Los algoritmos de coincidencia de strings han influido mucho en la informática y juegan un papel esencial en varios problemas del mundo real. Ayuda a realizar tareas eficientes en el tiempo en múltiples dominios. La coincidencia de strings también se utiliza en el esquema de base de datos , sistemas de red.
Veamos algunos algoritmos de coincidencia de strings antes de proceder a sus aplicaciones en el mundo real. Los algoritmos de coincidencia de strings se pueden clasificar en términos generales en dos tipos de algoritmos:
- Algoritmos de coincidencia de strings exactas
- Algoritmos aproximados de coincidencia de strings
Algoritmos de coincidencia de strings exactas:
Los algoritmos de coincidencia de strings exactas consisten en encontrar una, varias o todas las apariciones de una string definida (patrón) en una string grande (texto o secuencias) de modo que cada coincidencia sea perfecta. Todos los alfabetos de patrones deben coincidir con la subsecuencia coincidente correspondiente. Estos se clasifican además en cuatro categorías:
- Algoritmos basados en la comparación de caracteres:
- Algoritmo ingenuo: desliza el patrón sobre el texto uno por uno y busca una coincidencia. Si se encuentra una coincidencia, deslícese por 1 nuevamente para buscar coincidencias posteriores.
- Algoritmo KMP (Knuth Morris Pratt): La idea es que cada vez que se detecta una falta de coincidencia, ya conocemos algunos de los caracteres en el texto de la siguiente ventana. Por lo tanto, aprovechamos esta información para evitar la coincidencia de los caracteres que sabemos que coincidirán de todos modos.
- Algoritmo de Boyer Moore: este algoritmo utiliza las mejores heuréticas del algoritmo Naive y KMP y comienza a hacer coincidir desde el último carácter del patrón.
- Uso de la estructura de datos Trie: se utiliza como una estructura de datos de recuperación de información eficiente. Almacena las claves en forma de BST equilibrado.
- Método determinista de autómatas finitos (DFA):
- Algoritmo de comparación de autómatas: parte del primer estado de los autómatas y el primer carácter del texto. En cada paso, considera el siguiente carácter del texto y busca el siguiente estado en los autómatas finitos construidos y pasa a un nuevo estado.
- Algoritmos basados en Bit (método de paralelismo):
- Algoritmo de Aho-Corasick: encuentra todas las palabras en tiempo O (n + m + z), donde n es la longitud del texto y m es el número total de caracteres en todas las palabras y z es el número total de ocurrencias de palabras en el texto. Este algoritmo constituye la base del comando fgrep original de Unix.
- Algoritmos de coincidencia de strings hash:
- Algoritmo de Rabin Karp: hace coincidir el valor hash del patrón con el valor hash de la substring de texto actual, y si los valores hash coinciden, solo comienza a hacer coincidir los caracteres individuales.
Algoritmos aproximados de coincidencia de strings:
Los algoritmos de coincidencia de strings aproximadas (también conocidos como búsqueda de strings aproximadas) buscan substrings de la string de entrada. Más específicamente, el enfoque aproximado de coincidencia de strings se establece de la siguiente manera: supongamos que tenemos dos strings, el texto T[1…n] y el patrón P[1…m]. La tarea es encontrar todas las apariciones de patrones en el texto cuya distancia de edición al patrón sea como máximo k. Algunas distancias de edición conocidas son: la distancia de edición de Levenshtein y la distancia de edición de Hamming .
Estas técnicas se utilizan cuando la calidad del texto es baja, hay errores ortográficos en el patrón o texto, encontrar subsecuencias de ADN después de la mutación, bases de datos heterogéneas, etc. Algunos algoritmos de coincidencia de strings aproximadas son:
- Enfoque ingenuo: desliza el patrón sobre el texto uno por uno y verifica las coincidencias aproximadas. Si se encuentran, vuelva a deslizar por 1 para comprobar si hay coincidencias aproximadas posteriores.
- Algoritmo de vendedores (programación dinámica)
- Cambio o algoritmo (algoritmo de mapa de bits)
Aplicaciones de los algoritmos de coincidencia de strings:
- Detección de plagio: los documentos que se van a comparar se descomponen en tokens de string y se comparan mediante algoritmos de coincidencia de strings. Así, estos algoritmos se utilizan para detectar similitudes entre ellos y declarar si el trabajo es plagiado u original.

- Bioinformática y secuenciación de ADN: la bioinformática implica aplicar tecnología de la información y ciencias de la computación a problemas relacionados con secuencias genéticas para encontrar patrones de ADN. Los algoritmos de coincidencia de strings y el análisis de ADN se utilizan colectivamente para encontrar la ocurrencia del conjunto de patrones.

- Análisis forense digital: los algoritmos de coincidencia de strings se utilizan para ubicar strings de texto específicas de interés en el texto forense digital, que son útiles para la investigación.
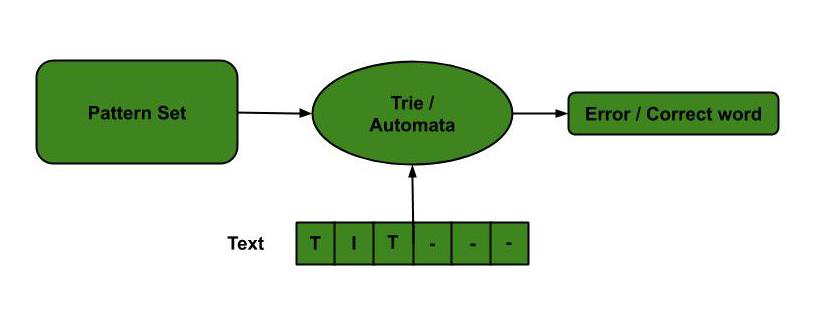
- Corrector ortográfico: Trie se basa en un conjunto predefinido de patrones. Luego, este trie se usa para la coincidencia de strings. El texto se toma como entrada y, si se produce algún patrón de este tipo, se muestra alcanzando el estado de aceptación.
- Filtros de correo no deseado : los filtros de correo no deseado utilizan la coincidencia de strings para descartar el correo no deseado. Por ejemplo, para categorizar un correo electrónico como spam o no, las palabras clave sospechosas de spam se buscan en el contenido del correo electrónico mediante algoritmos de coincidencia de strings. Por lo tanto, el contenido se clasifica como spam o no.

- Motores de búsqueda o búsqueda de contenido en grandes bases de datos: Para categorizar y organizar los datos de manera eficiente, se utilizan algoritmos de coincidencia de strings. La categorización se realiza en función de las palabras clave de búsqueda. Por lo tanto, los algoritmos de coincidencia de strings facilitan que uno encuentre la información que está buscando.

- Sistema de detección de intrusiones: los paquetes de datos que contienen palabras clave relacionadas con intrusiones se encuentran aplicando algoritmos de coincidencia de strings. Todo el código malicioso se almacena en la base de datos y todos los datos entrantes se comparan con los datos almacenados. Si se encuentra una coincidencia, se genera la alarma. Se basa en algoritmos de coincidencia de strings exactas en los que se debe detectar cada paquete intruso.

Publicación traducida automáticamente
Artículo escrito por eshwitha_reddy y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA