La introducción a la agrupación en clústeres se analiza en este artículo y se recomienda comprenderla primero.
Los algoritmos de agrupamiento son de muchos tipos. La siguiente descripción general solo enumerará los ejemplos más destacados de algoritmos de agrupamiento, ya que posiblemente haya más de 100 algoritmos de agrupamiento publicados. No todos proporcionan modelos para sus grupos y, por lo tanto, no se pueden categorizar fácilmente.
Métodos basados en distribución:
Es un modelo de agrupamiento en el que ajustaremos los datos sobre la probabilidad de que puedan pertenecer a la misma distribución. La agrupación realizada puede ser normal o gaussiana . La distribución gaussiana es más prominente cuando tenemos un número fijo de distribuciones y todos los datos próximos se ajustan de manera que la distribución de datos pueda maximizarse. Este resultado en la agrupación que se muestra en la figura: –
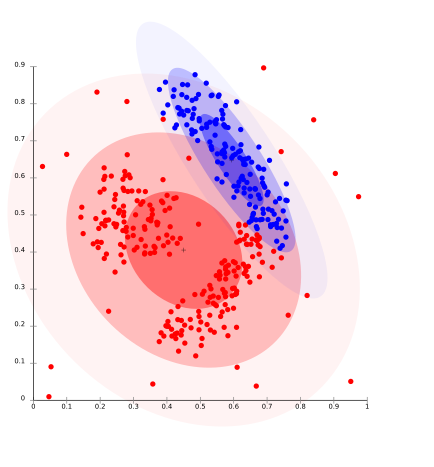
Este modelo funciona bien con datos sintéticos y conglomerados de diversos tamaños. Pero este modelo puede tener problemas si las restricciones no se utilizan para limitar la complejidad del modelo. Además, el agrupamiento basado en distribución produce grupos que asumen modelos matemáticos definidos de manera concisa subyacentes a los datos, una suposición bastante fuerte para algunas distribuciones de datos. Por ejemplo, el algoritmo
de maximización de expectativas que utiliza distribuciones normales multivariadas es uno de los ejemplos populares de este algoritmo.
Métodos basados en el centroide:
este es básicamente uno de los algoritmos iterativos de agrupación en clústeres en los que los clústeres se forman por la cercanía de los puntos de datos al centroide de los clústeres. Aquí, el centro del grupo, es decir, el centroide , se forma de manera que la distancia de los puntos de datos sea mínima con el centro. Este problema es básicamente uno de los problemas NP-Hard y, por lo tanto, las soluciones se aproximan comúnmente en varios ensayos.
Para Ex- K – el algoritmo de medios es uno de los ejemplos populares de este algoritmo.
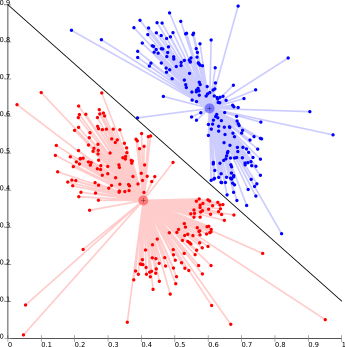
El mayor problema con este algoritmo es que necesitamos especificar K por adelantado. También tiene problemas para agrupar distribuciones basadas en la densidad.
Métodos basados en la conectividad:
la idea central del modelo basado en la conectividad es similar al modelo basado en el Centroide, que básicamente define grupos en función de la cercanía de los puntos de datos. Aquí trabajamos con la noción de que los puntos de datos que están más cerca tienen un comportamiento similar en comparación con los puntos de datos que están más lejos.
No es una partición única del conjunto de datos, sino que proporciona una amplia jerarquía de grupos que se fusionan entre sí a ciertas distancias. Aquí la elección de la función de distancia es subjetiva. Estos modelos son muy fáciles de interpretar pero carecen de escalabilidad.
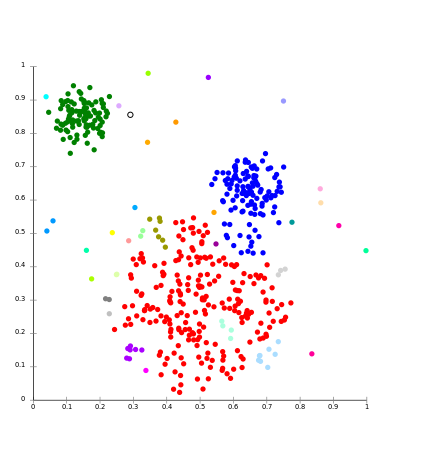
Para Ex- algoritmo jerárquico y sus variantes.
Modelos de densidad:
en este modelo de agrupamiento, se buscará en el espacio de datos áreas de densidad variada de puntos de datos en el espacio de datos. Aísla varias regiones de densidad en función de las diferentes densidades presentes en el espacio de datos.
Para Ex- DBSCAN y OPTICS .
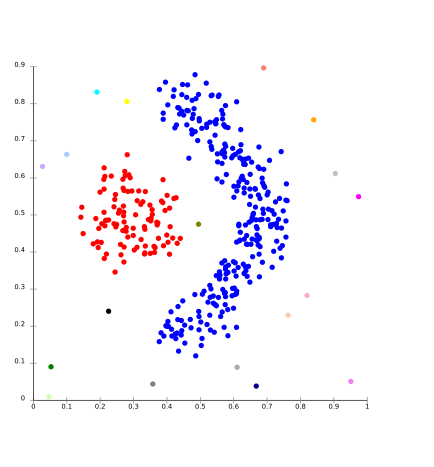
Agrupamiento subespacial:
La agrupación de subespacios es un problema de aprendizaje no supervisado que tiene como objetivo agrupar puntos de datos en múltiples grupos para que los puntos de datos en un solo grupo se encuentren aproximadamente en un subespacio lineal de baja dimensión. El agrupamiento subespacial es una extensión de la selección de características, al igual que con la selección de características, el agrupamiento subespacial requiere un método de búsqueda y criterios de evaluación, pero además el agrupamiento subespacial limita el alcance de los criterios de evaluación. El algoritmo de agrupación de subespacios localiza la búsqueda de dimensiones relevantes y les permite encontrar el grupo que existe en múltiples subespacios superpuestos. El agrupamiento subespacial se propuso originalmente para resolver problemas de visión por computadora muy específicos que tienen una unión de estructura subespacial en los datos, pero gana cada vez más atención en la comunidad de estadísticas y aprendizaje automático. La gente usa esta herramienta en redes sociales, recomendaciones de películas y conjuntos de datos biológicos. La agrupación subespacial plantea la preocupación por la privacidad de los datos, ya que muchas de estas aplicaciones implican el manejo de información confidencial. Se supone que los puntos de datos son incoherentes, ya que solo protegen la privacidad diferencial de cualquier característica de un usuario en lugar del perfil completo del usuario de la base de datos.
Hay dos ramas del agrupamiento subespacial en función de su estrategia de búsqueda.
- Los algoritmos de arriba hacia abajo encuentran una agrupación inicial en el conjunto completo de dimensiones y evalúan el subespacio de cada agrupación.
- El enfoque de abajo hacia arriba encuentra una región densa en un espacio de baja dimensión y luego se combina para formar grupos.
Referencias:
analyticsvidhya
knowm
Publicación traducida automáticamente
Artículo escrito por Surya Priy y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA