kNN ponderado es una versión modificada de k vecinos más cercanos . Uno de los muchos problemas que afectan el rendimiento del algoritmo kNN es la elección del hiperparámetro k. Si k es demasiado pequeño, el algoritmo sería más sensible a los valores atípicos. Si k es demasiado grande, entonces la vecindad puede incluir demasiados puntos de otras clases.
Otro problema es el enfoque para combinar las etiquetas de clase. El método más simple es tomar el voto de la mayoría, pero esto puede ser un problema si los vecinos más cercanos varían mucho en su distancia y los vecinos más cercanos indican de manera más confiable la clase del objeto.
Intuición:
considere el siguiente conjunto de entrenamiento . 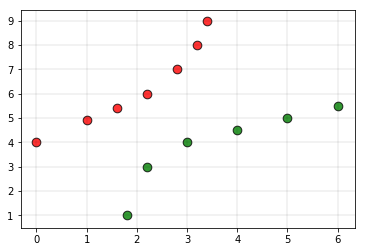
Las etiquetas rojas indican los puntos de clase 0 y las etiquetas verdes indican los puntos de clase 1.
Considere el punto blanco como el punto de consulta (el punto cuya etiqueta de clase debe predecirse)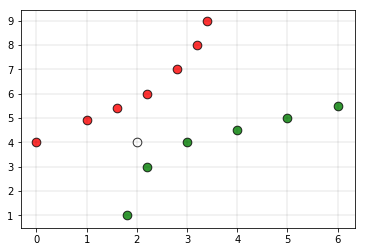
Si le damos el conjunto de datos anterior a un clasificador basado en kNN, entonces el clasificador declararía que el punto de consulta pertenece a la clase 0. Pero en la gráfica, está claro que el punto está más cerca de los puntos de la clase 1 en comparación con la clase 0 puntos Para superar esta desventaja, se utiliza kNN ponderado. En kNN ponderado, los k puntos más cercanos reciben un peso mediante una función llamada función kernel. La intuición detrás de kNN ponderado es dar más peso a los puntos que están cerca y menos peso a los puntos que están más lejos. Cualquier función se puede utilizar como función kernel para el clasificador knn ponderado cuyo valor disminuye a medida que aumenta la distancia. La función simple que se utiliza es la función de distancia inversa.
Algoritmo:
- Sea L = { ( x yo , y yo ) , yo = 1, . . . ,n } sea un conjunto de entrenamiento de observaciones x i con una clase y i dada y sea x una nueva observación (punto de consulta), cuya etiqueta de clase y debe predecirse.
- Calcule d(x i , x) para i = 1, . . . ,n , la distancia entre el punto de consulta y todos los demás puntos del conjunto de entrenamiento.
- Seleccione D’ ⊆ D, el conjunto de k puntos de datos de entrenamiento más cercanos a los puntos de consulta
- Prediga la clase del punto de consulta mediante la votación ponderada por distancia. La v representa las etiquetas de clase. Utilice la siguiente fórmula
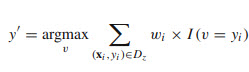
Implementación:
Considere 0 como la etiqueta para la clase 0 y 1 como la etiqueta para la clase 1. A continuación se muestra la implementación del algoritmo de kNN ponderado.
C/C++
// C++ program to implement the
// weighted K nearest neighbour algorithm.
#include <bits/stdc++.h>
using namespace std;
struct Point
{
int val; // Class of point
double x, y; // Co-ordinate of point
double distance; // Distance from test point
};
// Used to sort an array of points by increasing
// order of weighted distance
bool comparison(Point a, Point b)
{
return (a.distance < b.distance);
}
// This function finds classification of point p using
// weighted k nearest neighbour algorithm. It assumes only
// two groups and returns 0 if p belongs to class 0, else
// 1 (belongs to class 1).
int weightedkNN(Point arr[], int n, int k, Point p)
{
// Fill weighted distances of all points from p
for (int i = 0; i < n; i++)
arr[i].distance =
(sqrt((arr[i].x - p.x) * (arr[i].x - p.x) +
(arr[i].y - p.y) * (arr[i].y - p.y)));
// Sort the Points by weighted distance from p
sort(arr, arr+n, comparison);
// Now consider the first k elements and only
// two groups
double freq1 = 0; // weighted sum of group 0
double freq2 = 0; // weighted sum of group 1
for (int i = 0; i < k; i++)
{
if (arr[i].val == 0)
freq1 += double(1/arr[i].distance);
else if (arr[i].val == 1)
freq2 += double(1/arr[i].distance);
}
return (freq1 > freq2 ? 0 : 1);
}
// Driver code
int main()
{
int n = 13; // Number of data points
Point arr[n];
arr[0].x = 0;
arr[0].y = 4;
arr[0].val = 0;
arr[1].x = 1;
arr[1].y = 4.9;
arr[1].val = 0;
arr[2].x = 1.6;
arr[2].y = 5.4;
arr[2].val = 0;
arr[3].x = 2.2;
arr[3].y = 6;
arr[3].val = 0;
arr[4].x = 2.8;
arr[4].y = 7;
arr[4].val = 0;
arr[5].x = 3.2;
arr[5].y = 8;
arr[5].val = 0;
arr[6].x = 3.4;
arr[6].y = 9;
arr[6].val = 0;
arr[7].x = 1.8;
arr[7].y = 1;
arr[7].val = 1;
arr[8].x = 2.2;
arr[8].y = 3;
arr[8].val = 1;
arr[9].x = 3;
arr[9].y = 4;
arr[9].val = 1;
arr[10].x = 4;
arr[10].y = 4.5;
arr[10].val = 1;
arr[11].x = 5;
arr[11].y = 5;
arr[11].val = 1;
arr[12].x = 6;
arr[12].y = 5.5;
arr[12].val = 1;
/*Testing Point*/
Point p;
p.x = 2;
p.y = 4;
// Parameter to decide the class of the query point
int k = 5;
printf ("The value classified to query point"
" is: %d.\n", weightedkNN(arr, n, k, p));
return 0;
}
Python3
# Python3 program to implement the
# weighted K nearest neighbour algorithm.
import math
def weightedkNN(points,p,k=3):
'''
This function finds classification of p using
weighted k nearest neighbour algorithm. It assumes only two
two classes and returns 0 if p belongs to class 0, else
1 (belongs to class 1).
Parameters -
points : Dictionary of training points having two keys - 0 and 1
Each key have a list of training data points belong to that
p : A tuple ,test data point of form (x,y)
k : number of nearest neighbour to consider, default is 3
'''
distance=[]
for group in points:
for feature in points[group]:
#calculate the euclidean distance of p from training points
euclidean_distance = math.sqrt((feature[0]-p[0])**2 +(feature[1]-p[1])**2)
# Add a tuple of form (distance,group) in the distance list
distance.append((euclidean_distance,group))
# sort the distance list in ascending order
# and select first k distances
distance = sorted(distance)[:k]
freq1 = 0 # weighted sum of group 0
freq2 = 0 # weighted sum of group 1
for d in distance:
if d[1] == 0:
freq1 += (1 / d[0])
elif d[1] == 1:
freq2 += (1 /d[0])
return 0 if freq1>freq2 else 1
# Driver function
def main():
# Dictionary of training points having two keys - 0 and 1
# key 0 have points belong to class 0
# key 1 have points belong to class 1
points = {0:[(0, 4),(1, 4.9),(1.6, 5.4),(2.2, 6),(2.8, 7),(3.2, 8),(3.4, 9)],
1:[(1.8, 1),(2.2, 3),(3, 4),(4, 4.5),(5, 5),(6, 5.5)]}
# query point p(x,y)
p = (2, 4)
# Number of neighbours
k = 5
print("The value classified to query point is: {}".format(weightedkNN(points,p,k)))
if __name__ == '__main__':
main()
The value classified to query point is: 1
Publicación traducida automáticamente
Artículo escrito por kanakalathav99 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA