En este artículo, vamos a ver cómo crear un diagrama de dispersión usando la longitud del sépalo y el ancho del pétalo para separar las clases de especies usando scikit-learn en Python.
El Iris Dataset contiene 50 muestras de tres especies de Iris con cuatro características (largo y ancho de sépalos y pétalos). Iris setosa, Iris virginica e Iris versicolor son las tres especies. Estas medidas se utilizaron para desarrollar un modelo discriminante lineal para clasificar las especies. El conjunto de datos se usa con frecuencia en minería de datos, clasificación, agrupación y prueba de algoritmos.
Ahora, creemos un diagrama de dispersión usando la longitud del sépalo y el ancho de los pétalos para separar las clases de especies usando scikit-learn.
Importar los datos
Primero, importemos los paquetes y carguemos el archivo “ iris.csv” . El método .head() devuelve las primeras cinco filas del conjunto de datos. Las columnas en nuestro conjunto de datos son ‘sepal_length’, ‘sepal_width’, ‘petal_length’, ‘petal_width’ y ‘species’.
Para ver y descargar el archivo csv, haga clic aquí .
Python3
# importing packages
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import preprocessing
import seaborn as sns
# loading data
iris = pd.read_csv("iris.csv")
print(iris.head())
Producción:

Etiqueta que codifica la columna ‘especies’ del conjunto de datos
sklearn.preprocessing.LabelEncoder() convierte las etiquetas de string en etiquetas numéricas. Después de codificar la columna ‘especies’, el conjunto de datos se ve así:
Python3
le = preprocessing.LabelEncoder() # Converting string labels of # the 'species' column into numbers. iris.species = le.fit_transform(iris.species) print(iris.head())
Producción:

Crear un diagrama de dispersión
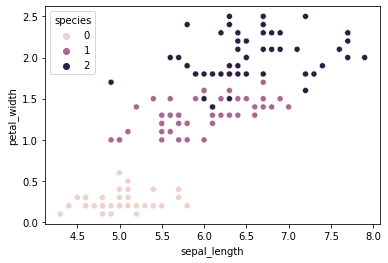
Usamos las bibliotecas matplotlib y seaborn para crear un diagrama de dispersión. sns.scatterplot() se usa para crear un diagrama de dispersión, ya que necesitamos visualizar la longitud de los sépalos y el ancho de los pétalos, en el eje x damos ‘sepal_length’, y en el eje y damos ‘petal_width’, el parámetro hue es para el color en la gráfica, le dimos a la columna el nombre de ‘especies’ para ese parámetro ya que queremos diferenciar los datos entre las especies y la columna ya está codificada en la etiqueta. Las nuevas etiquetas son 0,1,2. En la leyenda, podemos ver eso. Las especies se clasifican en el diagrama de dispersión de acuerdo con las etiquetas.
Python3
# plotting a scatterplot using seaborn sns.scatterplot(data=iris, x='sepal_length', y='petal_width', hue='species') plt.plot()
Producción:
Publicación traducida automáticamente
Artículo escrito por sarahjane3102 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA