En este artículo, vamos a ver cómo podemos realizar el análisis de sentimiento de Twitter sobre la Guerra Rusia-Ucrania usando Python.
El papel de las redes sociales en la opinión pública ha sido profundo y evidente desde que comenzaron a llamar la atención. Las redes sociales nos permiten compartir información en gran capacidad y a gran escala. Justo después de la noticia de una posible guerra entre Rusia y Ucrania, los internautas de todo el mundo comenzaron a inundar la plataforma con sus opiniones. El análisis de estas opiniones puede ayudarnos a comprender el pensamiento del público sobre diferentes eventos antes y durante la guerra. Tomamos tweets con palabras clave de búsqueda relacionadas con la invasión rusa de Ucrania como #UkraineWar #RussiaInvade #StandwithUkraine #UkraineNATO etc. desde enero de 2022 hasta la primera semana de marzo de 2022 con el objetivo de comprender el sentimiento de personas de todo el mundo durante estos eventos.
Primero, para analizar el sentimiento y procesar los datos, necesitaremos importar las siguientes dependencias:
Importación de dependencias
Primero, necesitaremos que se importen las siguientes dependencias.
Python3
# Import Libraries from textblob import TextBlob import sys import matplotlib.pyplot as plt import pandas as pd import numpy as np import os import nltk import re import string import seaborn as sns from PIL import Image from nltk.sentiment.vader import SentimentIntensityAnalyzer from nltk.stem import SnowballStemmer from nltk.sentiment.vader import SentimentIntensityAnalyzer from sklearn.feature_extraction.text import CountVectorizer
Carga de conjunto de datos
El conjunto de datos de tweets de guerra entre Rusia y Ucrania de 65 días está disponible aquí (descarga de conjuntos de datos de kaggle -d foklacu/ukraine-war-tweets-dataset-65-days). Tiene tweets desde el 1 de enero de 2022 hasta el 6 de marzo de 2022. Esta línea de tiempo incluye el período previo y el pico del período de invasión. Este conjunto de datos contiene un máximo de 5000 tweets por día con las siguientes palabras clave de búsqueda ‘Guerra de Ucrania’, ‘Tropas de Ucrania’, ‘Frontera de Ucrania’, ‘OTAN de Ucrania’, ‘StandwithUkraine’, ‘Tropas rusas’, ‘Frontera rusa de Ucrania’, ‘Rusia invade’. El conjunto de datos se divide en 8 archivos de valores separados por comas (CSV) según la palabra clave de búsqueda. Los archivos se extraen y cargan utilizando Pandas Dataframe. El código para cargar el conjunto de datos será:
Python3
# The dataset consists of tweets from
# total 8 hashtags and present in
# separated csv files. All those csv files are loaded.
tweets=pd.read_csv("/dataset/Russia_invade.csv")
tweets=tweets.append(pd.read_csv("/Russian_border_Ukraine.csv"))
tweets=tweets.append(pd.read_csv("/Russian_troops.csv"))
tweets=tweets.append(pd.read_csv("/StandWithUkraine.csv"))
tweets=tweets.append(pd.read_csv("/Ukraine_border.csv"))
tweets=tweets.append(pd.read_csv("/Ukraine_nato.csv"))
tweets=tweets.append(pd.read_csv("/Ukraine_troops.csv"))
tweets=tweets.append(pd.read_csv("/Ukraine_war.csv"))
Entonces, aquí hemos cargado los 8 archivos CSV en un marco de datos de Pandas.
Eliminación de duplicados
Luego, lo más importante fue eliminar los tweets duplicados del conjunto de datos. Los siguientes códigos nos ayudan a hacerlo:
Python3
tweets.drop_duplicates(inplace=True) # remove duplicates
preprocesamiento
La columna de fecha presente en el conjunto de datos tiene fecha y hora. Para los siguientes pasos de procesamiento, es útil eliminar la parte de tiempo correspondiente. Los siguientes códigos ayudarán a hacerlo:
Python3
# slicing the date , and removing the time portion tweets['date'] = tweets.date.str.slice(0, 10)
Ahora, tenemos tweets en 61 idiomas diferentes durante 65 días. Para verificar que podemos usar los siguientes códigos:
Python3
# checking all the unique dates in the dataset print(tweets['date'].unique()) # checking how many unique language # tweets are present in the dataset print(tweets["lang"].unique())
Producción:
['2022-03-05' '2022-03-04' '2022-03-03' '2022-03-02' '2022-03-01' '2022-02-28' '2022-02-27' '2022-02-26' '2022-02-25' '2022-02-24' '2022-02-23' '2022-02-22' '2022-02-21' '2022-02-20' '2022-02-19' '2022-02-18' '2022-02-17' '2022-02-16' '2022-02-15' '2022-02-14' '2022-02-13' '2022-02-12' '2022-02-11' '2022-02-10' '2022-02-09' '2022-02-08' '2022-02-07' '2022-02-06' '2022-02-05' '2022-02-04' '2022-02-03' '2022-02-02' '2022-02-01' '2022-01-31' '2022-01-30' '2022-01-29' '2022-01-28' '2022-01-27' '2022-01-26' '2022-01-25' '2022-01-24' '2022-01-23' '2022-01-22' '2022-01-21' '2022-01-20' '2022-01-19' '2022-01-18' '2022-01-17' '2022-01-16' '2022-01-15' '2022-01-14' '2022-01-13' '2022-01-12' '2022-01-11' '2022-01-10' '2022-01-09' '2022-01-08' '2022-01-07' '2022-01-06' '2022-01-05' '2022-01-04' '2022-01-03' '2022-01-02' '2022-01-01' '2021-12-31']
['en' 'pt' 'zh' 'nl' 'it' 'es' 'de' 'ca' 'cy' 'fr' 'tr' 'ro' 'pl' 'cs' 'ja' 'in' 'hi' 'und' 'sv' 'tl' 'et' 'fi' 'da' 'no' 'el' 'ht' 'ru' 'ar' 'ko' 'fa' 'sl' 'iw' 'dv' 'ta' 'lv' 'pa' 'eu' 'kn' 'ur' 'bn' 'gu' 'uk' 'ne' 'ml' 'sd' 'hu' 'lt' 'my' 'vi' 'te' 'th' 'ka' 'is' 'sr' 'bg' 'am' 'mr' 'si' 'km' 'or' 'ps']
Ahora tomaremos solo los tweets en inglés y eliminaremos todos los tweets que no estén en inglés. El siguiente fragmento de código nos ayudará a hacerlo:
Python3
# before removing the non-english tweets
print(tweets.shape)
# removing all the tweets expect the
# non-english tweets
tweets = tweets[tweets['lang'] == 'en']
print("After removing non-english Tweets")
# only the number of english tweets
print(tweets.shape)
Producción:
(1313818, 29) After removing non-english Tweets (1204218, 29)
Aquí, podemos encontrar que antes teníamos 1313818 tweets y después de eliminar los tweets que no están en inglés tenemos 1204218 tweets.
A continuación, se eliminan las puntuaciones, etiquetas y anotaciones, y todos los textos se convierten a minúsculas para evitar la duplicación de las mismas palabras. A continuación se muestra el fragmento de código utilizado para el mismo:
Python3
# Removing RT, Punctuation etc
def remove_rt(x): return re.sub('RT @\w+: ', " ", x)
def rt(x): return re.sub(
"(@[A-Za-z0-9]+)|([^0-9A-Za-z \t])|(\w+:\/\/\S+)", " ", x)
tweets["content"] = tweets.content.map(remove_rt).map(rt)
tweets["content"] = tweets.content.str.lower()
La comparación de textos antes y después de esta operación –

Análisis de los sentimientos
El procedimiento de análisis de sentimientos incluye recopilar los datos, analizarlos, procesarlos previamente y luego identificar sentimientos, seleccionar características, clasificar sentimientos y eliminar su polaridad y subjetividad. La biblioteca TextBlob se utiliza para analizar el sentimiento de los tweets. Un tweet con una puntuación negativa es mayor que una puntuación positiva, marcado como positivo si es lo contrario y como negativo si no es neutral. Se elimina la cantidad de tweets para cada día único en el conjunto de datos de muestra y luego se calcula la cantidad de tweets con tweets positivos, negativos y neutrales en ese día para averiguar sus porcentajes. Nos ayuda a comprender la reacción de las personas en el día a día. A continuación se muestra el fragmento de código para el mismo
Python3
tweets[['polarity', 'subjectivity']] = tweets['content'].apply( lambda Text: pd.Series(TextBlob(Text).sentiment)) for index, row in tweets['content'].iteritems(): score = SentimentIntensityAnalyzer().polarity_scores(row) neg = score['neg'] neu = score['neu'] pos = score['pos'] comp = score['compound'] if neg > pos: tweets.loc[index, 'sentiment'] = "negative" elif pos > neg: tweets.loc[index, 'sentiment'] = "positive" else: tweets.loc[index, 'sentiment'] = "neutral" tweets.loc[index, 'neg'] = neg tweets.loc[index, 'neu'] = neu tweets.loc[index, 'pos'] = pos tweets.loc[index, 'compound'] = comp
Ahora, si queremos ver los resultados de la operación anterior, podemos usar el siguiente fragmento de código.
Python3
tweets[["content", "sentiment", "polarity", "subjectivity", "neg", "neu", "pos"]].head(5)
Producción:
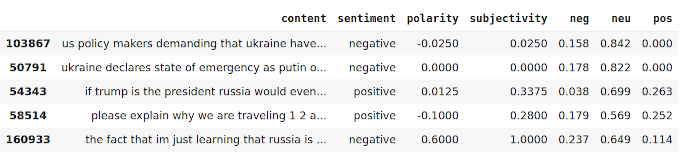
Ahora, para calcular el porcentaje total de tweets positivos, negativos y neutrales, usaremos el siguiente fragmento de código.
Python3
total_pos = len(tweets.loc[tweets['sentiment'] == "positive"])
total_neg = len(tweets.loc[tweets['sentiment'] == "negative"])
total_neu = len(tweets.loc[tweets['sentiment'] == "neutral"])
total_tweets = len(tweets)
print("Total Positive Tweets % : {:.2f}"
.format((total_pos/total_tweets)*100))
print("Total Negative Tweets % : {:.2f}"
.format((total_neg/total_tweets)*100))
print("Total Neutral Tweets % : {:.2f}"
.format((total_neu/total_tweets)*100))
Producción:
Total Positive Tweets % : 31.24 Total Negative Tweets % : 54.97 Total Neutral Tweets % : 13.79
Si queremos mostrar este resultado usando un gráfico circular, podemos hacerlo con la ayuda del siguiente fragmento de código:
Python3
mylabels = ["Positive", "Negative", "Neutral"] mycolors = ["Green", "Red", "Blue"] plt.figure(figsize=(8, 5), dpi=600) # Push new figure on stack myexplode = [0, 0.2, 0] plt.pie([total_pos, total_neg, total_neu], colors=mycolors, labels=mylabels, explode=myexplode) plt.show()
Producción:
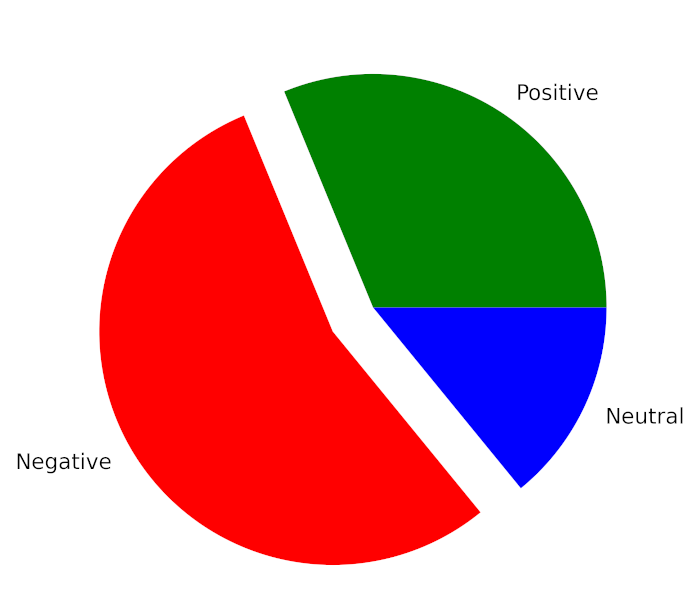
Ahora, si queremos ver los sentimientos durante 65 días, podemos hacerlo con la ayuda del siguiente fragmento de código.
Python3
pos_list = [] neg_list = [] neu_list = [] for i in tweets["date"].unique(): temp = tweets[tweets["date"] == i] positive_temp = temp[temp["sentiment"] == "positive"] negative_temp = temp[temp["sentiment"] == "negative"] neutral_temp = temp[temp["sentiment"] == "neutral"] pos_list.append(((positive_temp.shape[0]/temp.shape[0])*100, i)) neg_list.append(((negative_temp.shape[0]/temp.shape[0])*100, i)) neu_list.append(((neutral_temp.shape[0]/temp.shape[0])*100, i)) neu_list = sorted(neu_list, key=lambda x: x[1]) pos_list = sorted(pos_list, key=lambda x: x[1]) neg_list = sorted(neg_list, key=lambda x: x[1]) x_cord_neg = [] y_cord_neg = [] x_cord_pos = [] y_cord_pos = [] x_cord_neu = [] y_cord_neu = [] for i in neg_list: x_cord_neg.append(i[0]) y_cord_neg.append(i[1]) for i in pos_list: x_cord_pos.append(i[0]) y_cord_pos.append(i[1]) for i in neu_list: x_cord_neu.append(i[0]) y_cord_neu.append(i[1]) plt.figure(figsize=(16, 9), dpi=600) # Push new figure on stack plt.plot(y_cord_neg, x_cord_neg, label="negative", color="red") plt.plot(y_cord_pos, x_cord_pos, label="positive", color="green") plt.plot(y_cord_neu, x_cord_neu, label="neutral", color="blue") plt.xticks(np.arange(0, len(tweets["date"].unique()) + 1, 5)) plt.xticks(rotation=90) plt.grid(axis='x') plt.legend()
Producción:
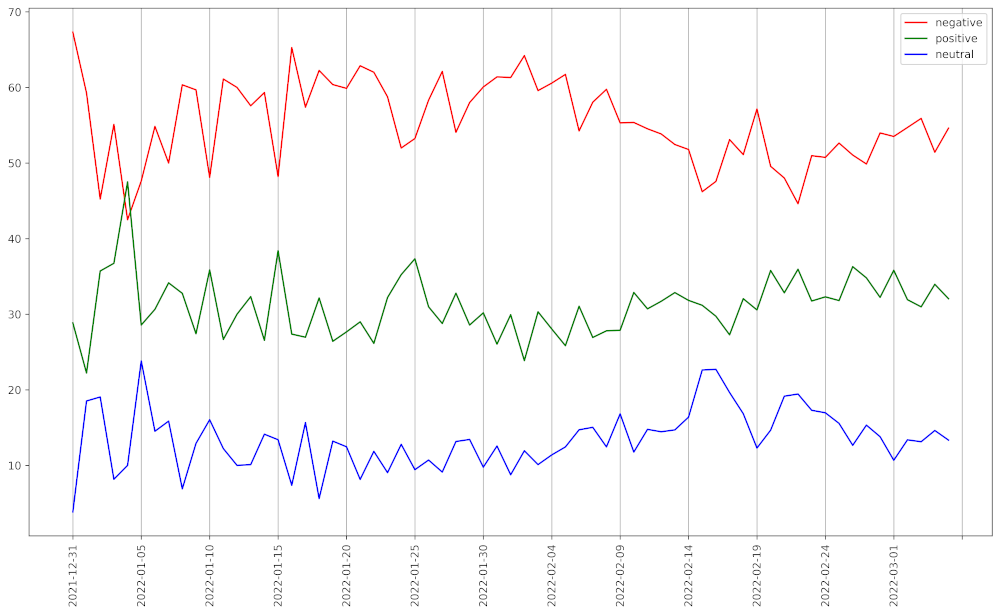
Sentimientos de tweets en una representación gráfica
Popularidad de palabras usando N-gram
Hemos utilizado el módulo de extracción de funciones de Scikit-Learn para encontrar las palabras más populares y un grupo de palabras adyacentes. Aquí obtenemos un modelo de bolsa de palabras después de la tokenización, la eliminación de las palabras vacías y la derivación de textos previamente limpiados. A continuación se muestra el fragmento de código para el mismo:
Python3
# Removing Punctuation
def remove_punct(text):
text = "".join([char for char in text if
char not in string.punctuation])
text = re.sub('[0-9]+', '', text)
return text
tw_list['punct'] = tw_list['content'].apply(
lambda x: remove_punct(x))
# Applying tokenization
def tokenization(text):
text = re.split('\W+', text)
return text
tw_list['tokenized'] = tw_list['punct'].apply(
lambda x: tokenization(x.lower()))
# Removing stopwords
stopword = nltk.corpus.stopwords.words('english')
def remove_stopwords(text):
text = [word for word in text if
word not in stopword]
return text
tw_list['nonstop'] = tw_list['tokenized'].apply(
lambda x: remove_stopwords(x))
# Applying Stemmer
ps = nltk.PorterStemmer()
def stemming(text):
text = [ps.stem(word) for word in text]
return text
tw_list['stemmed'] = tw_list['nonstop'].apply(
lambda x: stemming(x))
tw_list.head()
Producción:
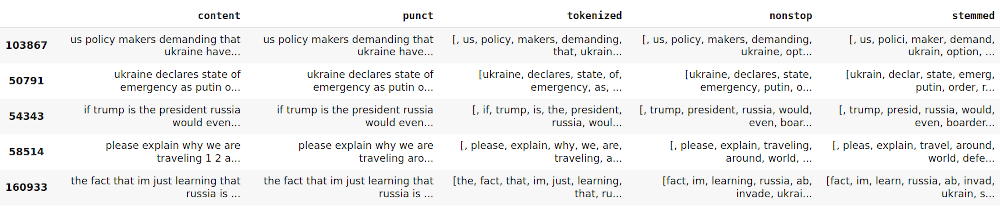
Para encontrar las palabras más utilizadas, primero necesitamos una Bolsa de palabras. Bag of Word es una array donde cada fila representa un texto específico y cada columna representa una palabra del vocabulario. Luego se genera un vector con la suma de cada palabra que aparece en todos los textos. Es decir, se suman los elementos de cada columna de la array Bolsa de Palabras. Por último, se ordena la lista con la palabra y su recuento de ocurrencias. A continuación se muestra el fragmento de código:
Python3
# Applying Countvectorizer countVectorizer = CountVectorizer(analyzer=clean_text) countVector = countVectorizer.fit_transform(tw_list['content']) count_vect_df = pd.DataFrame( countVector.toarray(), columns=countVectorizer.get_feature_names()) count_vect_df.head() # Most Used Words count = pd.DataFrame(count_vect_df.sum()) countdf = count.sort_values(0, ascending=False).head(20) countdf[1:11]
Producción:
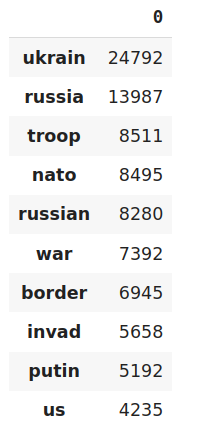
Palabras más usadas
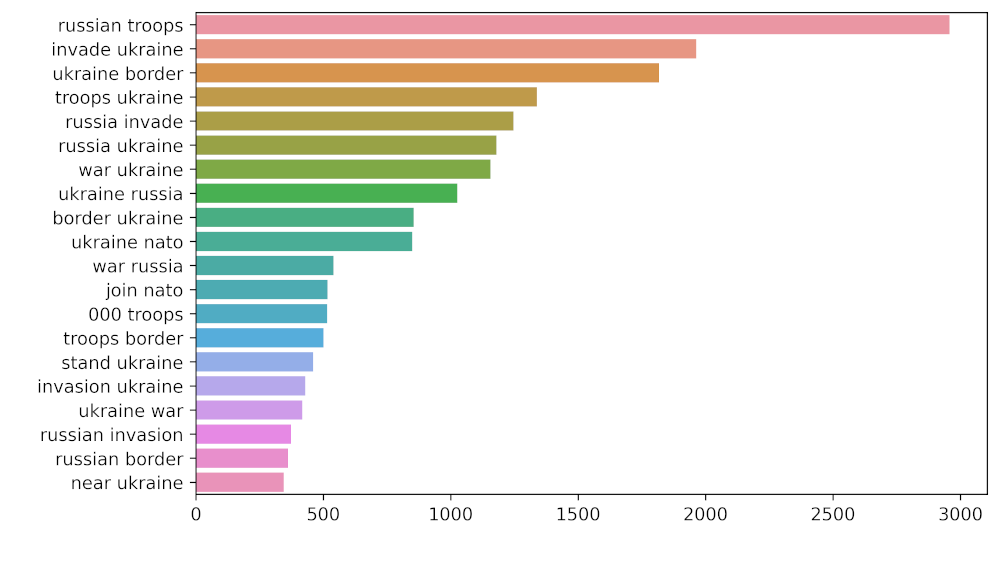
Ahora para averiguar el grupo de palabras adyacentes tomaremos la ayuda de Unigram y Bigram. A continuación se muestra el fragmento de código para el mismo:
Python3
# Function to ngram
def get_top_n_gram(corpus, ngram_range, n=None):
vec = CountVectorizer(ngram_range=ngram_range,
stop_words='english').fit(corpus)
bag_of_words = vec.transform(corpus)
sum_words = bag_of_words.sum(axis=0)
words_freq = [(word, sum_words[0, idx])
for word, idx in vec.vocabulary_.items()]
words_freq = sorted(words_freq, key=lambda x: x[1], reverse=True)
return words_freq[:n]
# n2_bigram
n2_bigrams = get_top_n_gram(tw_list['content'], (2, 2), 20)
plt.figure(figsize=(8, 5),
dpi=600) # Push new figure on stack
sns_plot = sns.barplot(x=1, y=0, data=pd.DataFrame(n2_bigrams))
plt.savefig('bigram.jpg') # Save that figure
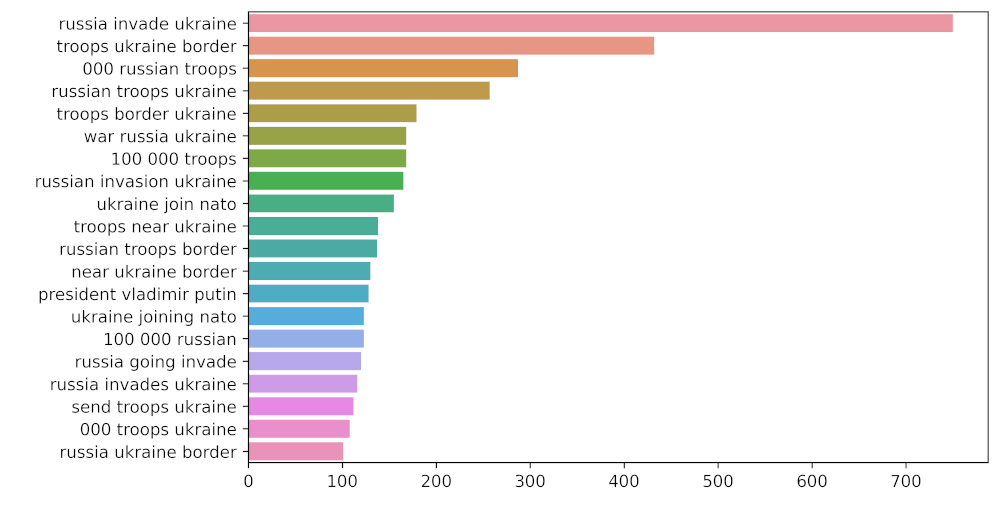
# n3_trigram
n3_trigrams = get_top_n_gram(tw_list['content'], (3, 3), 20)
plt.figure(figsize=(8, 5),
dpi=600) # Push new figure on stack
sns_plot = sns.barplot(x=1, y=0, data=pd.DataFrame(n3_trigrams))
plt.savefig('trigram.jpg') # Save that figure
Producción:
Representación de bigramas
Representación de trigramas
Publicación traducida automáticamente
Artículo escrito por satyajit1910 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA