CUDA (o Computer Unified Device Architecture) es una plataforma de computación paralela y un modelo de programación patentados de NVIDIA. Con CUDA SDK, los desarrolladores pueden utilizar sus GPU NVIDIA (Unidades de procesamiento de gráficos), lo que les permite incorporar la potencia del procesamiento paralelo basado en GPU en lugar del procesamiento secuencial habitual basado en CPU en su flujo de trabajo de programación habitual.
Con el aprendizaje profundo en aumento en los últimos años, se ha visto que varias operaciones involucradas en el entrenamiento de modelos, como la multiplicación de arrays, la inversión, etc., se pueden paralelizar en gran medida para un mejor rendimiento del aprendizaje y ciclos de entrenamiento más rápidos. Por lo tanto, muchas bibliotecas de aprendizaje profundo como Pytorch permiten a sus usuarios aprovechar sus GPU mediante un conjunto de interfaces y funciones de utilidad. Este artículo cubrirá la configuración de un entorno CUDA en cualquier sistema que contenga GPU habilitadas para CUDA y una breve introducción a las diversas operaciones CUDA disponibles en la biblioteca Pytorch usando Python.
Instalación
Primero, debe asegurarse de que su GPU esté habilitada para CUDA o no al verificar la GPU de su sistema a través de la lista oficial de compatibilidad de Nvidia CUDA. Pytorch hace que el proceso de instalación de CUDA sea muy simple al proporcionar una interfaz agradable y fácil de usar que le permite elegir su sistema operativo y otros requisitos, como se muestra en la figura a continuación. De acuerdo con nuestra máquina de cómputo, instalaremos de acuerdo con las especificaciones que se dan en la figura a continuación.
Consulte el enlace oficial de Pytorch y elija las especificaciones de acuerdo con las especificaciones de su computadora. También sugerimos un reinicio completo del sistema después de la instalación para garantizar el correcto funcionamiento del conjunto de herramientas.
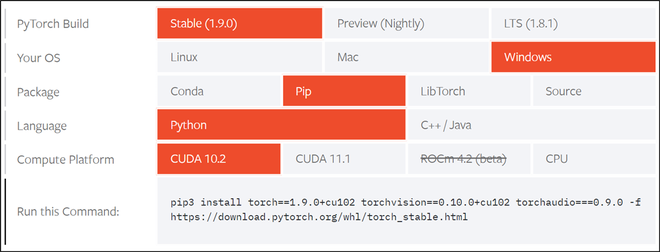
Captura de pantalla de la página de instalación de Pytorch
pip3 install torch==1.9.0+cu102 torchvision==0.10.0+cu102 torchaudio===0.9.0 -f https://download.pytorch.org/whl/torch_stable.html
Primeros pasos con CUDA en Pytorch
Una vez instalado, podemos usar la interfaz torch.cuda para interactuar con CUDA usando Pytorch. Usaremos las siguientes funciones:
Sintaxis:
- torch.version.cuda(): Devuelve la versión CUDA de los paquetes actualmente instalados
- torch.cuda.is_disponible(): Devuelve True si CUDA es compatible con su sistema, de lo contrario, False
- torch.cuda.current_device(): Devuelve el ID del dispositivo actual
- torch.cuda.get_device_name(device_ID): Devuelve el nombre del dispositivo CUDA con ID = ‘device_ID’
Código:
Python3
import torch
print(f"Is CUDA supported by this system?
{torch.cuda.is_available()}")
print(f"CUDA version: {torch.version.cuda}")
# Storing ID of current CUDA device
cuda_id = torch.cuda.current_device()
print(f"ID of current CUDA device:
{torch.cuda.current_device()}")
print(f"Name of current CUDA device:
{torch.cuda.get_device_name(cuda_id)}")
Producción:

versión CUDA
Manejo de tensores con CUDA
Para interactuar con los tensores de Pytorch a través de CUDA, podemos usar las siguientes funciones de utilidad:
Sintaxis:
- Tensor.device: Devuelve el nombre del dispositivo de ‘Tensor’
- Tensor.to(device_name): Devuelve una nueva instancia de ‘Tensor’ en el dispositivo especificado por ‘device_name’: ‘cpu’ para CPU y ‘cuda’ para GPU habilitada para CUDA
- Tensor.cpu(): transfiere ‘Tensor’ a la CPU desde su dispositivo actual
Para demostrar las funciones anteriores, crearemos un tensor de prueba y haremos las siguientes operaciones:
Comprobando el dispositivo actual del tensor y aplicando una operación de tensor (cuadrado), transfiriendo el tensor a GPU y aplicando la misma operación de tensor (cuadrado) y comparando los resultados de los 2 dispositivos.
Código:
Python3
import torch
# Creating a test tensor
x = torch.randint(1, 100, (100, 100))
# Checking the device name:
# Should return 'cpu' by default
print(x.device)
# Applying tensor operation
res_cpu = x ** 2
# Transferring tensor to GPU
x = x.to(torch.device('cuda'))
# Checking the device name:
# Should return 'cuda:0'
print(x.device)
# Applying same tensor operation
res_gpu = x ** 2
# Checking the equality
# of the two results
assert torch.equal(res_cpu, res_gpu.cpu())
Producción:
cpu cuda : 0
Manejo de modelos de Machine Learning con CUDA
Una buena práctica de Pytorch es producir código independiente del dispositivo porque algunos sistemas pueden no tener acceso a una GPU y deben depender solo de la CPU o viceversa. Una vez hecho esto, se puede usar la siguiente función para transferir cualquier modelo de aprendizaje automático al dispositivo seleccionado
Sintaxis: Model.to(device_name):
Devoluciones: Nueva instancia de Machine Learning ‘Modelo’ en el dispositivo especificado por ‘device_name’: ‘cpu’ para CPU y ‘cuda’ para GPU habilitada para CUDA
En este ejemplo, estamos importando el modelo Resnet-18 previamente entrenado desde la utilidad torchvision.models , el lector puede usar los mismos pasos para transferir modelos a su dispositivo seleccionado.
Código:
Python3
import torch import torchvision.models as models # Making the code device-agnostic device = 'cuda' if torch.cuda.is_available() else 'cpu' # Instantiating a pre-trained model model = models.resnet18(pretrained=True) # Transferring the model to a CUDA enabled GPU model = model.to(device) # Now the reader can continue the rest of the workflow # including training, cross validation, etc!
Producción:

Aprendizaje automático con CUDA
Publicación traducida automáticamente
Artículo escrito por adityasaini70 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA