marco de datos de pandas en Python .
Sklearn es una biblioteca de Python que se usa ampliamente para operaciones de ciencia de datos y aprendizaje automático. La biblioteca Sklearn proporciona una amplia lista de herramientas y funciones para entrenar modelos de aprendizaje automático.
La biblioteca está disponible a través de pip install.
pip install scikit-learn
Hay varios conjuntos de datos de muestra presentes en la biblioteca sklearn para ilustrar el uso de los diversos algoritmos que se pueden implementar a través de la biblioteca. A continuación se muestra la lista del conjunto de datos de muestra disponible:
- carga_cáncer_de_mama
- carga_boston
- carga_iris
- carga_diabetes
- cargar_digitos
- cargar_archivos
- carga_linnerud
- cargar_imágenes_de_muestra
- cargar_imagen_de_muestra
- cargar_vino
sklearn.conjuntos de datos.load_breast_cancer()
Se utiliza para cargar el conjunto de datos de cáncer de mama desde los conjuntos de datos de Sklearn.
Cada una de estas bibliotecas se puede importar desde el módulo sklearn.datasets. Como puede ver en los conjuntos de datos anteriores, el primer conjunto de datos son los datos sobre el cáncer de mama. Podemos cargar este conjunto de datos usando el siguiente código.
Python3
from sklearn.datasets import load_breast_cancer data = load_breast_cancer()
La variable de datos es un tipo de datos personalizado de sklearn.Bunch que se hereda del tipo de datos dict en python. Esta variable de datos tiene atributos que definen los diferentes aspectos del conjunto de datos como se menciona a continuación.
|
Atributo |
Escribe |
Descripción |
|---|---|---|
|
datos |
numpy.ndarray |
Una forma matricial de los valores reales del conjunto de datos almacenados como ndarray de NumPy. |
|
objetivo |
numpy.ndarray |
La lista de valores de la entidad de destino. |
|
nombres_objetivos |
numpy.ndarray |
Los nombres de características para el destino. |
|
DESCR. |
calle |
Descripción del conjunto de datos. |
|
nombres_de_funciones |
numpy.ndarray |
Lista de todos los nombres de características incluidos en el conjunto de datos. |
|
Nombre del archivo |
calle |
El nombre del archivo dentro del conjunto de datos de sklearn al que se hace referencia. |
|
módulo_datos |
calle |
Nombre del módulo de datos desde donde se cargan los datos. |
El siguiente código produce una muestra de los datos del conjunto de datos de cáncer de mama.
Python3
import pandas as pd data_df = pd.DataFrame(data = data.data, columns = data.feature_names) data_df.head().T
Producción:
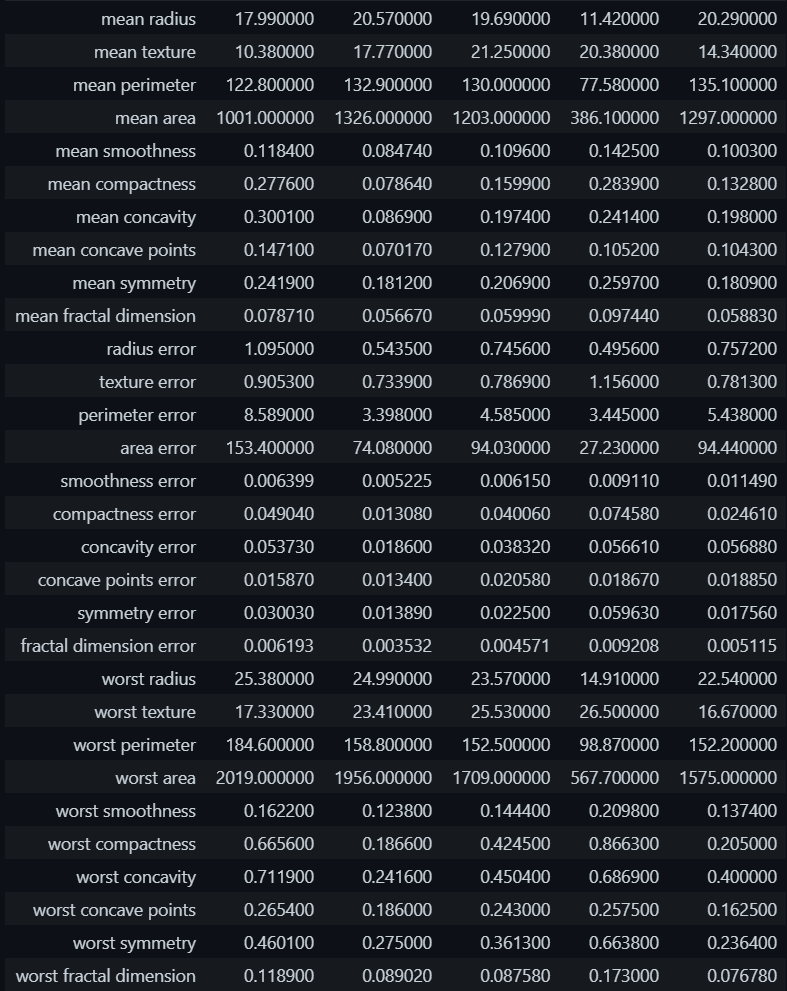
Registros de datos de muestra: conjunto de datos de cáncer de mama
Publicación traducida automáticamente
Artículo escrito por apathak092 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA