Este artículo es para contarle la interpretación completa de la tabla de resumen de regresión. Hay muchos programas estadísticos que se usan para el análisis de regresión como Matlab, Minitab, spss, R, etc. pero este artículo usa python. La interpretación es la misma para otras herramientas también. Este artículo necesita los conceptos básicos de estadística, incluido el conocimiento básico de regresión, grados de libertad, desviación estándar, suma residual de cuadrados (RSS), ESS, estadísticas t, etc.
En la regresión hay dos tipos de variables, es decir, la variable dependiente (también llamada variable explicada) y la variable independiente (variable explicativa).
La línea de regresión utilizada aquí es,

A continuación se presenta la tabla resumen de la regresión.
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.669
Model: OLS Adj. R-squared: 0.667
Method: Least Squares F-statistic: 299.2
Date: Mon, 01 Mar 2021 Prob (F-statistic): 2.33e-37
Time: 16:19:34 Log-Likelihood: -88.686
No. Observations: 150 AIC: 181.4
Df Residuals: 148 BIC: 187.4
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const -3.2002 0.257 -12.458 0.000 -3.708 -2.693
x1 0.7529 0.044 17.296 0.000 0.667 0.839
==============================================================================
Omnibus: 3.538 Durbin-Watson: 1.279
Prob(Omnibus): 0.171 Jarque-Bera (JB): 3.589
Skew: 0.357 Prob(JB): 0.166
Kurtosis: 2.744 Cond. No. 43.4
==============================================================================
Variable dependiente: Variable dependiente es aquella que va a depender de otras variables. En este análisis de regresión, Y es nuestra variable dependiente porque queremos analizar el efecto de X en Y.
Modelo: El método de los Mínimos Cuadrados Ordinarios (OLS) es el modelo más utilizado debido a su eficiencia. Este modelo da la mejor aproximación de la verdadera línea de regresión de la población. El principio de MCO es minimizar el cuadrado de los errores ( ∑e i 2 ).
Número de observaciones: El número de observaciones es el tamaño de nuestra muestra, es decir, N = 150.
Grado de libertad (gl) de los residuos:
El grado de libertad es el número de observaciones independientes a partir de las cuales se calcula la suma de los cuadrados.
Residuales Df = 150 – (1+1) = 148
El grado de libertad (Df) se calcula como,
Grados de libertad, D . f = norte – k
Donde, N = tamaño de la muestra (nº de observaciones) y K = número de variables + 1
Df del modelo:
Df del modelo = K – 1 = 2 – 1 = 1 ,
Donde, K = número de variables + 1
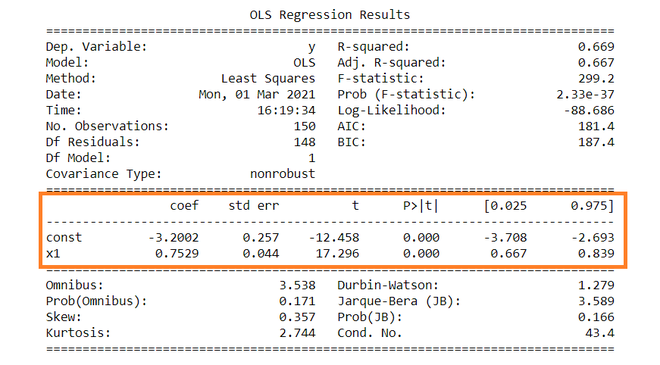
Término constante: Los términos constantes son la intersección de la línea de regresión. Desde la línea de regresión (eq…1) el intercepto es -3.002. En la regresión, omitimos algunas variables independientes que no tienen mucho impacto en la variable dependiente, el intercepto indica el valor promedio de estas variables omitidas y el ruido presente en el modelo.
Término de coeficiente: El término de coeficiente indica el cambio en Y para una unidad de cambio en X , es decir, si X aumenta en 1 unidad, entonces Y aumenta en 0,7529. Si está familiarizado con los derivados, puede relacionarlos como la tasa de cambio de Y con respecto a X.
Error estándar de los parámetros: El error estándar también se denomina desviación estándar. El error estándar muestra la variabilidad de muestreo de estos parámetros. El error estándar se calcula como –
Error estándar del término de intersección (b1):

Error estándar del término del coeficiente (b2):

Aquí, σ 2 es el error estándar de regresión (SER). Y σ 2 es igual a RSS (Residual Sum Of Square, es decir, ∑e i 2 ).
t – estadística:
En teoría, asumimos que el término de error sigue la distribución normal y debido a esto los parámetros b 1 y b 2 también tienen distribuciones normales con la varianza calculada en la sección anterior.
Eso es ,
- segundo 1 ∼ N( segundo 1 , σ b1 2 )
- segundo 2 ∼ N( segundo 2 , σ b2 2 )
Aquí B 1 y B 2 son verdaderas medias de b1 y b2.
t – las estadísticas se calculan asumiendo la siguiente hipótesis –
- H 0 : B 2 = 0 (la variable X no tiene influencia en Y)
- H a : B 2 ≠ 0 (X tiene un impacto significativo en Y)
Cálculos para estadísticas t:
t = ( segundo 1 – segundo 1 ) / se (segundo 1 )
De la tabla de resumen, b 1 = -3.2002 y se(b 1 ) = 0.257, Entonces,
t = (-3,2002 – 0) / 0,257 = -12,458
Similarmente, b 2 = 0.7529 , se(b 2 ) = 0.044
t = (0,7529 – 0) / 0,044 = 17,296
p – valores:
En teoría, leemos que el valor p es la probabilidad de obtener las estadísticas t al menos tan contradictorias con H 0 como se calcula asumiendo que la hipótesis nula es verdadera. En la tabla de resumen, podemos ver que el valor P para ambos parámetros es igual a 0. Esto no es exactamente 0, pero dado que tenemos estadísticas muy grandes (-12,458 y 17,296), el valor P será aproximadamente 0.
Si conoce los niveles de significación, puede ver que podemos rechazar la hipótesis nula en casi todos los niveles de significación.
Intervalos de confianza:
Existen muchos enfoques para probar la hipótesis, incluido el enfoque del valor p mencionado anteriormente. El enfoque del intervalo de confianza es uno de ellos. 5% es el nivel de significación estándar (∝) en el que se realizan los IC.
IC para B 1 es
Como ∝ = 5 %, b 1 = -3.2002, se(b 1 )=0.257 , de la tabla t , t 0.025,148 = 1.655,
Después de poner valores, el IC para B 1 es de aprox. Lo mismo se puede hacer para b 2 también.
Al calcular los valores de p, rechazamos la hipótesis nula, también podemos ver lo mismo en IC. Dado que 0 no se encuentra en ninguno de los intervalos, rechazaremos la hipótesis nula.

R – valor al cuadrado:
R 2 es el coeficiente de determinación que nos dice que tanta variación porcentual de la variable independiente puede ser explicada por la variable independiente. Aquí, el 66,9 % de variación en Y puede explicarse por X. El valor máximo posible de R 2 puede ser 1, lo que significa que cuanto mayor sea el valor de R 2 , mejor será la regresión.
F – estadística:
La prueba F dice la bondad de ajuste de una regresión. La prueba es similar a la prueba t u otras pruebas que hacemos para la hipótesis. La estadística F se calcula de la siguiente manera:

Insertando los valores de R 2 , n y k, F = (0.669/1) / (0.331/148) = 229.12.
Puede calcular la probabilidad de F >229.1 para 1 y 148 df, que llega a aprox. 0. A partir de esto, nuevamente rechazamos la hipótesis nula establecida anteriormente.
Los términos restantes no se utilizan con frecuencia. Términos como Skewness y Kurtosis hablan sobre la distribución de datos. La asimetría y la curtosis para la distribución normal son 0 y 3 respectivamente. La prueba de Jarque-Bera se utiliza para comprobar si un error tiene una distribución normal o no.