Google creó un enfoque de aprendizaje automático basado en transformadores para el procesamiento previo del lenguaje natural llamado Representaciones de codificador bidireccional de transformadores. Tiene una gran cantidad de parámetros, por lo tanto, entrenarlo en un pequeño conjunto de datos conduciría a un sobreajuste. Es por eso que usamos un modelo BERT pre-entrenado que ha sido entrenado en un gran conjunto de datos. Usar el modelo previamente entrenado e intentar «ajustarlo» para el conjunto de datos actual, es decir, transferir el aprendizaje, desde ese gran conjunto de datos a nuestro conjunto de datos, para que podamos «afinar» BERT desde ese punto en adelante.
En este artículo, ajustaremos el BERT agregando algunas capas de red neuronal por nuestra cuenta y congelando las capas reales de la arquitectura BERT. La declaración del problema que estamos tomando aquí sería clasificar las oraciones en POSITIVAS y NEGATIVAS mediante el uso del modelo BERT ajustado.
Preparando el conjunto de datos
Enlace para el conjunto de datos.
La columna de oración tiene texto y la columna de etiqueta tiene el sentimiento del texto: 0 para negativo y 1 para positivo. Primero cargamos el conjunto de datos seguido de un preprocesamiento antes de ajustar el modelo.
Cargando conjunto de datos
Python
import pandas as pd
import numpy as np
df = pd.read_csv('/content/data.csv')
Conjunto de datos dividido:
Después de cargar los datos, divídalos en tren, validación y datos de prueba. Estamos tomando la proporción de 70:15:15 para esta división. La función incorporada de sklearn se utiliza a continuación para dividir los datos. Usamos atributos estratificados para garantizar que la proporción de las categorías permanezca igual después de dividir los datos.
Python
from sklearn.model_selection import train_test_split train_text, temp_text, train_labels, temp_labels = train_test_split(df['sentence'], df['label'], random_state = 2021, test_size = 0.3, stratify = df['label']) val_text, test_text, val_labels, test_labels = train_test_split(temp_text, temp_labels, random_state = 2021, test_size = 0.5, stratify = temp_labels)
Cargue el tokenizador y el modelo BERT preentrenados
A continuación, procedemos a cargar el tokenizador y el modelo BERT previamente entrenados. Usaríamos el tokenizador para convertir el texto en un formato (que tiene identificadores de entrada, máscaras de atención) que se puede enviar al modelo.
Python
#load model and tokenizer
bert = AutoModel.from_pretrained('bert-base-uncased')
tokenizer = BertTokenizerFast.from_pretrained('bert-base-uncased')
Decidir la longitud del acolchado
Si tomamos la longitud del relleno como la longitud máxima de texto que se encuentra en los textos de entrenamiento, podría dejar los datos de entrenamiento escasos. Tomar la menor longitud conduciría a su vez a la pérdida de información. Por lo tanto, trazaríamos el gráfico y veríamos la longitud «promedio» y la estableceríamos como la longitud de relleno para compensar entre los dos extremos.
Python
train_lens = [len(i.split()) for i in train_text] plt.hist(train_lens)
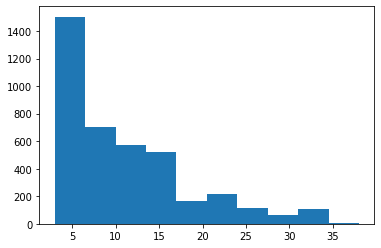
Del gráfico anterior, tomamos 17 como la longitud del relleno.
Tokenizando los datos
Tokenice los datos y codifique las secuencias utilizando el tokenizador BERT.
Python
# tokenize and encode sequences tokens_train = tokenizer.batch_encode_plus( train_text.tolist(), max_length = pad_len, pad_to_max_length = True, truncation = True ) tokens_val = tokenizer.batch_encode_plus( val_text.tolist(), max_length = pad_len, pad_to_max_length = True, truncation = True ) tokens_test = tokenizer.batch_encode_plus( test_text.tolist(), max_length = pad_len, pad_to_max_length = True, truncation = True ) train_seq = torch.tensor(tokens_train['input_ids']) train_mask = torch.tensor(tokens_train['attention_mask']) train_y = torch.tensor(train_labels.tolist()) val_seq = torch.tensor(tokens_val['input_ids']) val_mask = torch.tensor(tokens_val['attention_mask']) val_y = torch.tensor(val_labels.tolist()) test_seq = torch.tensor(tokens_test['input_ids']) test_mask = torch.tensor(tokens_test['attention_mask']) test_y = torch.tensor(test_labels.tolist())
Definición del modelo
Primero congelamos el modelo preentrenado BERT y luego agregamos capas como se muestra en los siguientes fragmentos de código:
Python
#freeze the pretrained layers for param in bert.parameters(): param.requires_grad = False #defining new layers class BERT_architecture(nn.Module): def __init__(self, bert): super(BERT_architecture, self).__init__() self.bert = bert # dropout layer self.dropout = nn.Dropout(0.2) # relu activation function self.relu = nn.ReLU() # dense layer 1 self.fc1 = nn.Linear(768,512) # dense layer 2 (Output layer) self.fc2 = nn.Linear(512,2) #softmax activation function self.softmax = nn.LogSoftmax(dim=1) #define the forward pass def forward(self, sent_id, mask): #pass the inputs to the model _, cls_hs = self.bert(sent_id, attention_mask=mask, return_dict=False) x = self.fc1(cls_hs) x = self.relu(x) x = self.dropout(x) # output layer x = self.fc2(x) # apply softmax activation x = self.softmax(x) return x
Además, agregue un optimizador para mejorar el rendimiento:
Python
optimizer = AdamW(model.parameters(),lr = 1e-5) # learning rate
Luego calcule los pesos de clase y envíelos como parámetros mientras define la función de pérdida para garantizar que el desequilibrio en el conjunto de datos se maneje bien mientras se calcula la pérdida.
Entrenando al modelo
Después de definir el modelo, defina una función para entrenar el modelo (ajuste fino, en este caso):
Python
# function to train the model
def train():
model.train()
total_loss, total_accuracy = 0, 0
# empty list to save model predictions
total_preds=[]
# iterate over batches
for step,batch in enumerate(train_dataloader):
# progress update after every 50 batches.
if step % 50 == 0 and not step == 0:
print(' Batch {:>5,} of {:>5,}.'.format(step, len(train_dataloader)))
# push the batch to gpu
batch = [r.to(device) for r in batch]
sent_id, mask, labels = batch
# clear previously calculated gradients
model.zero_grad()
# get model predictions for the current batch
preds = model(sent_id, mask)
# compute the loss between actual and predicted values
loss = cross_entropy(preds, labels)
# add on to the total loss
total_loss = total_loss + loss.item()
# backward pass to calculate the gradients
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
# update parameters
optimizer.step()
# model predictions are stored on GPU. So, push it to CPU
preds=preds.detach().cpu().numpy()
# append the model predictions
total_preds.append(preds)
# compute the training loss of the epoch
avg_loss = total_loss / len(train_dataloader)
# predictions are in the form of (no. of batches, size of batch, no. of classes).
total_preds = np.concatenate(total_preds, axis=0)
#returns the loss and predictions
return avg_loss, total_preds
Ahora, defina otra función que evalúe el modelo en los datos de validación.
Python
# code
print "GFG"
# function for evaluating the model
def evaluate():
print("\nEvaluating...")
# deactivate dropout layers
model.eval()
total_loss, total_accuracy = 0, 0
# empty list to save the model predictions
total_preds = []
# iterate over batches
for step,batch in enumerate(val_dataloader):
# Progress update every 50 batches.
if step % 50 == 0 and not step == 0:
# # Calculate elapsed time in minutes.
# elapsed = format_time(time.time() - t0)
# Report progress.
print(' Batch {:>5,} of {:>5,}.'.format(step, len(val_dataloader)))
# push the batch to gpu
batch = [t.to(device) for t in batch]
sent_id, mask, labels = batch
# deactivate autograd
with torch.no_grad():
# model predictions
preds = model(sent_id, mask)
# compute the validation loss between actual and predicted values
loss = cross_entropy(preds,labels)
total_loss = total_loss + loss.item()
preds = preds.detach().cpu().numpy()
total_preds.append(preds)
# compute the validation loss of the epoch
avg_loss = total_loss / len(val_dataloader)
# reshape the predictions in form of (number of samples, no. of classes)
total_preds = np.concatenate(total_preds, axis=0)
return avg_loss, total_preds
Probar los datos
Después de ajustar el modelo, pruébelo en el conjunto de datos de prueba. Imprima un informe de clasificación para obtener una mejor imagen del rendimiento del modelo.
Python
# get predictions for test data with torch.no_grad(): preds = model(test_seq.to(device), test_mask.to(device)) preds = preds.detach().cpu().numpy() from sklearn.metrics import classification_report pred = np.argmax(preds, axis = 1) print(classification_report(test_y, pred))
Después de la prueba, obtendríamos los resultados de la siguiente manera:
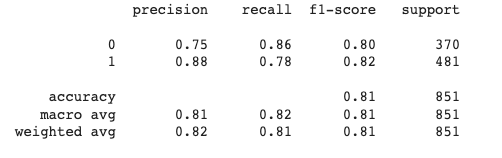
Informe de clasificación
Enlace al código completo.
Referencias:
- https://huggingface.co/docs/transformers/model_doc/bert
- https://huggingface.co/docs/transformers/index
- https://huggingface.co/docs/transformers/custom_datasets
Publicación traducida automáticamente
Artículo escrito por GSSNHimabindu y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA