Nosotros, los humanos, somos muy perfectos en la aplicación de la transferencia de conocimiento entre tareas. Esto significa que siempre que nos encontramos con un nuevo problema o una nueva tarea, lo reconocemos y aplicamos nuestro conocimiento relevante de nuestras experiencias de aprendizaje anteriores. Esto hace que nuestro trabajo sea fácil y rápido de terminar. Por ejemplo, si sabes andar en bicicleta y si te piden que montes una moto que nunca antes has hecho. En tal caso, nuestra experiencia con una bicicleta entrará en juego y manejará tareas como equilibrar la bicicleta, dirección, etc. Esto facilitará las cosas en comparación con un principiante completo. Tales inclinaciones son muy útiles en la vida real, ya que nos hacen más perfectos y nos permiten ganar más experiencia. Siguiendo el mismo enfoque, se introdujo un término Transferencia de aprendizajeen el campo del aprendizaje automático. Este enfoque implica el uso del conocimiento que se aprendió en alguna tarea y aplicarlo para resolver el problema en la tarea objetivo relacionada. Si bien la mayor parte del aprendizaje automático está diseñado para abordar una sola tarea, el desarrollo de algoritmos que facilitan el aprendizaje por transferencia es un tema de interés constante en la comunidad de aprendizaje automático.
¿Por qué transferir el aprendizaje?
Muchas redes neuronales profundas entrenadas en imágenes tienen un fenómeno curioso en común: en las primeras capas de la red, un modelo de aprendizaje profundo intenta aprender un nivel bajo de características, como detectar bordes, colores, variaciones de intensidades, etc. Este tipo de Las características parecen no ser específicas para un conjunto de datos o una tarea en particular porque no importa qué tipo de imagen estemos procesando para detectar un león o un automóvil. En ambos casos, tenemos que detectar estas características de bajo nivel. Todas estas características ocurren independientemente de la función de costo exacta o el conjunto de datos de imágenes. Por lo tanto, el aprendizaje de estas características en una tarea de detección de leones se puede utilizar en otras tareas como la detección de humanos.
Necesidad de transferencia de aprendizaje: las características de bajo nivel aprendidas para la tarea A deberían ser beneficiosas para el aprendizaje del modelo para la tarea B.
Esto es lo que es el aprendizaje por transferencia. Hoy en día, es muy difícil ver personas entrenando redes neuronales convolucionales completas desde cero, y es común usar un modelo preentrenado entrenado en una variedad de imágenes en una tarea similar, por ejemplo, modelos entrenados en ImageNet (1,2 millones de imágenes con 1000.
El diagrama de bloques se muestra a continuación de la siguiente manera:
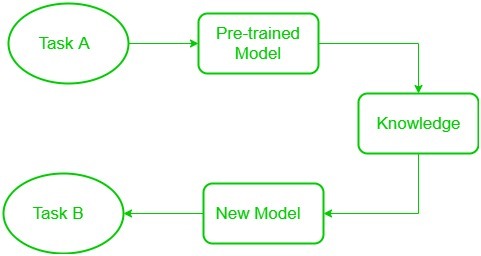
categorías) y utilizar funciones de ellos para resolver una nueva tarea. Cuando se trata de transferencia de aprendizaje, nos encontramos con un fenómeno llamado congelación de capas. Se dice que una capa, puede ser una capa CNN, una capa oculta, un bloque de capas o cualquier subconjunto de un conjunto de todas las capas, está fija cuando ya no está disponible para entrenar. Por lo tanto, los pesos de las capas congeladas no se actualizarán durante el entrenamiento. Mientras que las capas que no se congelan siguen el procedimiento de entrenamiento regular. Cuando usamos el aprendizaje por transferencia para resolver un problema, seleccionamos un modelo previamente entrenado como nuestro modelo base. Ahora, hay dos enfoques posibles para usar el conocimiento del modelo pre-entrenado. La primera forma es congelar algunas capas del modelo previamente entrenado y entrenar otras capas en nuestro nuevo conjunto de datos para la nueva tarea. La segunda forma es hacer un nuevo modelo, pero también elimine algunas características de las capas en el modelo previamente entrenado y utilícelas en un modelo recién creado. En ambos casos, eliminamos algunas de las funciones aprendidas e intentamos entrenar el resto del modelo. Esto asegura que la única característica que puede ser igual en ambas tareas se elimine del modelo previamente entrenado, y el resto del modelo se cambie para adaptarse al nuevo conjunto de datos mediante el entrenamiento.
Capas congeladas y entrenables:
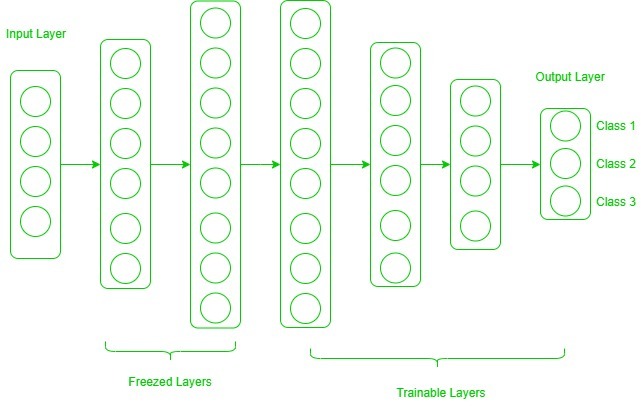
Ahora, uno puede preguntarse cómo determinar qué capas necesitamos congelar y qué capas debemos entrenar. La respuesta es simple, cuanto más desee heredar características de un modelo previamente entrenado, más tendrá que congelar capas. Por ejemplo, si el modelo preentrenado detecta algunas especies de flores y necesitamos detectar algunas especies nuevas. En tal caso, un nuevo conjunto de datos con nuevas especies contiene muchas características similares al modelo preentrenado. Por lo tanto, congelamos menos capas para que podamos usar la mayor parte de su conocimiento en un nuevo modelo. Ahora, considere otro caso, si hay un modelo pre-entrenado que detecta humanos en imágenes, y queremos usar ese conocimiento para detectar autos, en tal caso donde el conjunto de datos es completamente diferente, no es bueno congelar muchas capas porque congelar una gran cantidad de capas no solo brindará características de bajo nivel sino también características de alto nivel como la nariz, los ojos, etc., que son inútiles para un nuevo conjunto de datos (detección de automóviles). Por lo tanto, solo copiamos características de bajo nivel de la red base y entrenamos toda la red en un nuevo conjunto de datos. Consideremos todas las situaciones en las que el tamaño y el conjunto de datos de la tarea de destino varían de la red base.
El conjunto de datos de destino es pequeño y similar al conjunto de datos de la red base: dado que el conjunto de datos de destino es pequeño, eso significa que podemos ajustar la red preentrenada con el conjunto de datos de destino. Pero esto puede conducir a un problema de sobreajuste. Además, puede haber algunos cambios en el número de clases en la tarea de destino. Entonces, en tal caso, eliminamos las capas completamente conectadas del final, tal vez una o dos, y agregamos una nueva capa completamente conectada que satisfaga la cantidad de clases nuevas. Ahora, congelamos el resto del modelo y solo entrenamos las capas recién agregadas.
El conjunto de datos de destino es grande y similar al conjunto de datos de entrenamiento base: en tal caso, cuando el conjunto de datos es grande y puede contener un modelo previamente entrenado, no habrá posibilidad de sobreajuste. Aquí, también se elimina la última capa totalmente conectada y se agrega una nueva capa totalmente conectada con el número adecuado de clases. Ahora, todo el modelo se entrena en un nuevo conjunto de datos. Esto asegura ajustar el modelo en un nuevo conjunto de datos grande manteniendo la misma arquitectura del modelo.
El conjunto de datos de destino es pequeño y diferente del conjunto de datos de la red base: dado que el conjunto de datos de destino es diferente, no será útil usar características de alto nivel del modelo entrenado previamente. En tal caso, elimine la mayoría de las capas del final en un modelo previamente entrenado y agregue nuevas capas la cantidad satisfactoria de clases en un nuevo conjunto de datos. De esta manera, podemos usar funciones de bajo nivel del modelo preentrenado y entrenar el resto de las capas para que se ajusten a un nuevo conjunto de datos. A veces, es beneficioso entrenar toda la red después de agregar una nueva capa al final.
El conjunto de datos de destino es grande y diferente del conjunto de datos de la red base: dado que la red de destino es grande y diferente, la mejor manera es eliminar las últimas capas de la red preentrenada y agregar capas con un número satisfactorio de clases, luego entrenar toda la red sin congelando cualquier capa.
Transferir el aprendizaje es una forma muy eficaz y rápida, para empezar, un problema. Da la dirección para moverse, y la mayoría de las veces los mejores resultados también se obtienen mediante el aprendizaje por transferencia.
A continuación se muestra el código de muestra que utiliza Keras para el aprendizaje y el ajuste fino de Transfer con un bucle de entrenamiento personalizado.
Publicación traducida automáticamente
Artículo escrito por VikashChouhan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA