Para encontrar una salida numérica, se utiliza la predicción. El conjunto de datos de entrenamiento contiene las entradas y los valores numéricos de salida. De acuerdo con el conjunto de datos de entrenamiento, el algoritmo genera un modelo o predictor. Cuando se proporcionan datos nuevos, el modelo debe encontrar una salida numérica. Este enfoque, a diferencia de la clasificación, no tiene una etiqueta de clase. El modelo predice una función de valor continuo o un valor ordenado.
En la mayoría de los casos, la regresión se utiliza para hacer predicciones. Por ejemplo: Predecir el valor de una casa en función de hechos como el número de habitaciones, el área total, etc.
Considere el siguiente escenario: un gerente de marketing necesita pronosticar cuánto gastará un consumidor específico durante una venta. En este escenario, nos molestamos en pronosticar un valor numérico. En esta situación, se construirá un modelo o predictor que pronostique una función de valor continua u ordenada.
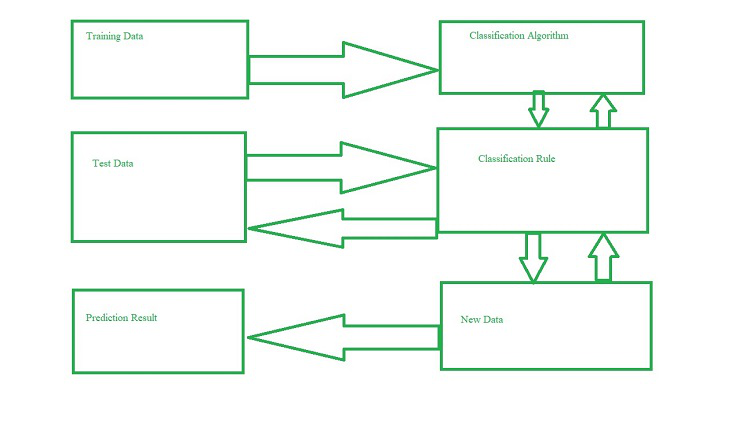
Problemas de predicción:
Preparar los datos para la predicción es el desafío más apremiante. Las siguientes actividades están involucradas en la preparación de datos:
- Limpieza de datos: la limpieza de datos incluye la reducción del ruido y el tratamiento de los valores faltantes. Las técnicas de suavizado eliminan el ruido, y el problema de los valores faltantes se resuelve reemplazando un valor faltante con el valor que ocurre con más frecuencia para esa característica.
- Análisis de relevancia: los atributos irrelevantes también pueden estar presentes en la base de datos. El método de análisis de correlación se utiliza para determinar si dos atributos están conectados.
- Transformación y reducción de datos: cualquiera de los métodos enumerados a continuación se puede utilizar para transformar los datos.
- Normalización: La normalización se utiliza para transformar los datos. La normalización es el proceso de escalar todos los valores de un atributo dado para que se encuentren dentro de un rango estrecho. Cuando se utilizan redes neuronales o métodos que requieren mediciones en el proceso de aprendizaje, se realiza la normalización.
- Generalización: Los datos también se pueden modificar aplicándoles una idea superior. Podemos usar el concepto de jerarquías para esto.
Otras técnicas de reducción de datos incluyen el procesamiento de ondículas, el binning, el análisis de histogramas y el agrupamiento.
Publicación traducida automáticamente
Artículo escrito por premansh2001 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA