En este artículo, discutiremos cómo realizar un análisis exploratorio de datos en el conjunto de datos de Iris. Antes de continuar con este artículo, hemos utilizado dos términos, es decir, EDA e Iris Dataset. Veamos un resumen sobre estos conjuntos de datos.
¿Qué es el análisis exploratorio de datos?
El análisis exploratorio de datos (EDA) es una técnica para analizar datos utilizando algunas técnicas visuales. Con esta técnica podemos obtener información detallada sobre el resumen estadístico de los datos. También podremos tratar con los valores duplicados, valores atípicos y también ver algunas tendencias o patrones presentes en el conjunto de datos.
Ahora veamos un resumen sobre el conjunto de datos de Iris.
Conjunto de datos de iris
Si tiene experiencia en ciencia de datos, todos deben estar familiarizados con el conjunto de datos de Iris. Si no es así, no se preocupe, discutiremos esto aquí.
Iris Dataset es considerado como el Hola Mundo para la ciencia de datos. Contiene cinco columnas, a saber: Longitud del pétalo, Ancho del pétalo, Longitud del sépalo, Ancho del sépalo y Tipo de especie. Iris es una planta con flores, los investigadores midieron varias características de las diferentes flores de iris y las registraron digitalmente.
Nota: Este conjunto de datos se puede descargar desde aquí .
Puede descargar el archivo Iris.csv desde el enlace anterior. Ahora usaremos la biblioteca de Pandas para cargar este archivo CSV y lo convertiremos en el marco de datos . El método read_csv() se utiliza para leer archivos CSV.
Ejemplo:
Python3
import pandas as pd
# Reading the CSV file
df = pd.read_csv("Iris.csv")
# Printing top 5 rows
df.head()
Producción:
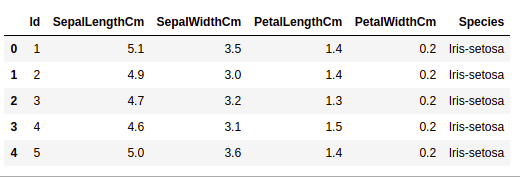
Obtener información sobre el conjunto de datos
Usaremos el parámetro de forma para obtener la forma del conjunto de datos.
Ejemplo:
Python3
df.shape
Producción:
(150, 6)
Podemos ver que el marco de datos contiene 6 columnas y 150 filas.
Ahora, veamos también las columnas y sus tipos de datos. Para ello, utilizaremos el método info() .
Ejemplo:
Python3
df.info()
Producción:
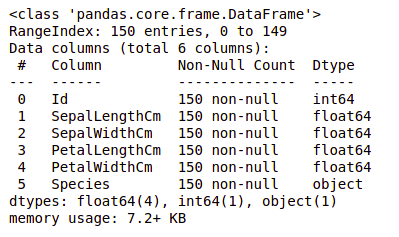
Podemos ver que solo una columna tiene datos categóricos y todas las demás columnas son de tipo numérico con entradas no nulas.
Obtengamos un resumen estadístico rápido del conjunto de datos usando el método describe() . La función describe() aplica cálculos estadísticos básicos en el conjunto de datos, como valores extremos, conteo de puntos de datos, desviación estándar, etc. Cualquier valor faltante o valor de NaN se omite automáticamente. describe() da una buena imagen de la distribución de datos.
Ejemplo:
Python3
df.describe()
Producción:
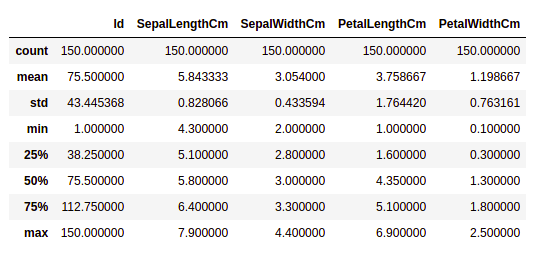
Podemos ver el recuento de cada columna junto con su valor medio, desviación estándar, valores mínimo y máximo.
Comprobación de valores faltantes
Verificaremos si nuestros datos contienen valores faltantes o no. Los valores faltantes pueden ocurrir cuando no se proporciona información para uno o más elementos o para una unidad completa. Usaremos el método isnull() .
Ejemplo:
Python3
df.isnull().sum()
Producción:
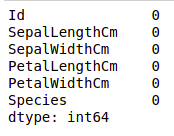
Podemos ver que ninguna columna tiene ningún valor faltante.
Nota: Para obtener más información, consulte Trabajar con datos faltantes en Pandas .
Comprobación de duplicados
Veamos si nuestro conjunto de datos contiene duplicados o no. El método pandas drop_duplicates() ayuda a eliminar duplicados del marco de datos.
Ejemplo:
Python3
data = df.drop_duplicates(subset ="Species",) data
Producción:
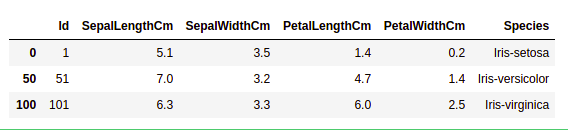
Podemos ver que solo hay tres especies únicas. Veamos si el conjunto de datos está equilibrado o no, es decir, todas las especies contienen la misma cantidad de filas o no. Usaremos la función Series.value_counts() . Esta función devuelve una serie que contiene recuentos de valores únicos.
Ejemplo:
Python3
df.value_counts("Species")
Producción:
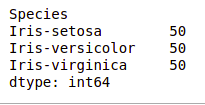
Podemos ver que todas las especies contienen la misma cantidad de filas, por lo que no debemos eliminar ninguna entrada.
Visualización de datos
Visualización de la columna de destino
Nuestra columna objetivo será la columna Especie porque al final necesitaremos el resultado solo según la especie. Veamos un diagrama de conteo para especies.
Nota: Usaremos Matplotlib y la biblioteca Seaborn para la visualización de datos. Si desea conocer estos módulos, consulte los artículos:
Ejemplo:
Python3
# importing packages import seaborn as sns import matplotlib.pyplot as plt sns.countplot(x='Species', data=df, ) plt.show()
Producción:
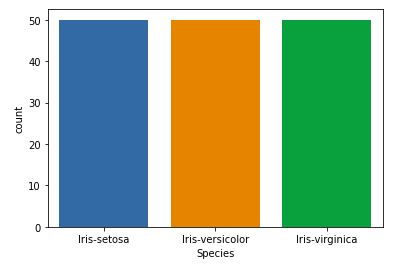
Relación entre variables
Veremos la relación entre el largo y el ancho del sépalo y también entre el largo y el ancho del pétalo.
Ejemplo 1: Comparación de la longitud y el ancho del sépalo
Python3
# importing packages import seaborn as sns import matplotlib.pyplot as plt sns.scatterplot(x='SepalLengthCm', y='SepalWidthCm', hue='Species', data=df, ) # Placing Legend outside the Figure plt.legend(bbox_to_anchor=(1, 1), loc=2) plt.show()
Producción:
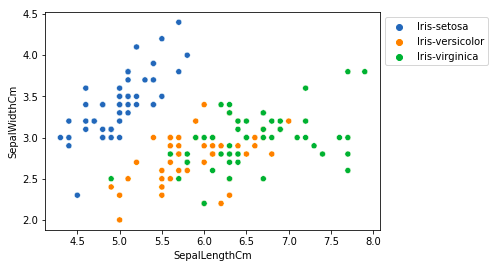
De la gráfica anterior, podemos inferir que:
- La especie Setosa tiene longitudes de sépalos más pequeños pero anchos de sépalos más grandes.
- La especie Versicolor se encuentra en el medio de las otras dos especies en términos de longitud y anchura del sépalo.
- La especie Virginica tiene longitudes de sépalos más grandes pero anchos de sépalos más pequeños.
Ejemplo 2: Comparación de la longitud y el ancho de los pétalos
Python3
# importing packages import seaborn as sns import matplotlib.pyplot as plt sns.scatterplot(x='PetalLengthCm', y='PetalWidthCm', hue='Species', data=df, ) # Placing Legend outside the Figure plt.legend(bbox_to_anchor=(1, 1), loc=2) plt.show()
Producción:
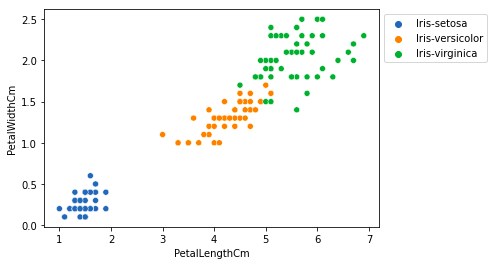
De la gráfica anterior, podemos inferir que:
- La especie Setosa tiene longitudes y anchos de pétalos más pequeños.
- La especie Versicolor se encuentra en el medio de las otras dos especies en términos de largo y ancho de los pétalos.
- La especie Virginica tiene la mayor longitud y anchura de pétalos.
Grafiquemos todas las relaciones de la columna usando un diagrama de pares. Se puede utilizar para el análisis multivariante.
Ejemplo:
Python3
# importing packages import seaborn as sns import matplotlib.pyplot as plt sns.pairplot(df.drop(['Id'], axis = 1), hue='Species', height=2)
Producción:
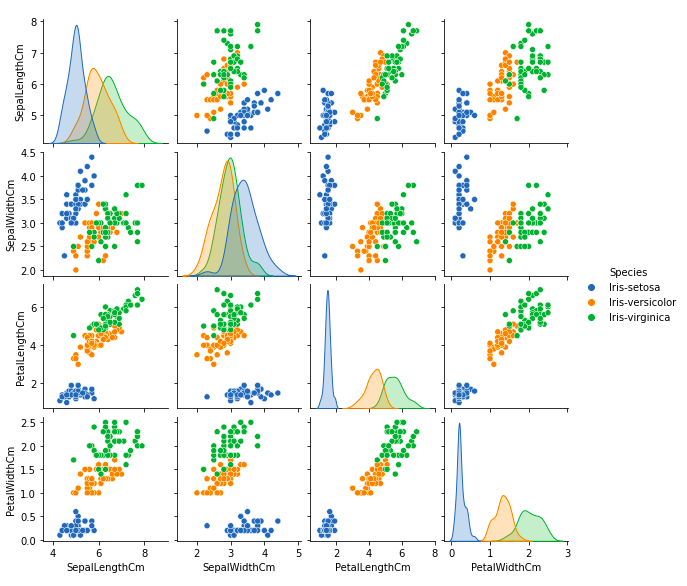
Podemos ver muchos tipos de relaciones en este diagrama, como que la especie Seotsa tiene los pétalos más pequeños de ancho y largo. También tiene la longitud de sépalo más pequeña pero el ancho de sépalo más grande. Dicha información se puede recopilar sobre cualquier otra especie.
Histogramas
Los histogramas permiten ver la distribución de datos para varias columnas. Se puede utilizar para análisis uni y bivariados.
Ejemplo:
Python3
# importing packages
import seaborn as sns
import matplotlib.pyplot as plt
fig, axes = plt.subplots(2, 2, figsize=(10,10))
axes[0,0].set_title("Sepal Length")
axes[0,0].hist(df['SepalLengthCm'], bins=7)
axes[0,1].set_title("Sepal Width")
axes[0,1].hist(df['SepalWidthCm'], bins=5);
axes[1,0].set_title("Petal Length")
axes[1,0].hist(df['PetalLengthCm'], bins=6);
axes[1,1].set_title("Petal Width")
axes[1,1].hist(df['PetalWidthCm'], bins=6);
Producción:
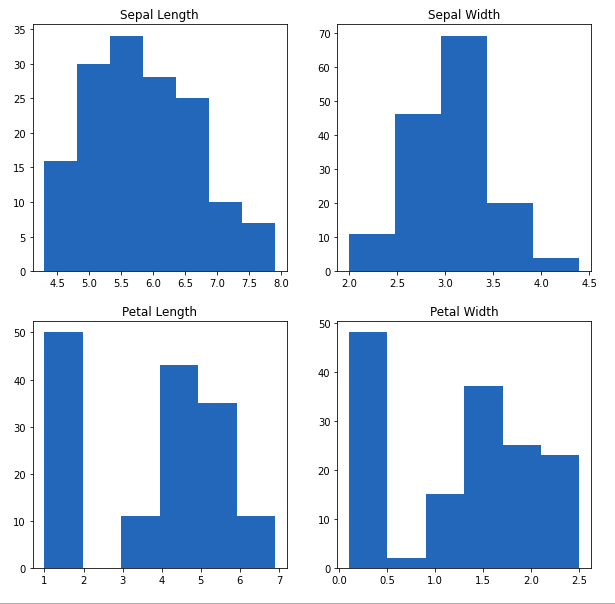
De la gráfica anterior, podemos ver que:
- La frecuencia más alta de la longitud del sépalo está entre 30 y 35 que está entre 5,5 y 6
- La frecuencia más alta del ancho del sépalo es de alrededor de 70, que está entre 3,0 y 3,5.
- La frecuencia más alta de la longitud del pétalo es alrededor de 50, que está entre 1 y 2
- La frecuencia más alta del ancho del pétalo está entre 40 y 50, que está entre 0,0 y 0,5
Histogramas con Distplot Plot
Distplot se usa básicamente para el conjunto univariante de observaciones y lo visualiza a través de un histograma, es decir, solo una observación y, por lo tanto, elegimos una columna particular del conjunto de datos.
Ejemplo:
Python3
# importing packages import seaborn as sns import matplotlib.pyplot as plt plot = sns.FacetGrid(df, hue="Species") plot.map(sns.distplot, "SepalLengthCm").add_legend() plot = sns.FacetGrid(df, hue="Species") plot.map(sns.distplot, "SepalWidthCm").add_legend() plot = sns.FacetGrid(df, hue="Species") plot.map(sns.distplot, "PetalLengthCm").add_legend() plot = sns.FacetGrid(df, hue="Species") plot.map(sns.distplot, "PetalWidthCm").add_legend() plt.show()
Producción:
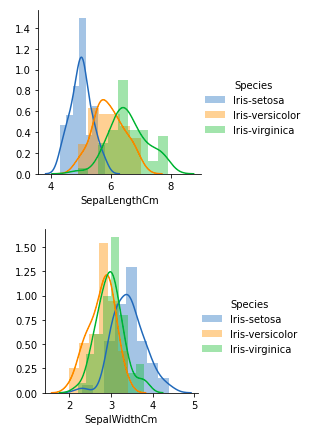
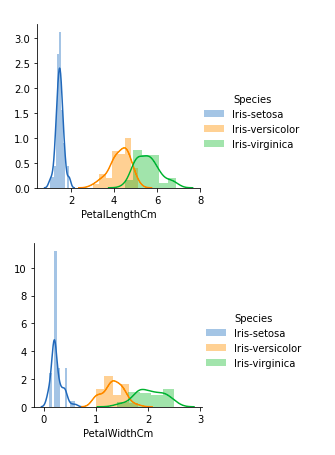
De las gráficas anteriores, podemos ver que:
- En el caso de Sepal Length, hay una gran cantidad de superposiciones.
- En el caso de Sepal Width también, hay una gran cantidad de superposición.
- En el caso de Longitud de pétalo, hay muy poca superposición.
- En el caso de Petal Width también, hay muy poca superposición.
Entonces podemos usar la longitud del pétalo y el ancho del pétalo como característica de clasificación.
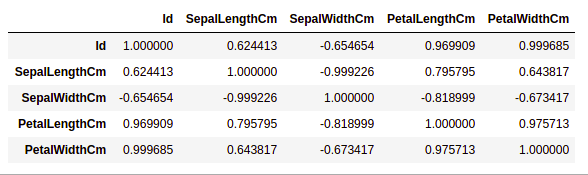
Correlación de manejo
Pandas dataframe.corr() se usa para encontrar la correlación por pares de todas las columnas en el marco de datos. Cualquier valor NA se excluye automáticamente. Para cualquier columna de tipo de datos no numérico en el marco de datos, se ignora.
Ejemplo:
Python3
data.corr(method='pearson')
Producción:
mapas de calor
El mapa de calor es una técnica de visualización de datos que se utiliza para analizar el conjunto de datos como colores en dos dimensiones. Básicamente, muestra una correlación entre todas las variables numéricas en el conjunto de datos. En términos más simples, podemos trazar la correlación encontrada anteriormente usando los mapas de calor.
Ejemplo:
Python3
# importing packages import seaborn as sns import matplotlib.pyplot as plt sns.heatmap(df.corr(method='pearson').drop( ['Id'], axis=1).drop(['Id'], axis=0), annot = True); plt.show()
Producción:
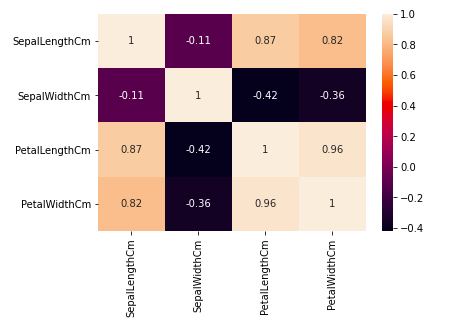
En el gráfico anterior, podemos ver que:
- El ancho del pétalo y la longitud del pétalo tienen altas correlaciones.
- La longitud del pétalo y el ancho del sépalo tienen buenas correlaciones.
- El ancho del pétalo y la longitud del sépalo tienen buenas correlaciones.
Diagramas de caja
Podemos usar diagramas de caja para ver cómo se distribuye el valor categórico con otros valores numéricos.
Ejemplo:
Python3
# importing packages
import seaborn as sns
import matplotlib.pyplot as plt
def graph(y):
sns.boxplot(x="Species", y=y, data=df)
plt.figure(figsize=(10,10))
# Adding the subplot at the specified
# grid position
plt.subplot(221)
graph('SepalLengthCm')
plt.subplot(222)
graph('SepalWidthCm')
plt.subplot(223)
graph('PetalLengthCm')
plt.subplot(224)
graph('PetalWidthCm')
plt.show()
Producción:
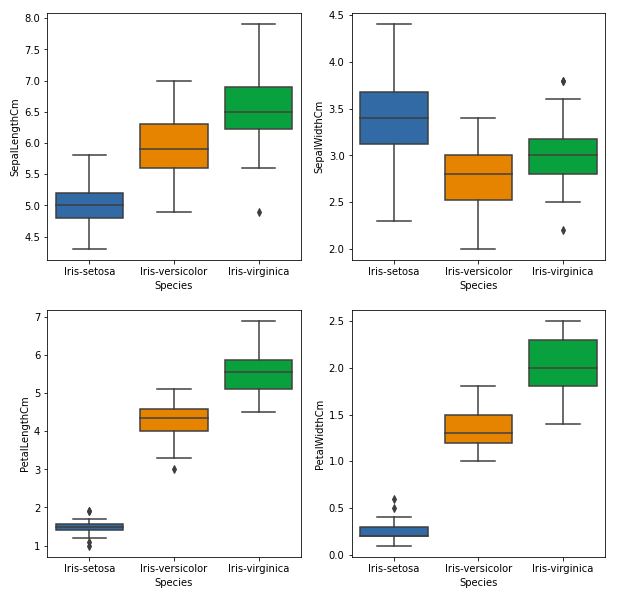
En el gráfico anterior, podemos ver que:
- La especie Setosa tiene las características más pequeñas y menos distribuidas con algunos valores atípicos.
- La especie Versicolor tiene las características medias.
- Especie Virginica tiene las características más altas
Manejo de valores atípicos
Un valor atípico es un elemento/objeto de datos que se desvía significativamente del resto de los objetos (llamados normales). Pueden ser causados por errores de medición o de ejecución. El análisis para la detección de valores atípicos se denomina minería de valores atípicos. Hay muchas formas de detectar los valores atípicos, y el proceso de eliminación es el marco de datos igual que eliminar un elemento de datos del marco de datos del panda.
Consideremos el conjunto de datos del iris y tracemos el diagrama de caja para la columna SepalWidthCm.
Ejemplo:
Python3
# importing packages
import seaborn as sns
import matplotlib.pyplot as plt
# Load the dataset
df = pd.read_csv('Iris.csv')
sns.boxplot(x='SepalWidthCm', data=df)
Producción:
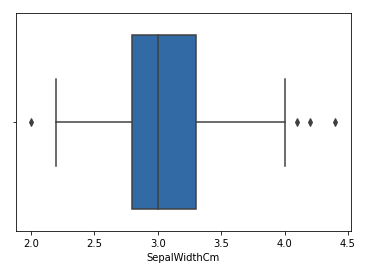
En el gráfico anterior, los valores por encima de 4 y por debajo de 2 actúan como valores atípicos.
Eliminación de valores atípicos
Para eliminar el valor atípico, se debe seguir el mismo proceso de eliminar una entrada del conjunto de datos usando su posición exacta en el conjunto de datos porque en todos los métodos anteriores para detectar los valores atípicos, el resultado final es la lista de todos los elementos de datos que satisfacen la definición de valor atípico. según el método utilizado.
Ejemplo: Detectaremos los valores atípicos usando IQR y luego los eliminaremos. También dibujaremos el diagrama de caja para ver si se eliminan los valores atípicos o no.
Python3
# Importing
import sklearn
from sklearn.datasets import load_boston
import pandas as pd
import seaborn as sns
# Load the dataset
df = pd.read_csv('Iris.csv')
# IQR
Q1 = np.percentile(df['SepalWidthCm'], 25,
interpolation = 'midpoint')
Q3 = np.percentile(df['SepalWidthCm'], 75,
interpolation = 'midpoint')
IQR = Q3 - Q1
print("Old Shape: ", df.shape)
# Upper bound
upper = np.where(df['SepalWidthCm'] >= (Q3+1.5*IQR))
# Lower bound
lower = np.where(df['SepalWidthCm'] <= (Q1-1.5*IQR))
# Removing the Outliers
df.drop(upper[0], inplace = True)
df.drop(lower[0], inplace = True)
print("New Shape: ", df.shape)
sns.boxplot(x='SepalWidthCm', data=df)
Producción:
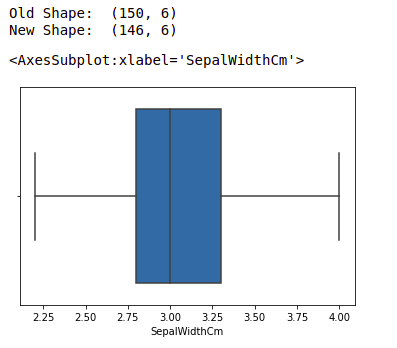
Nota: para obtener más información, consulte Detectar y eliminar los valores atípicos mediante Python
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA