Un aspecto importante del aprendizaje automático es la evaluación del modelo. Necesita tener algún mecanismo para evaluar su modelo. Aquí es donde estas métricas de rendimiento entran en escena, nos dan una idea de lo bueno que es un modelo. Si está familiarizado con algunos conceptos básicos de Machine Learning, debe conocer algunas de estas métricas como exactitud, precisión, recuperación, auc-roc, etc.
Digamos que está trabajando en un problema de clasificación binaria y obtiene un modelo con un 95% de precisión, ahora alguien le pregunta qué significa eso que sería lo suficientemente rápido como para decir que de 100 predicciones que hace su modelo, 95 de ellas son correctas. Bueno, mejoremos un poco, ahora la métrica subyacente es el recuerdo y se le hace la misma pregunta, puede tomarse un momento aquí, pero eventualmente, se le ocurrirá una explicación como de 100 puntos de datos relevantes (clase positiva en general ) tu modelo es capaz de identificar 80 de ellos. Hasta ahora todo bien, ahora supongamos que evaluó su modelo usando AUC-ROC como métrica y obtuvo un valor de 0.75 y nuevamente le hago la misma pregunta: ¿qué significa 0.75 o 75%? Ahora es posible que deba darlo. un pensamiento, algunos de ustedes podrían decir que hay un 75% de posibilidades de que el modelo identifique un punto de datos correctamente, pero a estas alturas ya se habrán dado cuenta de que no es así. Tratemos de obtener una comprensión básica de una de las métricas de rendimiento más utilizadas para problemas de clasificación.
Historia:
Si ha participado en alguna competencia/hackatón de aprendizaje automático en línea, entonces debe haberse topado con la Característica del operador del receptor del área bajo la curva, también conocida como AUC-ROC, muchos de ellos la tienen como criterio de evaluación para sus problemas de clasificación. Admitamos que la primera vez que escuchó sobre él, este pensamiento debe haber pasado por su mente una vez, ¿qué pasa con el nombre largo? Bueno, el origen de la curva ROC se remonta a la Segunda Guerra Mundial, se usó originalmente para el análisis de señales de radar. El ejército de los Estados Unidos trató de medir la capacidad de su receptor de radar para identificar correctamente la aeronave japonesa. Ahora que tenemos un poco de historia de origen, pongámonos manos a la obra.
Interpretación Geométrica:
Esta es la definición más común que habría encontrado cuando buscaba en Google AUC-ROC. Básicamente, la curva ROC es un gráfico que muestra el rendimiento de un modelo de clasificación en todos los umbrales posibles (el umbral es un valor particular más allá del cual dice que un punto pertenece a una clase particular). La curva se traza entre dos parámetros.
- TASA VERDADERA POSITIVA
- TASA DE FALSOS POSITIVOS
Antes de entender, TPR y FPR veamos rápidamente la array de confusión.
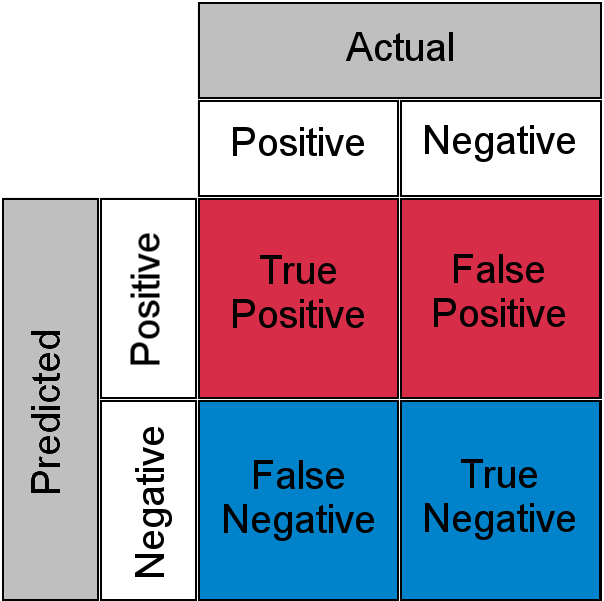
Fuente: Creative Commons
- Verdadero positivo : Positivo real y Predicho como positivo
- Negativo verdadero : Negativo real y Predicho como negativo
- Falso positivo (Error de tipo I) : Negativo real pero predicho como positivo
- Falso Negativo (Error Tipo II) : Positivo Real pero predicho como Negativo
En términos simples, puede llamar falso positivo como falsa alarma y falso negativo como error . Ahora echemos un vistazo a lo que es TPR y FPR.
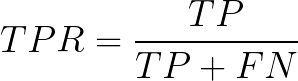
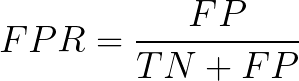
Básicamente, TPR/Recall/Sensitivity es la proporción de ejemplos positivos que se identifican correctamente y FPR es la proporción de ejemplos negativos que se clasifican incorrectamente .
y como se dijo anteriormente, ROC no es más que el gráfico entre TPR y FPR en todos los umbrales posibles y AUC es el área completa debajo de esta curva ROC.
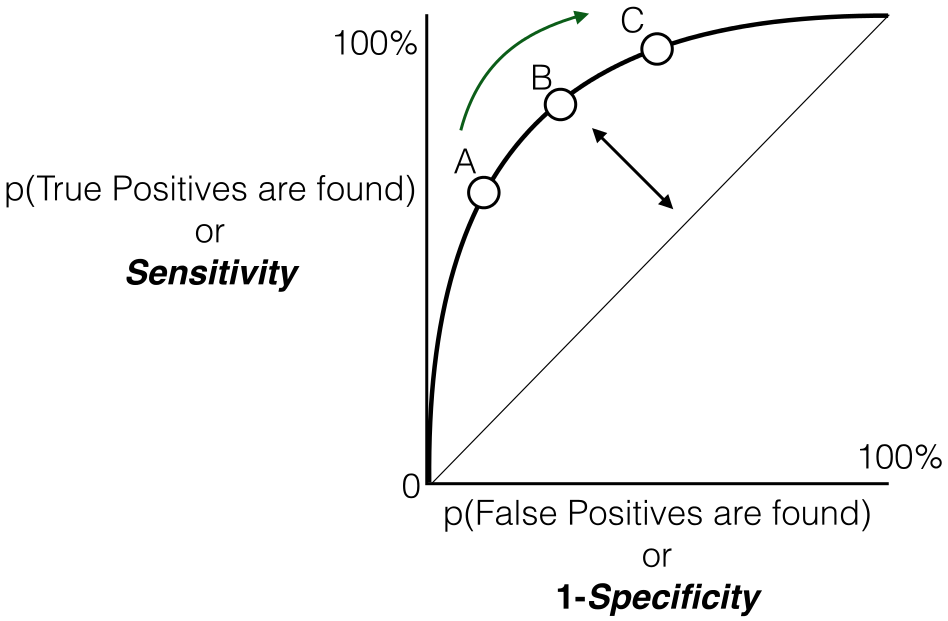
Fuente: Creative Commons
INTERPRECIÓN PROBABILÍSTICA:
Vimos la interpretación geométrica, pero supongo que todavía no es suficiente para desarrollar la intuición detrás de lo que realmente significa 0.75 AUC, ahora veamos AUC-ROC con un punto de vista probabilístico.
Permítanme hablar primero sobre lo que hace AUC y luego desarrollaremos nuestra comprensión sobre esto.
AUC mide qué tan bien un modelo es capaz de distinguir entre clases
Un AUC de 0.75 en realidad significaría que, digamos que tomamos dos puntos de datos que pertenecen a clases separadas, entonces hay un 75% de posibilidades de que el modelo pueda segregarlos u ordenarlos correctamente, es decir, el punto positivo tiene una probabilidad de predicción más alta que la clase negativa. (suponiendo que una probabilidad de predicción más alta significa que el punto pertenecería idealmente a la clase positiva)
Aquí hay un pequeño ejemplo para hacer las cosas más claras.
| Índice | Clase | Probabilidad |
|---|---|---|
| P1 | 1 | 0,95 |
| P2 | 1 | 0.90 |
| P3 | 0 | 0.85 |
| P4 | 0 | 0.81 |
| P5 | 1 | 0.78 |
| P6 | 0 | 0.70 |
Aquí tenemos 6 puntos donde P1, P2, P5 pertenecen a la clase 1 y P3, P4, P6 pertenecen a la clase 0 y somos las probabilidades predichas correspondientes en la columna de Probabilidad, como dijimos si tomamos dos puntos que pertenecen a clases separadas, entonces ¿Cuál es la probabilidad de que Model Rank los ordene correctamente?
Tomaremos todos los pares posibles de modo que un punto pertenezca a la clase 1 y el otro pertenezca a la clase 0, tendremos un total de 9 de esos pares a continuación son todos estos 9 pares posibles
| Par | es correcto |
|---|---|
| (P1,P3) | Sí |
| (P1,P4) | Sí |
| (P1,P6) | Sí |
| (P2,P3) | Sí |
| (P2,P4) | Sí |
| (P2,P6) | Sí |
| (P3,P5) | No |
| (P4,P5) | No |
| (P5,P6) | Sí |
Aquí la columna isCorrect indica si el par mencionado es correcto en orden de clasificación en función de la probabilidad predicha, es decir, el punto de clase 1 tiene una probabilidad más alta que el punto de clase 0, en 7 de estos 9 pares posibles, la clase 1 está clasificada más alta que la clase 0, o podemos decir que hay un 77% de posibilidades de que si elige un par de puntos que pertenecen a clases separadas, el modelo pueda distinguirlos correctamente. Ahora, creo que podría tener un poco de intuición detrás de este número AUC, solo para aclarar cualquier otra duda, validémoslo usando la implementación AUC-ROC de scikit learn
Código de implementación de Python:
python3
import numpy as np
from sklearn .metrics import roc_auc_score
y_true = [1, 1, 0, 0, 1, 0]
y_pred = [0.95, 0.90, 0.85, 0.81, 0.78, 0.70]
auc = np.round(roc_auc_score(y_true, y_pred), 3)
print("Auc for our sample data is {}". format(auc))
Cuándo usar:
Habiendo dicho eso, hay ciertos lugares donde ROC-AUC podría no ser ideal.
- ROC-AUC no funciona bien bajo un desequilibrio severo en el conjunto de datos, para dar algo de intuición sobre esto, echemos un vistazo a la interpretación geométrica aquí. Básicamente, ROC es la trama entre TPR y FPR (asumiendo que la clase minoritaria es una clase positiva), ahora echemos un vistazo de cerca a la fórmula FPR nuevamente
El denominador de FPR tiene Negativos verdaderos como un factor, ya que la Clase negativa es mayoritaria. El denominador de FPR está dominado por Negativos verdaderos, lo que hace que FPR sea menos sensible a cualquier cambio en las predicciones de clase minoritaria. Para superar esto, se usan curvas de recuperación de precisión en lugar de ROC y luego se calcula el AUC, intente responder esto usted mismo. ¿Cómo maneja este problema la curva de recuperación de precisión? solo compare los denominadores para ambos e intente evaluar cómo se resuelve el problema de desequilibrio aquí)
- ROC-AUC intenta medir si el orden de rango de las clasificaciones es correcto, no tiene en cuenta las probabilidades realmente predichas, permítanme tratar de aclarar este punto con un pequeño fragmento de código
python3
import pandas as pd y_pred_1 = [0.99, 0.98, 0.97, 0.96, 0.91, 0.90, 0.89, 0.88] y_pred_2 = [0.99, 0.95, 0.90, 0.85, 0.20, 0.15, 0.10, 0.05] y_act = [1, 1, 1, 1, 0, 0, 0, 0] test_df = pd.DataFrame(zip(y_act, y_pred_1, y_pred_2), columns=['Class', 'Model_1', 'Model_2'])
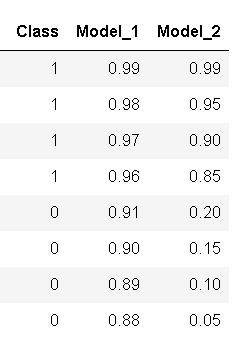
Probabilidades de clase para dos modelos de muestra
Tenemos dos modelos Model_1 y Model_2 como se mencionó anteriormente, ambos hacen un trabajo perfecto al segregar las dos clases, pero si le pido que elija uno entre ellos, ¿cuál sería? Guarde su respuesta. Déjame primero trazar estas probabilidades del modelo. .
python3
import matplotlib.pyplot as plt cols = ['Model_1', 'Model_2'] fig, axs = plt.subplots(1, 2, figsize=(15, 5)) for index, col in enumerate(cols): sns.kdeplot(d2[d2['Status'] == 1][col], label="Class 1", shade=True, ax=axs[index]) sns.kdeplot(d2[d2['Status'] == 0][col], label="Class 0", shade=True, ax=axs[index]) axs[index].set_xlabel(col) plt.show()
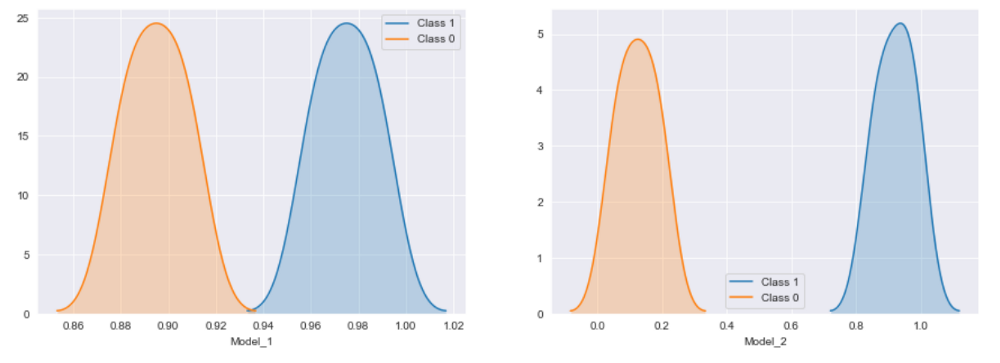
Distribución de probabilidad de clase para modelos de muestra
Si hubiera alguna mínima duda antes, supongo que ahora su elección sería bastante clara, Model_2 es un claro ganador. Pero los valores AUC-ROC serían los mismos para ambos, este es el inconveniente que solo mide si el modelo puede ordenar las clases correctamente, no analiza qué tan bien el modelo separa las dos clases, por lo tanto, si tiene un requisito donde desea utilizar las probabilidades realmente predichas, entonces roc podría no ser la opción correcta, para aquellos que sienten curiosidad, la pérdida de registros es una de esas métricas que resuelve este problema
Por lo tanto, lo ideal sería usar AUC cuando el conjunto de datos no tenga un desequilibrio severo y cuando su caso de uso no requiera que use las probabilidades reales previstas.
AUC PARA MULTICLASE:
Para una configuración de varias clases, simplemente podemos usar la metodología uno contra todos y tendrá una curva ROC para cada clase. Digamos que tiene cuatro clases A, B, C, D, entonces habría curvas ROC y valores AUC correspondientes para las cuatro clases, es decir, una vez que A sería una clase y B, C y D combinados serían las otras clases, de manera similar B es una clase y A, C y D combinados como otras clases, etc.
Publicación traducida automáticamente
Artículo escrito por ravindrasharmaravindrasharma y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA