Problema con capas de convolución simple
- Para una imagen en escala de grises (nxn) y un filtro/núcleo (fxf), las dimensiones de la imagen resultantes de una operación de convolución son (n – f + 1) x (n – f + 1) .
Por ejemplo, para una imagen (8 x 8) y un filtro (3 x 3), la salida resultante después de la operación de convolución sería de tamaño (6 x 6). Por lo tanto, la imagen se encoge cada vez que se realiza una operación de convolución. Esto establece un límite superior al número de veces que se puede realizar una operación de este tipo antes de que la imagen se reduzca a nada, lo que nos impide construir redes más profundas. - Además, los píxeles de las esquinas y los bordes se usan mucho menos que los del medio.
Por ejemplo,
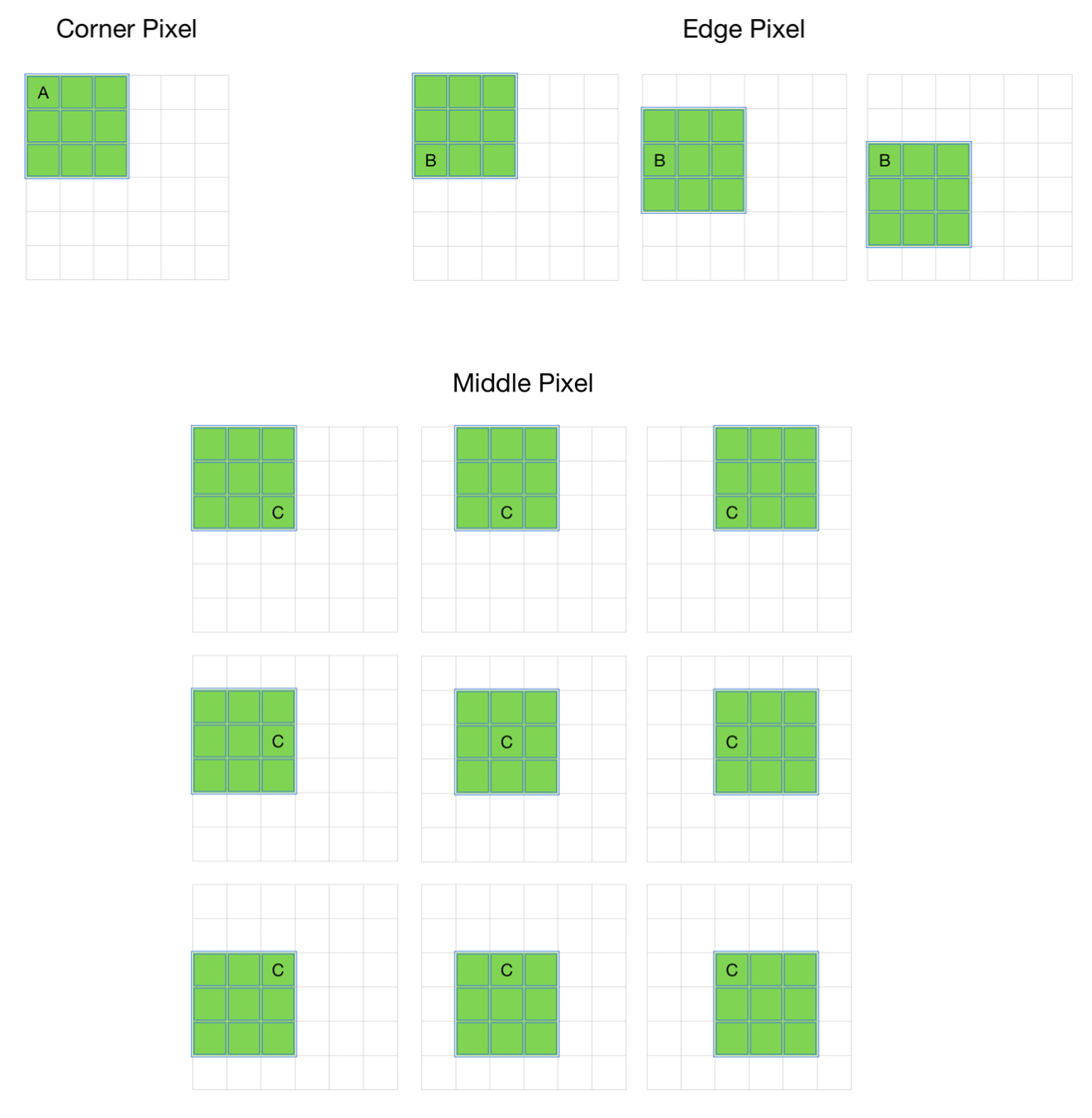
- Claramente, el píxel A se toca en una sola operación de convolución y el píxel B se toca en 3 operaciones de convolución, mientras que el píxel C se toca en 9 operaciones de convolución. En general, los píxeles en el medio se usan con más frecuencia que los píxeles en las esquinas y los bordes. En consecuencia, la información de los bordes de las imágenes no se conserva tan bien como la información del medio.
Imágenes de entrada de relleno
El relleno es simplemente un proceso de agregar capas de ceros a nuestras imágenes de entrada para evitar los problemas mencionados anteriormente.
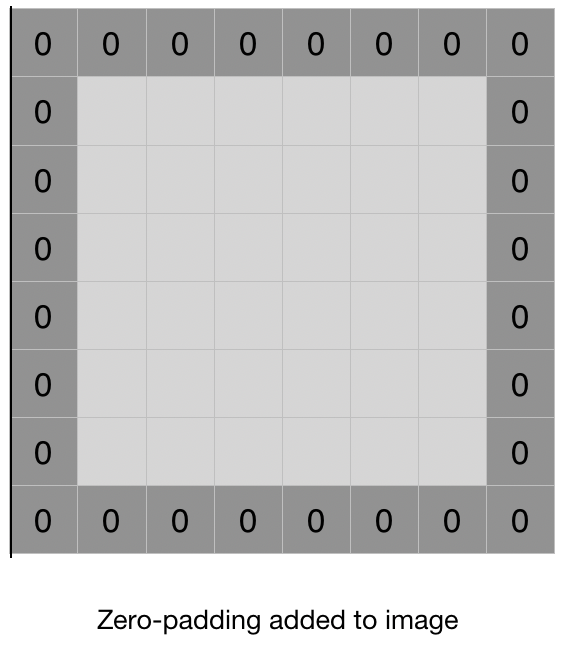
- Esto evita la reducción ya que, si p = número de capas de ceros agregadas al borde de la imagen, entonces nuestra imagen (nxn) se convierte en imagen (n + 2p) x (n + 2p) después del relleno. Por lo tanto, aplicar la operación de convolución (con filtro (fxf)) da como resultado (n + 2p – f + 1) x (n + 2p – f + 1) imágenes. Por ejemplo, al agregar una capa de relleno a una imagen (8 x 8) y usar un filtro (3 x 3), obtendríamos una salida (8 x 8) después de realizar la operación de convolución.
- Esto aumenta la contribución de los píxeles en el borde de la imagen original al colocarlos en el centro de la imagen rellena. Por lo tanto, se conserva la información de los bordes, así como la información en el centro de la imagen.
- Relleno válido: implica ningún relleno en absoluto. La imagen de entrada se deja en su forma válida/inalterada.
Asi que,
- Relleno válido: implica ningún relleno en absoluto. La imagen de entrada se deja en su forma válida/inalterada.
[(nxn) imagen] * [(fxf) filtro] —> [(n – f + 1) x (n – f + 1) imagen]
-
donde * representa una operación de convolución.
- Mismo relleno: en este caso, agregamos capas de relleno ‘p’ de modo que la imagen de salida tenga las mismas dimensiones que la imagen de entrada.
Asi que,
[(n + 2p) x (n + 2p) imagen] * [(fxf) filtro] —> [(nxn) imagen]
-
lo que da p = (f – 1) / 2 (porque n + 2p – f + 1 = n).Entonces, si usamos un filtro (el 3 x 3), la capa 1 de ceros debe agregarse a los bordes para el mismo relleno. De manera similar, si se usa el filtro (5 x 5), se deben agregar 2 capas de ceros al borde de la imagen.
Publicación traducida automáticamente
Artículo escrito por savyakhosla y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA