En la regresión lineal o múltiple, no basta con ajustar el modelo al conjunto de datos. Pero, puede que no dé el resultado deseado. Para aplicar la regresión lineal o múltiple de manera eficiente al conjunto de datos. Hay algunas suposiciones que debemos verificar en el conjunto de datos que hizo que la regresión lineal/múltiple sea eficiente y genere una mayor precisión.
Supuestos de regresión
El análisis de regresión requiere que el conjunto de datos siga algunos supuestos. Estos supuestos son:
- Las observaciones son independientes entre sí. Debe estar correlacionado con otra observación.
- Los datos se distribuyen normalmente.
- La relación entre la variable independiente y la media de la variable dependiente es lineal.
- Los datos están en homocedasticidad, lo que significa que la varianza del residuo es la misma para cada valor de la variable dependiente.
Para realizar un buen análisis de regresión lineal, también debemos verificar si se violan estas suposiciones:
- Si los datos contienen tendencias no lineales, no se ajustarán correctamente mediante regresión lineal, lo que dará como resultado una alta tasa de error o residual.
- Para verificar la normalidad en el conjunto de datos, dibuje un gráfico QQ en los datos.
- La presencia de correlación entre las observaciones se conoce como autocorrelación. Podemos comprobar el gráfico de autocorrelación.
- La presencia de homocedasticidad se puede estimar con gráficos como el gráfico de ubicación de escala y el gráfico residual vs legado.
Gráficos de diagnóstico de regresión
Los gráficos anteriores se pueden usar para validar y probar las suposiciones anteriores como parte del diagnóstico de regresión. Este diagnóstico se puede utilizar para comprobar si los supuestos. Antes de discutir el gráfico de diagnóstico uno por uno, analicemos algunos términos importantes:
- Valores atípicos : los valores atípicos son los puntos que son distintos y se desvían de la mayor parte del conjunto de datos. En general, los valores atípicos tienen valores residuales altos, lo que significa que la diferencia es mayor que el valor b/w observado y predicho.
- Puntos de apalancamiento : un punto de apalancamiento se define como una observación que tiene un valor de x que está lejos de la media de x.
- Puntos influyentes : una observación influyente se define como una observación que tiene una gran influencia en el ajuste del modelo. Un método para encontrar puntos influyentes es comparar el ajuste del modelo con y sin cada observación.
A continuación se muestran las parcelas que utilizamos en la parcela de diagnóstico:
- Residual vs gráfico ajustado: El residual se puede calcular como:

Esta gráfica se utiliza para verificar la linealidad y la homocedasticidad, si el modelo cumple con la condición de relación lineal, entonces debería tener una línea horizontal con mucha desviación. Si el modelo cumple la condición de homocedasticidad, la gráfica debe distribuirse equitativamente alrededor de la línea y=0.
- Gráfica QQ: esta gráfica se usa para verificar la normalidad del conjunto de datos, si existe normalidad en el conjunto de datos, los puntos de dispersión se distribuirán a lo largo de la línea discontinua de 45 grados.
- Gráfico de ubicación de escala: es un gráfico de valor estandarizado de raíz cuadrada frente al valor predicho. Este gráfico se utiliza para comprobar la homocedasticidad de los residuos. Los residuos igualmente distribuidos a lo largo de la línea horizontal indican la homocedasticidad de los residuos.
- Gráfica de residuos frente a apalancamiento / Gráfica de distancia de Cook: El cuarto punto es la gráfica de distancia de Cook, que se utiliza para medir la influencia de las diferentes gráficas. La estadística de distancia de Cook para cada observación mide el grado de cambio en las estimaciones del modelo cuando se omite esa observación en particular. Distancia de cocción grafique la medida de distancia de cocción de cada observación. mientras que el gráfico Residual vs Leverage es el gráfico entre los residuos estandarizados y los puntos de apalancamiento de los puntos.
Implementación
En esta implementación, trazaremos diferentes gráficos de diagnóstico. Para eso, usamos el conjunto de datos de Bienes Raíces y aplicamos la Regresión de Mínimos Cuadrados Ordinarios (OLS). Luego trazamos la gráfica de diagnóstico de regresión y la gráfica de distancia de Cook.
Python3
# imports
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
import statsmodels.formula.api as smf
# Load Real State Data
data = pd.read_csv('/content/Real estate.csv')
data.head()
# Fit a OLS regression variable
model =smf.ols(formula=' Y ~ X3 + X2', data= data )
results = model.fit()
print(results.summary())
# Get different Variables for diagnostic
residuals = results.resid
fitted_value = results.fittedvalues
stand_resids = results.resid_pearson
influence = results.get_influence()
leverage = influence.hat_matrix_diag
# PLot different diagnostic plots
plt.rcParams["figure.figsize"] = (20,15)
fig, ax = plt.subplots(nrows=2, ncols=2)
plt.style.use('seaborn')
# Residual vs Fitted Plot
sns.scatterplot(x=fitted_value, y=residuals, ax=ax[0, 0])
ax[0, 0].axhline(y=0, color='grey', linestyle='dashed')
ax[0, 0].set_xlabel('Fitted Values')
ax[0, 0].set_ylabel('Residuals')
ax[0, 0].set_title('Residuals vs Fitted Fitted')
# Normal Q-Q plot
sm.qqplot(residuals, fit=True, line='45',ax=ax[0, 1], c='#4C72B0')
ax[0, 1].set_title('Normal Q-Q')
# Scale-Location Plot
sns.scatterplot(x=fitted_value, y=residuals, ax=ax[1, 0])
ax[1, 0].axhline(y=0, color='grey', linestyle='dashed')
ax[1, 0].set_xlabel('Fitted values')
ax[1, 0].set_ylabel('Sqrt(standardized residuals)')
ax[1, 0].set_title('Scale-Location Plot')
# Residual vs Leverage Plot
sns.scatterplot(x=leverage, y=stand_resids, ax=ax[1, 1])
ax[1, 1].axhline(y=0, color='grey', linestyle='dashed')
ax[1, 1].set_xlabel('Leverage')
ax[1, 1].set_ylabel('Sqrt(standardized residuals)')
ax[1, 1].set_title('Residuals vs Leverage Plot')
plt.tight_layout()
plt.show()
# PLot Cook's distance plot
sm.graphics.influence_plot(results, criterion="cooks")
------------
# data
No X1 X2 X3 X4 X5 X6 Y
0 1 2012.917 32.0 84.87882 10 24.98298 121.54024 37.9
1 2 2012.917 19.5 306.59470 9 24.98034 121.53951 42.2
2 3 2013.583 13.3 561.98450 5 24.98746 121.54391 47.3
3 4 2013.500 13.3 561.98450 5 24.98746 121.54391 54.8
4 5 2012.833 5.0 390.56840 5 24.97937 121.54245 43.1
------------
OLS Regression Results
==============================================================================
Dep. Variable: Y R-squared: 0.491
Model: OLS Adj. R-squared: 0.489
Method: Least Squares F-statistic: 198.3
Date: Thu, 19 Aug 2021 Prob (F-statistic): 5.07e-61
Time: 17:56:17 Log-Likelihood: -1527.9
No. Observations: 414 AIC: 3062.
Df Residuals: 411 BIC: 3074.
Df Model: 2
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 49.8856 0.968 51.547 0.000 47.983 51.788
X3 -0.0072 0.000 -18.997 0.000 -0.008 -0.006
X2 -0.2310 0.042 -5.496 0.000 -0.314 -0.148
==============================================================================
Omnibus: 161.397 Durbin-Watson: 2.130
Prob(Omnibus): 0.000 Jarque-Bera (JB): 1297.792
Skew: 1.443 Prob(JB): 1.54e-282
Kurtosis: 11.180 Cond. No. 3.37e+03
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 3.37e+03. This might indicate that there are
strong multicollinearity or other numerical problems.
--------------
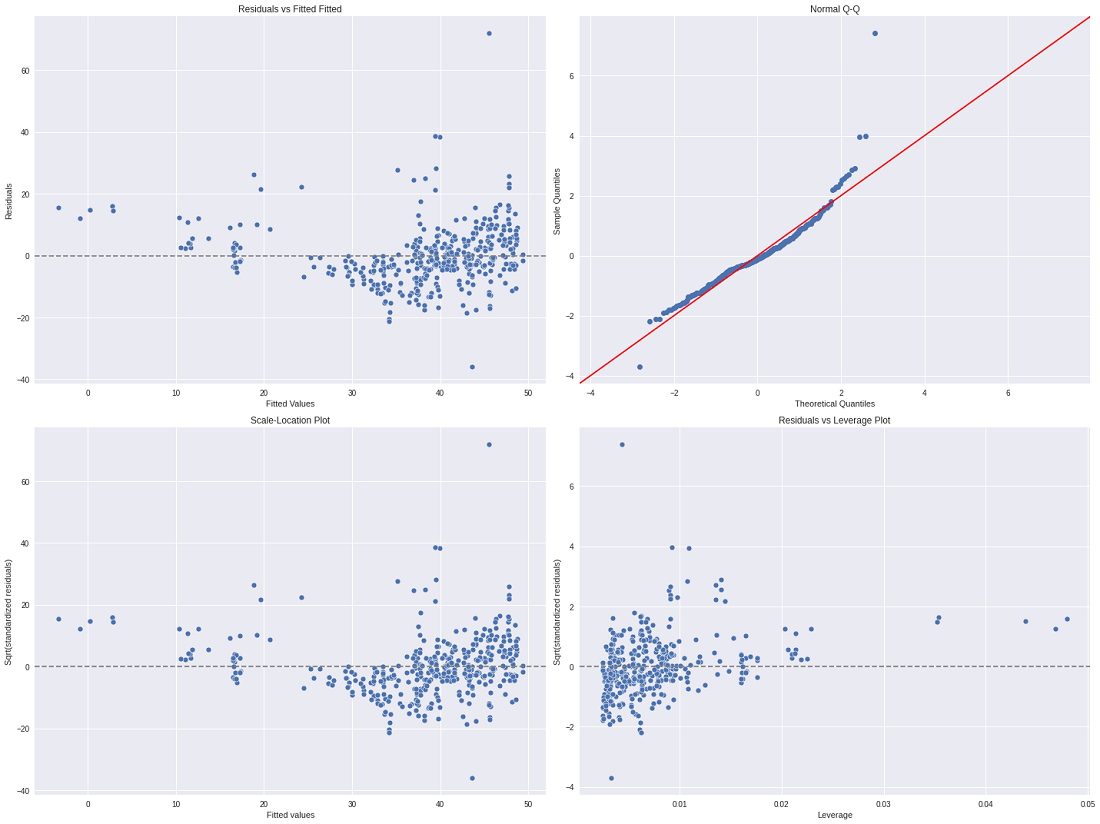
Gráficos de diagnóstico de regresión
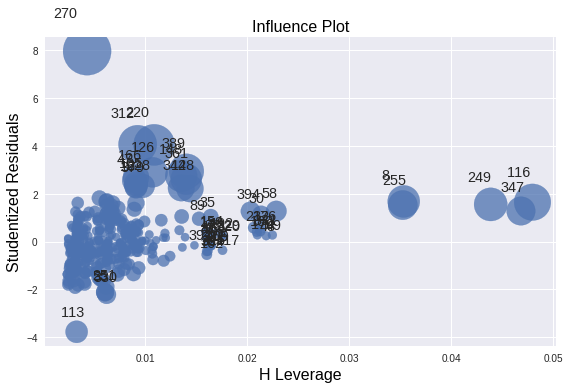
Gráfico de distancia de cocción