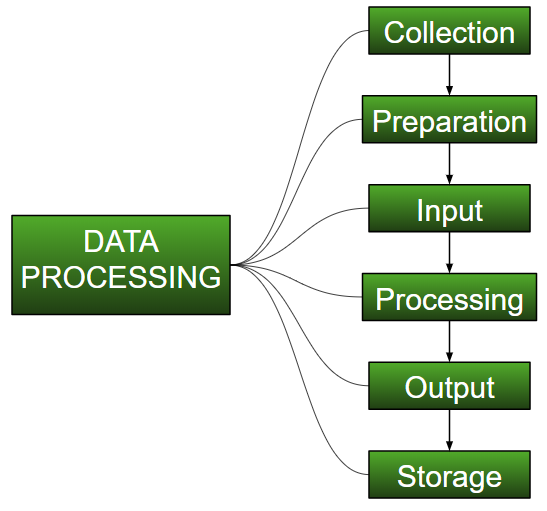
Procesamiento de Datos: Se define como la Recopilación, manipulación y procesamiento de los datos recopilados para el uso requerido. Es una tarea de convertir datos de una forma dada a una forma mucho más utilizable y deseada, es decir, haciéndola más significativa e informativa. Usando algoritmos de Machine Learning, modelado matemático y conocimiento estadístico, todo este proceso puede automatizarse. Esto puede parecer simple, pero cuando se trata de organizaciones realmente grandes como Twitter, Facebook, organismos administrativos como el Parlamento, la UNESCO y organizaciones del sector de la salud, todo este proceso debe realizarse de manera muy estructurada. Entonces, los pasos a realizar son los siguientes:
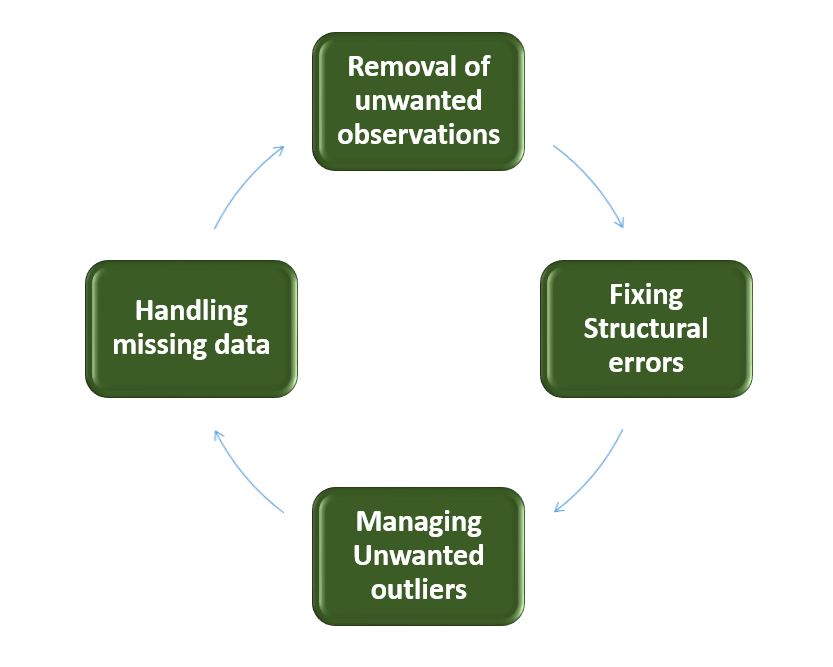
Limpieza de datos: la limpieza de datos es el proceso de corregir o eliminar datos incorrectos, corruptos, con formato incorrecto, duplicados o incompletos dentro de un conjunto de datos. Es una de las partes importantes del aprendizaje automático. Desempeña un papel importante en la construcción de un modelo. La limpieza de datos es una de esas cosas que todos hacen pero de las que nadie habla. Seguramente no es la parte más elegante del aprendizaje automático y, al mismo tiempo, no hay trucos ocultos ni secretos por descubrir. Sin embargo, la limpieza de datos adecuada puede hacer o deshacer su proyecto. Pasos involucrados en la limpieza de datos:
Procesamiento de datos frente a limpieza de datos
| No Señor. |
Procesamiento de datos |
Limpieza de datos |
|---|---|---|
| 1 | El procesamiento de datos se realiza después de la limpieza de datos | La limpieza de datos se realiza antes del procesamiento de datos |
| 2 | El procesamiento de datos requiere el hardware de almacenamiento necesario como RAM, unidades de procesamiento gráfico, etc. para procesar los datos | La limpieza de datos no requiere herramientas de hardware. |
| 3 | Marcos de procesamiento de datos como Hadoop , Pig Frameworks, etc. | La limpieza de datos implica la eliminación de datos ruidosos, etc. No se utilizan marcos especiales. |
| 4 | El procesamiento de datos es difícil en comparación con la limpieza de datos. | La limpieza de datos es más fácil que el procesamiento de datos. |
| 5 |
Ejemplos:
|
Ejemplos:
|
Publicación traducida automáticamente
Artículo escrito por sravankumar8128 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA