Requisitos previos: Introducción a la PNL
Siempre que tengamos datos textuales, debemos aplicar varios pasos de preprocesamiento a los datos para transformar las palabras en características numéricas que funcionan con algoritmos de aprendizaje automático. Los pasos de preprocesamiento de un problema dependen principalmente del dominio y del problema en sí, por lo tanto, no es necesario aplicar todos los pasos a todos los problemas.
En este artículo, vamos a ver el preprocesamiento de texto en Python. Usaremos la biblioteca NLTK (Natural Language Toolkit) aquí.
Python3
# import the necessary libraries import nltk import string import re
Texto en minúsculas:
Ponemos en minúsculas el texto para reducir el tamaño del vocabulario de nuestros datos de texto.
Python3
def text_lowercase(text): return text.lower() input_str = "Hey, did you know that the summer break is coming? Amazing right !! It's only 5 more days !!" text_lowercase(input_str)
Ejemplo:
Entrada: “Oye, ¿sabías que se acercan las vacaciones de verano? Impresionante verdad!! ¡¡Son solo 5 días más!!”
Salida: “oye, ¿sabías que se acerca el receso de verano? espectacular verdad!! ¡¡Solo son 5 días más!!”
Eliminar números:
Podemos eliminar números o convertir los números en sus representaciones textuales.
Podemos usar expresiones regulares para eliminar los números.
Python3
# Remove numbers def remove_numbers(text): result = re.sub(r'\d+', '', text) return result input_str = "There are 3 balls in this bag, and 12 in the other one." remove_numbers(input_str)
Ejemplo:
Entrada: «Hay 3 bolas en esta bolsa y 12 en la otra».
Salida: ‘Hay pelotas en esta bolsa y en la otra.’
También podemos convertir los números en palabras. Esto se puede hacer usando la biblioteca inflect.
Python3
# import the inflect library import inflect p = inflect.engine() # convert number into words def convert_number(text): # split string into list of words temp_str = text.split() # initialise empty list new_string = [] for word in temp_str: # if word is a digit, convert the digit # to numbers and append into the new_string list if word.isdigit(): temp = p.number_to_words(word) new_string.append(temp) # append the word as it is else: new_string.append(word) # join the words of new_string to form a string temp_str = ' '.join(new_string) return temp_str input_str = 'There are 3 balls in this bag, and 12 in the other one.' convert_number(input_str)
Ejemplo:
Entrada: «Hay 3 bolas en esta bolsa y 12 en la otra».
Resultado: «Hay tres bolas en esta bolsa y doce en la otra».
Eliminar puntuación:
Eliminamos los signos de puntuación para no tener diferentes formas de la misma palabra. Si no eliminamos la puntuación, entonces estado. sido, sido! serán tratados por separado.
Python3
# remove punctuation
def remove_punctuation(text):
translator = str.maketrans('', '', string.punctuation)
return text.translate(translator)
input_str = "Hey, did you know that the summer break is coming? Amazing right !! It's only 5 more days !!"
remove_punctuation(input_str)
Ejemplo:
Entrada: “Oye, ¿sabías que se acercan las vacaciones de verano? Impresionante verdad!! ¡¡Son solo 5 días más!!”
Salida: «Oye, ¿sabías que se acercan las vacaciones de verano? Increíble, solo son 5 días más».
Eliminar espacios en blanco:
Podemos usar la función de unir y dividir para eliminar todos los espacios en blanco en una string.
Python3
# remove whitespace from text def remove_whitespace(text): return " ".join(text.split()) input_str = " we don't need the given questions" remove_whitespace(input_str)
Ejemplo:
Input: " we don't need the given questions" Output: "we don't need the given questions"
Eliminar palabras vacías predeterminadas:
Las palabras vacías son palabras que no contribuyen al significado de una oración. Por lo tanto, pueden eliminarse con seguridad sin causar ningún cambio en el significado de la oración. La biblioteca NLTK tiene un conjunto de palabras vacías y podemos usarlas para eliminar palabras vacías de nuestro texto y devolver una lista de tokens de palabras.

Python3
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
# remove stopwords function
def remove_stopwords(text):
stop_words = set(stopwords.words("english"))
word_tokens = word_tokenize(text)
filtered_text = [word for word in word_tokens if word not in stop_words]
return filtered_text
example_text = "This is a sample sentence and we are going to remove the stopwords from this."
remove_stopwords(example_text)
Ejemplo:
Entrada: «Esta es una oración de muestra y vamos a eliminar las palabras vacías de esto»
Salida: [‘Esto’, ‘muestra’, ‘oración’, ‘va’, ‘eliminar’, ‘palabras vacías’]
Derivación:
Stemming es el proceso de obtener la raíz de una palabra. La raíz o raíz es la parte a la que se le añaden los afijos flexivos (-ed, -ize, -de, -s, etc.). La raíz de una palabra se crea eliminando el prefijo o el sufijo de una palabra. Por lo tanto, derivar una palabra puede no resultar en palabras reales.
Ejemplo:
books ---> book looked ---> look denied ---> deni flies ---> fli
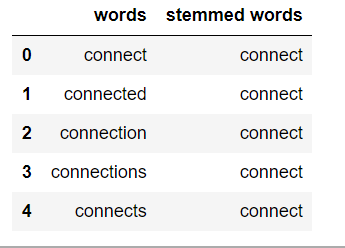
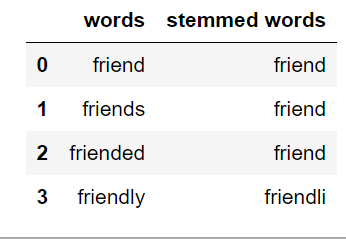
Si el texto no está en tokens, entonces debemos convertirlo en tokens. Después de convertir strings de texto en tokens, podemos convertir la palabra tokens en su forma raíz. Existen principalmente tres algoritmos para la derivación. Estos son el Porter Stemmer, el Snowball Stemmer y el Lancaster Stemmer. Porter Stemmer es el más común entre ellos.
Python3
from nltk.stem.porter import PorterStemmer from nltk.tokenize import word_tokenize stemmer = PorterStemmer() # stem words in the list of tokenized words def stem_words(text): word_tokens = word_tokenize(text) stems = [stemmer.stem(word) for word in word_tokens] return stems text = 'data science uses scientific methods algorithms and many types of processes' stem_words(text)
Ejemplo:
Entrada: ‘la ciencia de datos usa métodos científicos, algoritmos y muchos tipos de procesos’
Salida: [‘datos’, ‘ciencia’, ‘uso’, ‘científico’, ‘método’, ‘algoritmo’, ‘y’, ‘mani’, ‘tipo’, ‘de’, ‘proceso’]
Lematización:
Al igual que la derivación, la lematización también convierte una palabra a su forma raíz. La única diferencia es que la lematización asegura que la raíz de la palabra pertenece al idioma. Obtendremos palabras válidas si usamos la lematización. En NLTK, usamos WordNetLemmatizer para obtener los lemas de las palabras. También necesitamos proporcionar un contexto para la lematización. Entonces, agregamos la parte del discurso como parámetro.
Python3
from nltk.stem import WordNetLemmatizer from nltk.tokenize import word_tokenize lemmatizer = WordNetLemmatizer() # lemmatize string def lemmatize_word(text): word_tokens = word_tokenize(text) # provide context i.e. part-of-speech lemmas = [lemmatizer.lemmatize(word, pos ='v') for word in word_tokens] return lemmas text = 'data science uses scientific methods algorithms and many types of processes' lemmatize_word(text)
Ejemplo:
Entrada: ‘la ciencia de datos usa métodos científicos, algoritmos y muchos tipos de procesos’
Salida: [‘datos’, ‘ciencia’, ‘uso’, ‘científico’, ‘métodos’, ‘algoritmos’, ‘y’, ‘muchos’, ‘tipo’, ‘de’, ‘proceso’]
Publicación traducida automáticamente
Artículo escrito por jacobperalta y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA