El agrupamiento jerárquico en el lenguaje de programación R es un algoritmo no lineal no supervisado en el que se crean grupos de manera que tengan una jerarquía (o un orden predeterminado). Por ejemplo, considere una familia de hasta tres generaciones. Un abuelo y una madre tienen a sus hijos que se convierten en padre y madre de sus hijos. Por lo tanto, todos se agrupan en la misma familia, es decir, forman una jerarquía.
R – Agrupación jerárquica
La agrupación jerárquica es de dos tipos:
- Agrupamiento jerárquico aglomerativo: comienza en hojas individuales y fusiona con éxito los grupos. Es un enfoque de abajo hacia arriba.
- Agrupación jerárquica divisiva: comienza en la raíz y divide recursivamente las agrupaciones. Es un enfoque de arriba hacia abajo.
Teoría:
En el agrupamiento jerárquico, los objetos se clasifican en una jerarquía similar a una estructura en forma de árbol que se utiliza para interpretar modelos de agrupamiento jerárquico. El algoritmo es como sigue:
- Convierta cada punto de datos en un grupo de un solo punto que forme N grupos.
- Tome los dos puntos de datos más cercanos y conviértalos en un grupo que forme grupos N-1 .
- Tome los dos grupos más cercanos y conviértalos en un grupo que forme N-2 grupos.
- Repita los pasos 3 hasta que solo haya un grupo.
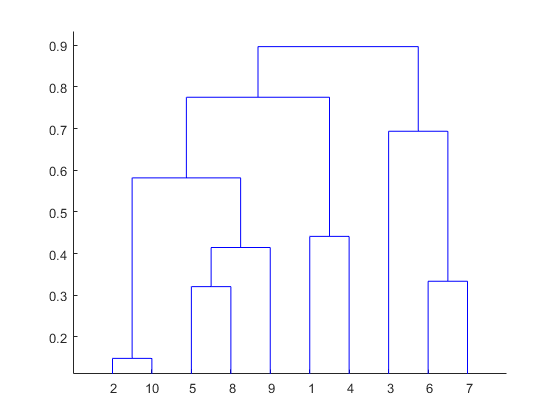
El dendrograma es una jerarquía de grupos en la que las distancias se convierten en alturas. Agrupa n unidades u objetos, cada uno con función p en grupos más pequeños. Las unidades en el mismo grupo están unidas por una línea horizontal. Las hojas en la parte inferior representan unidades individuales. Proporciona una representación visual de los clústeres.
Regla del pulgar: la distancia vertical más grande que no corta ninguna línea horizontal define el número óptimo de grupos.
El conjunto de datos
mtcars (prueba de carretera de automóviles de tendencia del motor) comprende el consumo de combustible, el rendimiento y 10 aspectos del diseño del automóvil para 32 automóviles. Viene preinstalado con el paquete dplyr en R.
R
# Installing the package
install.packages("dplyr")
# Loading package
library(dplyr)
# Summary of dataset in package
head(mtcars)
Producción:

Realización de agrupamiento jerárquico en conjunto de datos
Usando el algoritmo de agrupamiento jerárquico en el conjunto de datos usando hclust() que está preinstalado en el paquete de estadísticas cuando R está instalado.
R
# Finding distance matrix distance_mat <- dist(mtcars, method = 'euclidean') distance_mat # Fitting Hierarchical clustering Model # to training dataset set.seed(240) # Setting seed Hierar_cl <- hclust(distance_mat, method = "average") Hierar_cl # Plotting dendrogram plot(Hierar_cl) # Choosing no. of clusters # Cutting tree by height abline(h = 110, col = "green") # Cutting tree by no. of clusters fit <- cutree(Hierar_cl, k = 3 ) fit table(fit) rect.hclust(Hierar_cl, k = 3, border = "green")
Producción:
- Array de distancia:
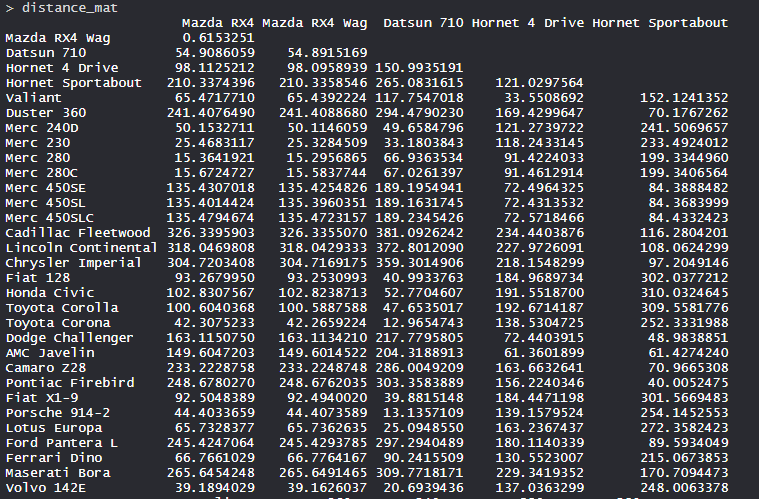
- Los valores se muestran según el cálculo de la array de distancia con el método euclidiano.
- Modelo Hierar_cl:
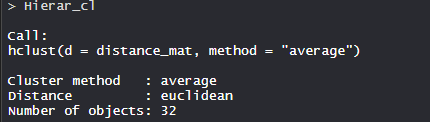
- En el modelo, el método de conglomerados es promedio, la distancia es euclidiana y no. de objetos son 32.
- Trazar dendograma:

- El dendograma de la trama se muestra con el eje x como array de distancia y el eje y como altura.
- Árbol cortado:
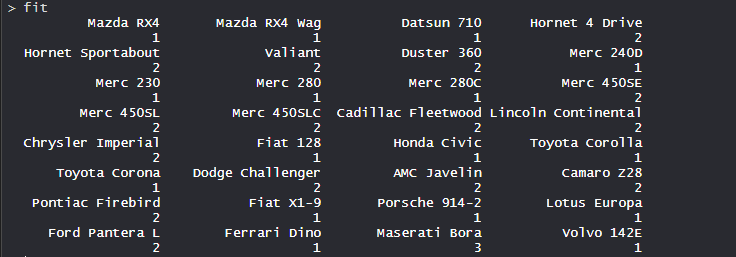
- Entonces, Tree se corta donde k = 3 y cada categoría representa su número de grupos.
- Trazado del dendrograma después del corte:

- La trama denota dendrograma después de ser cortado. Las líneas verdes muestran el número de grupos según la regla del pulgar.