El procesamiento del lenguaje natural (PNL) es un área de la informática y la inteligencia artificial que se ocupa de las interacciones entre las computadoras y los lenguajes humanos (naturales), en particular, cómo programar las computadoras para procesar y analizar grandes cantidades de datos del lenguaje natural. Es la rama del aprendizaje automático que se trata de analizar cualquier texto y manejar el análisis predictivo.
Scikit-learn es una biblioteca de aprendizaje automático de software gratuito para el lenguaje de programación Python. Scikit-learn está escrito en gran parte en Python, con algunos algoritmos básicos escritos en Cython para lograr el rendimiento. Cython es un superconjunto del lenguaje de programación Python, diseñado para brindar un rendimiento similar al de C con código escrito principalmente en Python.
Comprendamos los diversos pasos involucrados en el procesamiento de texto y el flujo de NLP.
Este algoritmo se puede aplicar fácilmente a cualquier otro tipo de texto, como clasificar un libro en Romance, Fricción, pero por ahora, usemos un conjunto de datos de reseñas de restaurantes para revisar los comentarios negativos o positivos.
Pasos involucrados:
Paso 1: importe el conjunto de datos con el delimitador de configuración como ‘\ t’ ya que las columnas están separadas como espacio de tabulación. Las reseñas y su categoría (0 o 1) no están separadas por ningún otro símbolo, pero con espacio de tabulación, ya que la mayoría de los otros símbolos son la reseña (como $por el precio, ….!, etc.) y el algoritmo podría usarlos como un delimitador, lo que conducirá a un comportamiento extraño (como errores, salida extraña) en la salida.
Python3
# Importing Libraries
import numpy as np
import pandas as pd
# Import dataset
dataset = pd.read_csv('Restaurant_Reviews.tsv', delimiter = '\t')
Para descargar el conjunto de datos Restaurant_Reviews.tsv utilizado, haga clic aquí .
Paso 2: limpieza o preprocesamiento de texto
- Eliminar puntuaciones, números : las puntuaciones, los números no ayudan mucho en el procesamiento del texto dado, si se incluyen, solo aumentarán el tamaño de una bolsa de palabras que crearemos como último paso y disminuirán la eficiencia de un algoritmo.
- Stemming : tomar raíces de la palabra
- Convierta cada palabra en su minúscula : Por ejemplo, es inútil tener algunas palabras en diferentes casos (por ejemplo, ‘bueno’ y ‘BUENO’).
Python3
# library to clean data
import re
# Natural Language Tool Kit
import nltk
nltk.download('stopwords')
# to remove stopword
from nltk.corpus import stopwords
# for Stemming propose
from nltk.stem.porter import PorterStemmer
# Initialize empty array
# to append clean text
corpus = []
# 1000 (reviews) rows to clean
for i in range(0, 1000):
# column : "Review", row ith
review = re.sub('[^a-zA-Z]', ' ', dataset['Review'][i])
# convert all cases to lower cases
review = review.lower()
# split to array(default delimiter is " ")
review = review.split()
# creating PorterStemmer object to
# take main stem of each word
ps = PorterStemmer()
# loop for stemming each word
# in string array at ith row
review = [ps.stem(word) for word in review
if not word in set(stopwords.words('english'))]
# rejoin all string array elements
# to create back into a string
review = ' '.join(review)
# append each string to create
# array of clean text
corpus.append(review)
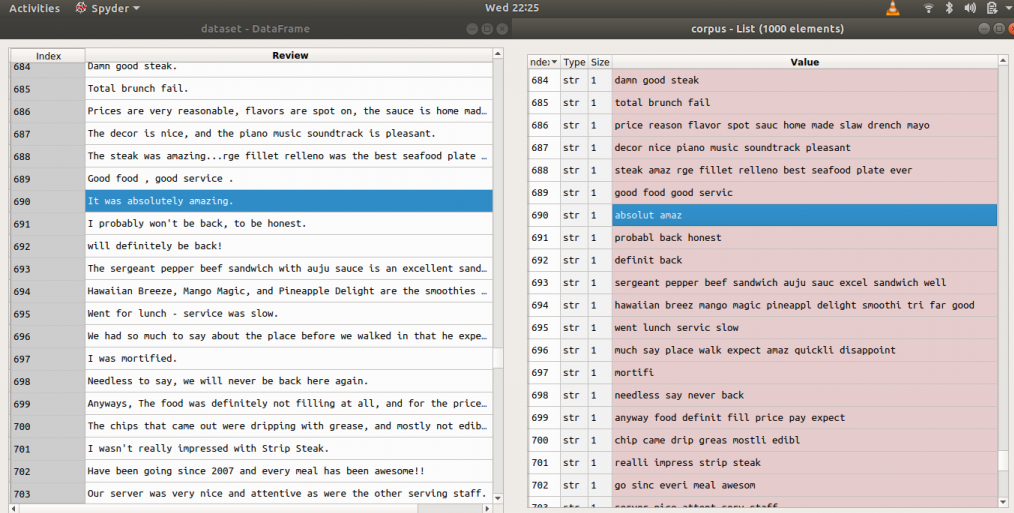
Ejemplos: antes y después de aplicar el código anterior (revisiones = > antes, corpus => después)
Paso 3: tokenización , implica dividir oraciones y palabras del cuerpo del texto.
Paso 4: hacer la bolsa de palabras a través de una array dispersa
- Tome todas las diferentes palabras de reseñas en el conjunto de datos sin repetir palabras.
- Una columna para cada palabra, por lo tanto, habrá muchas columnas.
- Las filas son reseñas
- Si hay una palabra en la fila de un conjunto de datos de reseñas, el recuento de la palabra estará en la fila de una bolsa de palabras debajo de la columna de la palabra.
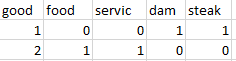
Ejemplos: Tomemos un conjunto de datos de reseñas de solo dos reseñas
Input : "dam good steak", "good food good service" Output :
Para este propósito necesitamos la clase CountVectorizer de sklearn.feature_extraction.text.
También podemos establecer un número máximo de funciones (número máximo de funciones que más ayudan a través del atributo «max_features»). Realice el entrenamiento en el corpus y luego aplique la misma transformación al corpus «.fit_transform (corpus)» y luego conviértalo en una array. Si la revisión es positiva o negativa, esa respuesta está en la segunda columna del conjunto de datos [:, 1]: todas las filas y la primera columna (indexación desde cero).
Python3
# Creating the Bag of Words model from sklearn.feature_extraction.text import CountVectorizer # To extract max 1500 feature. # "max_features" is attribute to # experiment with to get better results cv = CountVectorizer(max_features = 1500) # X contains corpus (dependent variable) X = cv.fit_transform(corpus).toarray() # y contains answers if review # is positive or negative y = dataset.iloc[:, 1].values
Descripción del conjunto de datos a utilizar:
- Columnas separadas por \t (tabulador)
- La primera columna es sobre reseñas de personas.
- En la segunda columna, 0 es para revisión negativa y 1 es para revisión positiva

Paso 5: dividir Corpus en conjuntos de entrenamiento y prueba. Para esto, necesitamos la clase train_test_split de sklearn.cross_validation. La división se puede hacer 70/30 o 80/20 o 85/15 o 75/25, aquí elijo 75/25 a través de «test_size».
X es la bolsa de palabras, y es 0 o 1 (positivo o negativo).
Python3
# Splitting the dataset into # the Training set and Test set from sklearn.cross_validation import train_test_split # experiment with "test_size" # to get better results X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25)
Paso 6: Ajuste de un modelo predictivo (aquí bosque aleatorio)
- Dado que Random Forest es un modelo de conjunto (hecho de muchos árboles) de sklearn.ensemble, importe la clase RandomForestClassifier
- Con 501 árboles o “n_estimadores” y criterio como ‘entropía’
- Ajuste el modelo a través del método .fit() con los atributos X_train y y_train
Python3
# Fitting Random Forest Classification # to the Training set from sklearn.ensemble import RandomForestClassifier # n_estimators can be said as number of # trees, experiment with n_estimators # to get better results model = RandomForestClassifier(n_estimators = 501, criterion = 'entropy') model.fit(X_train, y_train)
Paso 7: Predecir los resultados finales mediante el uso del método .predict() con el atributo X_test
Python3
# Predicting the Test set results y_pred = model.predict(X_test) y_pred

Nota: La precisión con el bosque aleatorio fue del 72 %. (Puede ser diferente cuando se realiza un experimento con diferentes tamaños de prueba, aquí = 0,25).
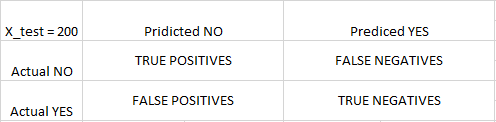
Paso 8: Para conocer la precisión, se necesita una array de confusión.
La array de confusión es una array 2X2.
VERDADERO POSITIVO: mide la proporción de positivos reales que están correctamente identificados.
VERDADERO NEGATIVO: mide la proporción de positivos reales que no están correctamente identificados.
FALSO POSITIVO: mide la proporción de negativos reales que están correctamente identificados.
FALSO NEGATIVO: mide la proporción de negativos reales que no están correctamente identificados.
Nota: Verdadero o Falso se refiere a que la clasificación asignada sea Correcta o Incorrecta, mientras que Positivo o Negativo se refiere a la asignación a la Categoría Positiva o Negativa
Python3
# Making the Confusion Matrix from sklearn.metrics import confusion_matrix cm = confusion_matrix(y_test, y_pred) cm

Publicación traducida automáticamente
Artículo escrito por mananmongia y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA