La clasificación multiclase es un problema popular en el aprendizaje automático supervisado.
Problema: dado un conjunto de datos de m ejemplos de entrenamiento, cada uno de los cuales contiene información en forma de varias características y una etiqueta. Cada etiqueta corresponde a una clase a la que pertenece el ejemplo de entrenamiento. En la clasificación multiclase, tenemos un conjunto finito de clases. Cada ejemplo de entrenamiento también tiene n características.
Por ejemplo, en el caso de la identificación de diferentes tipos de frutas, se pueden presentar «Forma», «Color», «Radio», y «Manzana», «Naranja», «Plátano» pueden ser etiquetas de clase diferentes.
En una clasificación multiclase, entrenamos un clasificador usando nuestros datos de entrenamiento y usamos este clasificador para clasificar nuevos ejemplos.
Objetivo de este artículo: utilizaremos diferentes métodos de clasificación multiclase, como KNN, árboles de decisión, SVM, etc. Compararemos su precisión en los datos de prueba. Realizaremos todo esto con sci-kit learn (Python). Para obtener información sobre cómo instalar y usar sci-kit learn, visite http://scikit-learn.org/stable/
Acercarse –
- Cargue el conjunto de datos desde la fuente.
- Divida el conjunto de datos en datos de «entrenamiento» y «prueba».
- Entrene clasificadores de árboles de decisión, SVM y KNN en los datos de entrenamiento.
- Utilice los clasificadores anteriores para predecir etiquetas para los datos de prueba.
- Mida la precisión y visualice la clasificación.
Clasificador de árbol de decisión: un clasificador de árbol de decisión es un enfoque sistemático para la clasificación multiclase. Plantea un conjunto de preguntas al conjunto de datos (relacionadas con sus atributos/características). El algoritmo de clasificación del árbol de decisión se puede visualizar en un árbol binario. En la raíz y en cada uno de los Nodes internos, se plantea una pregunta y los datos de ese Node se dividen aún más en registros separados que tienen diferentes características. Las hojas del árbol se refieren a las clases en las que se divide el conjunto de datos. En el siguiente fragmento de código, entrenamos un clasificador de árboles de decisión en scikit-learn.
Python
# importing necessary libraries from sklearn import datasets from sklearn.metrics import confusion_matrix from sklearn.model_selection import train_test_split # loading the iris dataset iris = datasets.load_iris() # X -> features, y -> label X = iris.data y = iris.target # dividing X, y into train and test data X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0) # training a DescisionTreeClassifier from sklearn.tree import DecisionTreeClassifier dtree_model = DecisionTreeClassifier(max_depth = 2).fit(X_train, y_train) dtree_predictions = dtree_model.predict(X_test) # creating a confusion matrix cm = confusion_matrix(y_test, dtree_predictions)
Clasificador
SVM (máquina de vector de soporte): SVM (máquina de vector de soporte) es un método de clasificación eficiente cuando el vector de características es de alta dimensión. En sci-kit learn, podemos especificar la función kernel (aquí, lineal). Para saber más sobre las funciones del núcleo y SVM, consulte – Función del núcleo | sci-kit aprender y SVM .
Python
# importing necessary libraries from sklearn import datasets from sklearn.metrics import confusion_matrix from sklearn.model_selection import train_test_split # loading the iris dataset iris = datasets.load_iris() # X -> features, y -> label X = iris.data y = iris.target # dividing X, y into train and test data X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0) # training a linear SVM classifier from sklearn.svm import SVC svm_model_linear = SVC(kernel = 'linear', C = 1).fit(X_train, y_train) svm_predictions = svm_model_linear.predict(X_test) # model accuracy for X_test accuracy = svm_model_linear.score(X_test, y_test) # creating a confusion matrix cm = confusion_matrix(y_test, svm_predictions)
Clasificador KNN (k-vecinos más cercanos): KNN o k-vecinos más cercanos es el algoritmo de clasificación más simple. Este algoritmo de clasificación no depende de la estructura de los datos. Cada vez que se encuentra un nuevo ejemplo, se examinan sus k vecinos más cercanos de los datos de entrenamiento. La distancia entre dos ejemplos puede ser la distancia euclidiana entre sus vectores de características. La clase mayoritaria entre los k vecinos más cercanos se toma como la clase del ejemplo encontrado.
Python
# importing necessary libraries from sklearn import datasets from sklearn.metrics import confusion_matrix from sklearn.model_selection import train_test_split # loading the iris dataset iris = datasets.load_iris() # X -> features, y -> label X = iris.data y = iris.target # dividing X, y into train and test data X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0) # training a KNN classifier from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier(n_neighbors = 7).fit(X_train, y_train) # accuracy on X_test accuracy = knn.score(X_test, y_test) print accuracy # creating a confusion matrix knn_predictions = knn.predict(X_test) cm = confusion_matrix(y_test, knn_predictions)
Clasificador Naive Bayes: el método de clasificación Naive Bayes se basa en el teorema de Bayes. Se denomina ‘Ingenuo’ porque asume la independencia entre cada par de características en los datos. Sea (x 1 , x 2 , …, x n ) un vector de características y sea y la etiqueta de clase correspondiente a este vector de características.
Aplicando el teorema de Bayes,
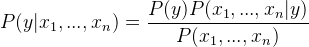
Como x 1 , x 2 , …, x n son independientes entre sí,
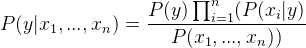
Insertando proporcionalidad quitando la P(x 1 , …, x n ) (ya que es constante).
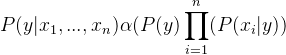
Por lo tanto, la etiqueta de clase se decide por,
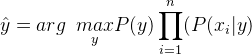
P(y) es la frecuencia relativa de la etiqueta de clase y en el conjunto de datos de entrenamiento.
En el caso del clasificador Gaussian Naive Bayes, P(x i | y) se calcula como,
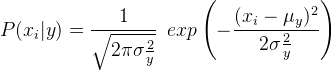
Python
# importing necessary libraries from sklearn import datasets from sklearn.metrics import confusion_matrix from sklearn.model_selection import train_test_split # loading the iris dataset iris = datasets.load_iris() # X -> features, y -> label X = iris.data y = iris.target # dividing X, y into train and test data X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0) # training a Naive Bayes classifier from sklearn.naive_bayes import GaussianNB gnb = GaussianNB().fit(X_train, y_train) gnb_predictions = gnb.predict(X_test) # accuracy on X_test accuracy = gnb.score(X_test, y_test) print accuracy # creating a confusion matrix cm = confusion_matrix(y_test, gnb_predictions)
Referencias –
- http://scikit-learn.org/stable/modules/naive_bayes.html
- https://en.wikipedia.org/wiki/Multiclass_classification
- http://scikit-learn.org/stable/documentation.html
- http://scikit-learn.org/stable/modules/tree.html
- http://scikit-learn.org/stable/modules/svm.html#svm-kernels
- https://www.analyticsvidhya.com/blog/2015/10/understaing-support-vector-machine-example-code/
Este artículo es una contribución de Arik Pamnani . Si te gusta GeeksforGeeks y te gustaría contribuir, también puedes escribir un artículo usando write.geeksforgeeks.org o enviar tu artículo por correo a review-team@geeksforgeeks.org. Vea su artículo que aparece en la página principal de GeeksforGeeks y ayude a otros Geeks.
Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA