El ciclo de vida de la ciencia de datos gira en torno al uso del aprendizaje automático y diferentes estrategias analíticas para producir conocimientos y predicciones a partir de la información con el fin de adquirir un objetivo empresarial comercial. El método completo incluye una serie de pasos como la limpieza de datos, la preparación, el modelado, la evaluación del modelo, etc. Es un procedimiento largo y, además, puede tardar varios meses en completarse. Por lo tanto, es muy importante tener una estructura genérica para observar todos y cada uno de los problemas a la mano. La estructura mencionada globalmente para solucionar cualquier problema analítico se conoce como Proceso estándar de la industria cruzada para la minería de datos o marco CRISP-DM.
Entendamos cuál es la necesidad de la ciencia de datos.
Los datos anteriores solían ser mucho menos y generalmente accesibles en una forma bien estructurada, que podíamos guardar sin esfuerzo y fácilmente en hojas de Excel, y con la ayuda de las herramientas de Business Intelligence, los datos se pueden procesar de manera eficiente. Pero hoy en día solíamos tratar con grandes cantidades de datos, como alrededor de 3,0 quintales bytes de registros que se producen todos los días, lo que finalmente resulta en una explosión de registros y datos. Según investigaciones recientes, se estima que 1,9 MB de datos y registros se crean en un segundo también a través de un solo individuo.
Así que este es un desafío muy grande para cualquier organización para lidiar con una cantidad tan masiva de datos que se generan cada segundo. Para manejar y evaluar estos datos, requerimos algunos algoritmos y tecnologías muy potentes y complejos, y aquí es donde entra en escena la ciencia de datos.
Los siguientes son algunos motivos principales para el uso de la tecnología de ciencia de datos:
- Ayuda a convertir la gran cantidad de registros sin procesar y sin estructurar en información significativa.
- Puede ayudar en predicciones únicas, como una variedad de encuestas, elecciones, etc.
- También ayuda a automatizar el transporte, como hacer crecer un automóvil autónomo, podemos decir cuál es el futuro del transporte.
- Las empresas están cambiando hacia la ciencia de datos y optando por esta tecnología. Amazon, Netflix, etc., que se ocupan de la gran cantidad de datos, utilizan algoritmos de ciencia de la información para mejorar la experiencia del consumidor.
El ciclo de vida de la ciencia de datos
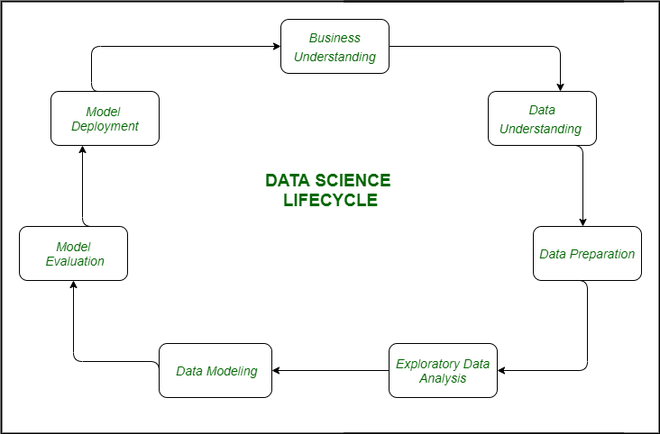
1. Comprensión empresarial: el ciclo completo gira en torno al objetivo empresarial. ¿Qué vas a resolver si ya no tienes un problema específico? Es muy importante comprender el objetivo de la empresa comercial con sinceridad porque ese será el objetivo final de la investigación. Después de la percepción deseable, solo podemos establecer el objetivo preciso de la evaluación que está en sintonía con el objetivo de la empresa. Debe comprender si el cliente desea minimizar la pérdida de ahorros, o si prefiere predecir la tasa de un producto, etc.
2. Comprensión de datos: después de la comprensión empresarial, el siguiente paso es la comprensión de datos. Esto incluye una serie de todos los datos accesibles. Aquí debe trabajar atentamente con el grupo de empresas comerciales, ya que ciertamente son conscientes de qué información está presente, qué hechos deben usarse para este problema de empresa comercial y otra información. Este paso incluye la descripción de los datos, su estructura, su relevancia, su tipo de registro. Explore la información utilizando diagramas gráficos. Básicamente, extraer cualquier dato que pueda obtener sobre la información simplemente explorando los datos.
3. Preparación de datos: Luego viene la etapa de preparación de datos. Esto consiste en pasos como elegir los datos aplicables, integrar los datos mediante la fusión de los conjuntos de datos, limpiarlos, tratar los valores que faltan eliminándolos o imputándolos, tratando los datos inexactos eliminándolos, además, pruebe los valores atípicos mediante el uso de diagramas de caja y hacerles frente. Construir nuevos datos, derivar nuevos elementos de los presentes. Formatee los datos en la estructura preferida, elimine columnas y características no deseadas. La preparación de datos es el paso que requiere más tiempo pero posiblemente el más esencial en el ciclo de existencia completo. Su modelo será tan preciso como sus datos.
4. Análisis exploratorio de datos: este paso incluye obtener alguna idea sobre la respuesta y los elementos que la afectan, antes de construir el modelo real. La distribución de datos dentro de variables distintivas de un personaje se explora gráficamente mediante el uso de gráficos de barras. Las relaciones entre distintos aspectos se capturan a través de representaciones gráficas como diagramas de dispersión y mapas de calor. Muchas estrategias de visualización de datos se utilizan considerablemente para descubrir todas y cada una de las características de forma individual y combinándolas con diferentes funcionalidades.
5. Modelado de datos: el modelado de datos es el corazón del análisis de datos. Un modelo toma los datos organizados como entrada y da la salida preferida. Este paso consiste en seleccionar el tipo de modelo adecuado, ya sea un problema de clasificación, un problema de regresión o un problema de agrupamiento. Después de decidir sobre la familia de modelos, entre la cantidad de algoritmos dentro de esa familia, debemos seleccionar cuidadosamente los algoritmos para ponerlos en práctica y hacerlos cumplir. Necesitamos ajustar los hiperparámetros de cada modelo para obtener el rendimiento deseado. También debemos asegurarnos de que existe la estabilidad adecuada entre el rendimiento general y la generalización. Ya no deseamos que el modelo estudie los datos y opere mal con nuevos datos.
6. Evaluación del modelo: aquí se evalúa el modelo para verificar si está preparado para su implementación. El modelo se examina con datos no vistos, se evalúa con un conjunto cuidadosamente pensado de métricas de evaluación. También debemos asegurarnos de que el modelo se ajuste a la realidad. Si no obtenemos un resultado final de calidad en la evaluación, tenemos que reiterar el procedimiento de modelado completo hasta que se logre la etapa preferida de métricas. Cualquier solución de ciencia de datos, un modelo de aprendizaje automático, simplemente como un ser humano, debe evolucionar, debe ser capaz de mejorarse con nuevos datos, adaptarse a una nueva métrica de evaluación. Podemos construir más de un modelo para un determinado fenómeno, sin embargo, muchos de ellos también pueden ser imperfectos. La evaluación del modelo nos ayuda a seleccionar y construir un modelo ideal.
7. Despliegue del modelo: el modelo después de una evaluación rigurosa se despliega finalmente en la estructura y el canal preferidos. Este es el último paso en el ciclo de vida de la ciencia de datos. Cada paso en el ciclo de vida de la ciencia de datos definido anteriormente debe trabajarse con cuidado. Si algún paso se realiza incorrectamente y, por lo tanto, tiene un efecto en el paso siguiente y todo el esfuerzo se desperdicia. Por ejemplo, si los datos ya no se acumulan correctamente, perderá registros y ya no podrá construir un modelo ideal. Si la información no se limpia correctamente, el modelo ya no funcionará. Si el modelo no se evalúa correctamente, fallará en el mundo real. Desde la percepción del negocio hasta la implementación del modelo, cada paso debe recibir la atención, el tiempo y el esfuerzo adecuados.
Publicación traducida automáticamente
Artículo escrito por dikshamulchandani1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA