En 1991, Turk y Pentland sugirieron un enfoque para el reconocimiento de rostros que utiliza conceptos de álgebra lineal y reducción de dimensionalidad para reconocer rostros. Este enfoque es computacionalmente menos costoso y fácil de implementar y, por lo tanto, se usaba en varias aplicaciones en ese momento, como reconocimiento escrito a mano, lectura de labios, análisis de imágenes médicas, etc.
PCA (Análisis de componentes principales) es una técnica de reducción de dimensionalidad propuesta por Pearson. en 1901. Utiliza valores propios y vectores propios para reducir la dimensionalidad y proyectar una muestra/datos de entrenamiento en un espacio de características pequeño. Veamos el algoritmo con más detalle (en una perspectiva de reconocimiento facial).
Algoritmo de entrenamiento:
- Consideremos un conjunto de m imágenes de dimensión N*N (imágenes de entrenamiento).

Imagen de entrenamiento con True Label (conjunto de datos de personas de LFW)
- Primero convertimos estas imágenes en vectores de tamaño N 2 tales que:
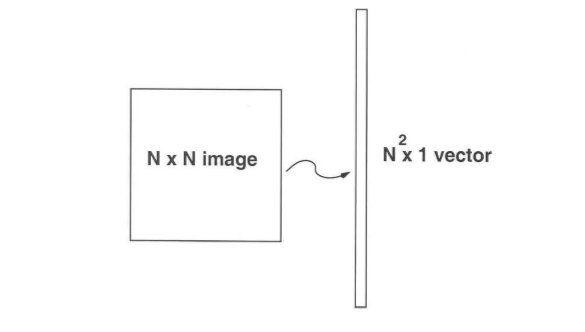

- Ahora calculamos el promedio de todos estos vectores de caras y lo restamos de cada vector


cara_promedio
- Ahora tomamos todos los vectores de caras para obtener una array de tamaño N 2 * M.

- Ahora, encontramos la array de covarianza multiplicando A con A T . A tiene dimensiones N 2 * M , por lo tanto A T tiene dimensiones M * N 2 . Cuando multiplicamos esto nos da una array de N 2 * N 2 , lo que nos da N 2 vectores propios de N 2 tamaño que no es computacionalmente eficiente para calcular. Así que calculamos nuestra array de covarianza multiplicando A T y A . Esto nos da una array M * M que tiene M (suponiendo que M << N 2) vectores propios de tamaño M .

En este paso, calculamos los valores propios y los vectores propios de la array de covarianza anterior utilizando la fórmula a continuación.

donde, y
y
De la declaración anterior se puede concluir que
 y C tienen los mismos valores propios y sus vectores propios están relacionados por la ecuación
y C tienen los mismos valores propios y sus vectores propios están relacionados por la ecuación  . Por lo tanto, los M valores propios (y vectores propios) de la array de covarianza dan los M valores propios (y vectores propios) más grandes de
. Por lo tanto, los M valores propios (y vectores propios) de la array de covarianza dan los M valores propios (y vectores propios) más grandes de- Ahora calculamos el vector propio y los valores propios de esta array de covarianza reducida y los mapeamos usando la fórmula .
- Ahora seleccionamos los vectores propios de K correspondientes a los valores propios más grandes de K (donde K < M). Estos vectores propios tienen tamaño N 2 .
- En este paso usamos los vectores propios que obtuvimos en el paso anterior. Tomamos las caras de entrenamiento normalizadas (cara – cara promedio)
 y representamos cada vector de cara en la combinación lineal de los mejores vectores propios de K (como se muestra en el diagrama a continuación).
y representamos cada vector de cara en la combinación lineal de los mejores vectores propios de K (como se muestra en el diagrama a continuación).
Estos se llaman EigenFaces .
se llaman EigenFaces .

caras propias
- En este paso, tomamos el coeficiente de caras propias y representamos las caras de entrenamiento en forma de un vector de esos coeficientes.


Combinación lineal de caras propias
Algoritmo de prueba/detección:

Imágenes de prueba con etiquetas verdaderas
- Dada una cara desconocida y , primero debemos preprocesar la cara para que quede centrada en la imagen y tenga las mismas dimensiones que la cara de entrenamiento.
- Ahora, restamos la cara de la cara promedio
 .
.

Imágenes de prueba – Imágenes promedio
- Ahora, proyectamos el vector normalizado en el espacio propio para obtener la combinación lineal de caras propias.

- A partir de la proyección anterior, generamos el vector del coeficiente tal que

- Tomamos el vector generado en el paso anterior y lo restamos de la imagen de entrenamiento para obtener la distancia mínima entre los vectores de entrenamiento y los vectores de prueba.
- Si
 está por debajo del nivel de tolerancia T r , entonces se reconoce con l rostro de la imagen de entrenamiento; de lo contrario, el rostro no coincide con ninguno de los rostros del conjunto de entrenamiento.
está por debajo del nivel de tolerancia T r , entonces se reconoce con l rostro de la imagen de entrenamiento; de lo contrario, el rostro no coincide con ninguno de los rostros del conjunto de entrenamiento.


Imágenes de prueba Con predicción
ventajas:
- Fácil de implementar y computacionalmente menos costoso.
- No se requiere conocimiento (como rasgos faciales) de la imagen (excepto identificación).
Limitaciones:
- Se requiere una cara correctamente centrada para el entrenamiento/prueba.
- El algoritmo es sensible a la iluminación, las sombras y también la escala de la cara en la imagen.
- Se requiere una vista frontal de la cara para que este algoritmo funcione correctamente.
Referencia :