En este artículo, veremos el uso en profundidad de tf.keras.layers.Conv2D() en un lenguaje de programación Python.
Red neuronal de convolución: CNN
Computer Vision está cambiando el mundo al entrenar máquinas con grandes datos para imitar la visión humana. Una red neuronal convolucional (CNN) es un tipo específico de red neuronal artificial que utiliza perceptrones/gráficos de computadora, un algoritmo de unidad de aprendizaje automático utilizado para analizar datos. Estos datos involucran principalmente imágenes. Una dimensión vectorial 3D se pasa a través de mapas de características y luego se reduce mediante la técnica de agrupación. La técnica de agrupación ampliamente utilizada para reducir la resolución de los mapas de características de la imagen es MaxPooling y MeanPooling.
Aplicación de CNN:
La red neuronal de convolución se usa ampliamente en la tecnología de visión por computadora , la aplicación principal incluye:
- Detección de objetos
- Clasificación: Predicción del cáncer de mama
- Segmentación Semántica
- conducción autónoma
- control de probabilidad
Implementación de CNN en Keras: tk.keras.layers.Conv2D()
Estructura de clases de Conv2D:
tf.keras.layers.Conv2D(filters, kernel_size, strides=(1, 1), padding=”valid”, data_format=Ninguno, dilation_rate=(1, 1), grupos=1, activación=Ninguno, use_bias=True, kernel_initializer=”glorot_uniform”, bias_initializer=”ceros”, kernel_regularizer=Ninguno, bias_regularizer=Ninguno, activity_regularizer=Ninguno, kernel_constraint=Ninguno, bias_constraint=Ninguno, **kwargs)
Los argumentos de uso común de tk.keras.layers.Conv2D() filtros, kernel_size, strides, padding, activación.
|
Argumentos |
Sentido |
|---|---|
| filtros | El número de filtros de salida en la convolución, es decir, mapas de características totales |
| kernel_size | Una tupla o un valor entero que especifica la altura y el ancho de la ventana de convolución 2D |
| zancadas | Un entero o tupla/lista de 2 enteros, especificando los pasos de la convolución junto con la altura y el ancho. |
| relleno | «válido» significa sin relleno. «igual» significa que la salida tiene el mismo tamaño que la entrada. |
| activación | Funciones no lineales [relu, softmax, sigmoid, tanh] |
| use_bias | Booleano, si la capa usa un vector de sesgo. |
| tasa_de_dilatación | un número entero o tupla/lista de 2 números enteros, especificando la tasa de dilatación a usar para la convolución dilatada. |
| kernel_initializer | El valor predeterminado es ‘glorot_uniform’. |
| bias_initializer | El inicializador para el vector de polarización. |
| kernel_constraint | Función de restricción aplicada a la array kernel |
| restricción_sesgo | Función de restricción aplicada al vector de sesgo |
Red neuronal de convolución usando Tensorflow:
La red neuronal de convolución es un algoritmo de aprendizaje profundo ampliamente utilizado. El propósito principal de usar CNN es reducir la forma de entrada. En el siguiente ejemplo, tomamos píxeles de imagen de 4 dimensiones con un número total de 50 datos de imágenes de 64 píxeles. Como sabemos que una imagen está hecha de tres colores, es decir, RGB, el valor 4 3 denota una imagen en color.
Al pasar el píxel de la imagen de entrada a Conv2D, reduce el tamaño de entrada.
Ejemplo:
Python3
import tensorflow as tf import tensorflow.keras as keras image_pixel = (50,64,64,3) cnn_feature = tf.random.normal(image_pixel) cnn_label = keras.layers.Conv2D(2, 3, activation='relu', input_shape=image_pixel[1:])( cnn_feature) print(cnn_label.shape)
Producción:
(50, 62, 62, 2)
Al proporcionar un argumento de relleno como el mismo, el tamaño de entrada seguirá siendo el mismo.
Python3
image_pixel = (50, 64, 64, 3) cnn_feature = tf.random.normal(image_pixel) cnn_label = keras.layers.Conv2D( 2, 3, activation='relu', padding="same", input_shape=image_pixel[1:])(cnn_feature) print(cnn_label.shape)
Producción:
(50, 64, 64, 2)
El tamaño de píxel no cambia, ya que hemos proporcionado relleno para que sea el mismo.
Implementando el modelo keras.layers.Conv2D():
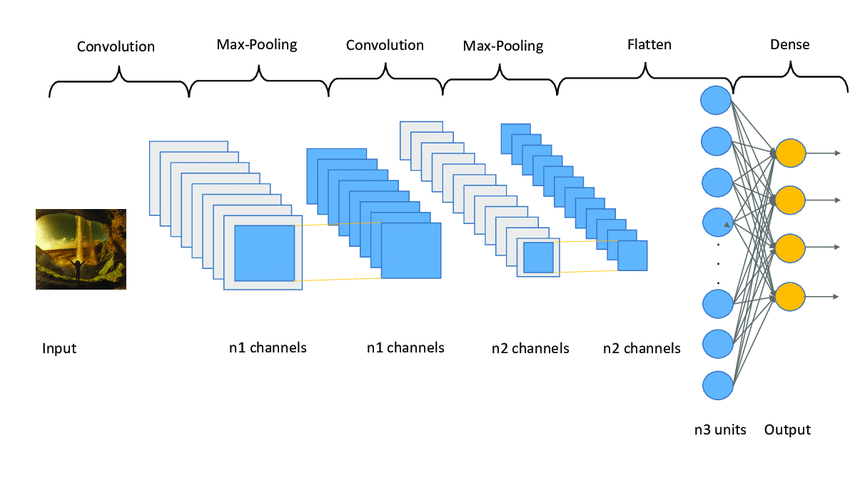
Poner en práctica todo lo aprendido hasta ahora. Primero, creamos un modelo secuencial de Keras y creamos una capa de convolución con 32 mapas de características en tamaño (3,3). Relu es la activación que se utiliza y luego se reduce la muestra de los datos mediante el uso de la técnica MaxPooling. Reducimos aún más la imagen pasándola a través de la segunda capa de Convolución con 64 mapas de características. Este proceso se llama Extracción de características. Una vez que se realiza la extracción de características, podemos aplanar los datos en un solo vector y alimentarlos a capas densas ocultas. La activación de softmax se usa en la capa de salida para asegurarse de que estas salidas sean del tipo de datos categóricos, lo que es útil para la clasificación de imágenes.
Python3
import tensorflow.keras as keras def build_model(): model = keras.Sequential( [ # first convolution layer keras.layers.Conv2D(32, (3, 3), activation="relu", input_shape=(32, 32, 3)), keras.layers.MaxPooling2D((2, 2), strides=2), # second convolution layer keras.layers.Conv2D(64, (3, 3), activation="relu"), keras.layers.MaxPooling2D((2, 2), strides=2), # fully connected classification # single vector keras.layers.Flatten(), # hidden layer and output layer keras.layers.Dense(1024, activation="relu"), keras.layers.Dense(10, activation="softmax") ]) return model
Producción:
<keras.engine.sequential.Sequential object at 0x7f436e8bc2b0>