Según Harvard Business Review, el científico de datos es “el trabajo más sexy del siglo XXI” . ¿No es esto suficiente para saber más sobre ciencia de datos?
Introducción
En el mundo del espacio de datos, la era de Big Data surgió cuando las organizaciones manejan petabytes y exabytes de datos. Se volvió muy difícil para las industrias el almacenamiento de datos hasta 2010. Ahora, cuando los marcos populares como Hadoop y otros resolvieron el problema del almacenamiento, la atención se centra en el procesamiento de los datos. Y aquí la Ciencia de Datos juega un papel muy importante . Hoy en día, el crecimiento de la ciencia de datos se ha incrementado de varias maneras, por lo que debería estar preparado para el futuro aprendiendo qué es la ciencia de datos y cómo podemos agregarle valor.
¿Qué es la ciencia de datos?
Así que ahora surge la primera pregunta: “ ¿Qué es la ciencia de datos? “La ciencia de datos significa diferentes cosas para diferentes personas, pero en esencia, la ciencia de datos utiliza datos para responder preguntas. ¡Esta definición es una definición moderadamente amplia, y eso se debe a que hay que decir que la ciencia de datos es un campo moderadamente amplio!
La ciencia de datos es la ciencia de analizar datos sin procesar utilizando estadísticas y técnicas de aprendizaje automático con el propósito de sacar conclusiones sobre esa información.
Así que brevemente se puede decir que Data Science implica:
- Estadística, informática, matemáticas
- Limpieza y formateo de datos
- Visualización de datos
Pilares clave de la ciencia de datos
Por lo general, los científicos de datos provienen de diversos antecedentes educativos y de experiencia laboral, la mayoría debe ser competente o, en un caso ideal, ser maestro en cuatro áreas clave.
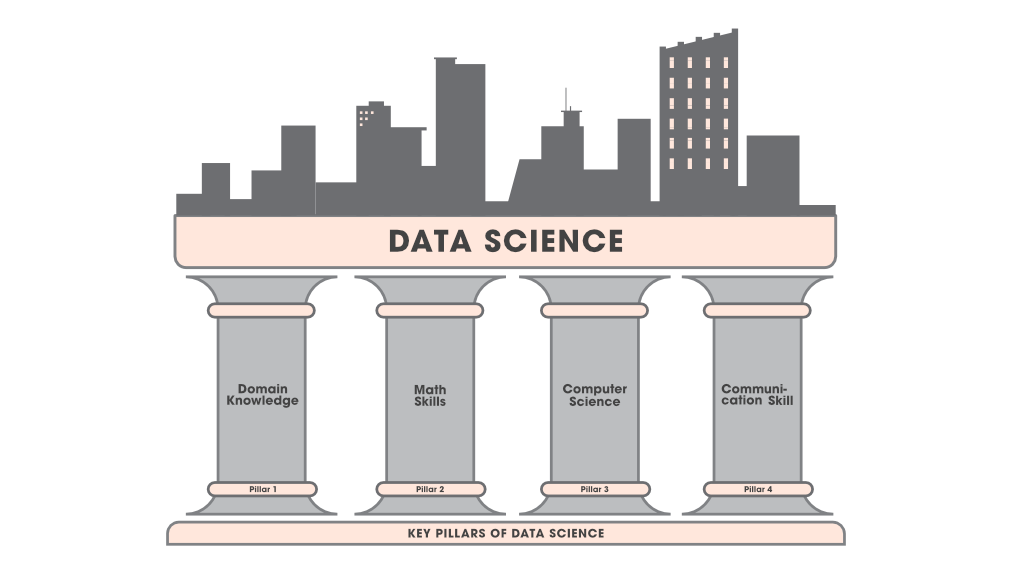
Pilar de la ciencia de datos
- Conocimiento del dominio:
- La mayoría de la gente piensa que el conocimiento del dominio no es importante en la ciencia de datos, pero es esencial. El principal objetivo de la ciencia de datos es extraer información útil de esos datos para que pueda ser rentable para el negocio de la empresa. Si no está al tanto del lado comercial de la empresa, de cómo funciona el modelo comercial de la empresa y de cómo no puede construirlo mejor, no es de utilidad para esta empresa.
- Debe saber cómo hacer las preguntas correctas a las personas adecuadas para que pueda percibir la información adecuada que necesita para obtener la información que necesita. Existen algunas herramientas de visualización que se utilizan en el ámbito comercial, como Tableau , que lo ayudan a mostrar sus valiosos resultados o conocimientos en un formato no técnico adecuado, como gráficos o gráficos circulares, que la gente de negocios puede entender.
- Habilidades matemáticas:
- Álgebra lineal, cálculo multivariable y técnica de optimización : estas tres cosas son muy importantes ya que nos ayudan a comprender varios algoritmos de aprendizaje automático que juegan un papel importante en la ciencia de datos.
- Estadística y probabilidad : la comprensión de las estadísticas es muy importante ya que es parte del análisis de datos. La probabilidad también es importante para las estadísticas y se considera un requisito previo para dominar el aprendizaje automático.
- Ciencias de la Computación:
- Conocimientos de programación : es necesario tener una buena comprensión de los conceptos de programación, como las estructuras de datos y los algoritmos . Los lenguajes de programación utilizados son Python, R, Java, Scala . C++ también es útil en algunos lugares donde el rendimiento es muy importante.
- Bases de datos relacionales : uno necesita conocer bases de datos como SQL u Oracle para poder recuperar los datos necesarios de ellos cuando sea necesario.
- Bases de datos no relacionales : hay muchos tipos de bases de datos no relacionales, pero los tipos más utilizados son Cassandra, HBase, MongoDB, CouchDB, Redis, Dynamo.
- Aprendizaje automático : es una de las partes más vitales de la ciencia de datos y el tema de investigación más candente entre los investigadores, por lo que cada año se realizan nuevos avances en esto. Uno al menos necesita comprender los algoritmos básicos de aprendizaje supervisado y no supervisado . Hay varias bibliotecas disponibles en Python y R para implementar estos algoritmos.
- Computación distribuida : también es una de las habilidades más importantes para manejar una gran cantidad de datos porque uno no puede procesar tantos datos en un solo sistema. Las herramientas que más se utilizan son Apache Hadoop y Spark . Las dos partes principales de estos peajes son HDFS (Sistema de archivos distribuidos de Hadoop) que se utiliza para recopilar datos en un sistema de archivos distribuido. Otra parte es map-reduce , mediante la cual manipulamos los datos. Uno puede escribir map-reduce en programas en Java o Python . Hay varias otras herramientas como PIG, HIVE , etc.
- Habilidad de comunicación:
- Incluye comunicación escrita y verbal. Lo que sucede en un proyecto de ciencia de datos es que después de sacar conclusiones del análisis, el proyecto debe comunicarse a otros . A veces, este puede ser un informe que envía a su jefe o equipo en el trabajo. Otras veces puede ser una entrada de blog. A menudo puede ser una presentación a un grupo de colegas. Independientemente, un proyecto de ciencia de datos siempre implica alguna forma de comunicación de los hallazgos de los proyectos. Entonces, es necesario tener habilidades de comunicación para convertirse en un científico de datos.
¿Quién es un científico de datos?
Entonces, hemos discutido qué es la ciencia de datos y los pilares clave de la ciencia de datos, pero algo más de lo que debemos hablar es quién es exactamente un científico de datos. Un informe especial de The Economist dice que un científico de datos se define como alguien:
“quien integra las habilidades del programador de software, estadístico y artista del slash del narrador para extraer las pepitas de oro escondidas bajo montañas de datos”
Pero ahora surge la pregunta, ¿qué habilidades tiene un científico de datos? Y para responder a esto, analicemos el popular diagrama de Venn Diagrama de Venn de ciencia de datos de Drew Conway en el que la ciencia de datos es la intersección de tres sectores: experiencia sustantiva, habilidades de piratería y conocimiento de matemáticas y estadísticas .
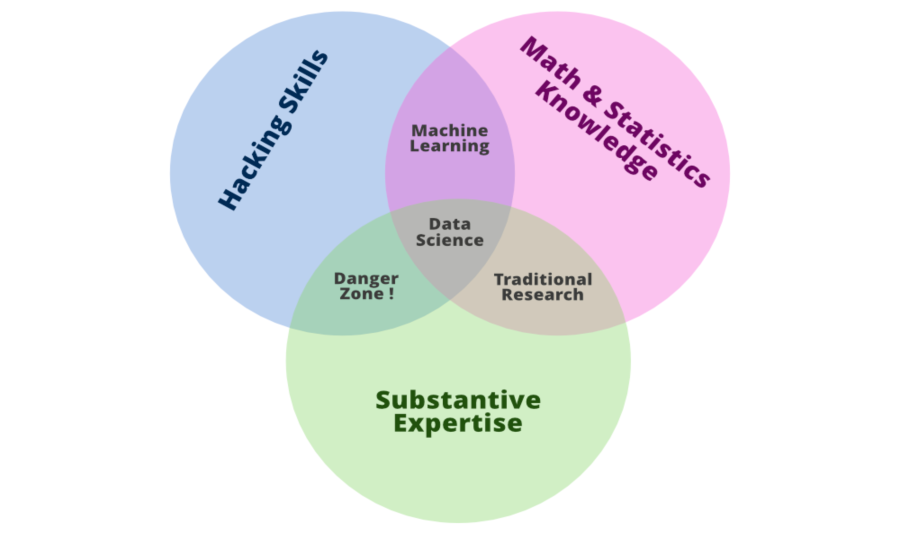
Expliquemos un poco lo que queremos decir con este diagrama de Venn, sabemos que usamos la ciencia de datos para responder preguntas, por lo que primero, debemos tener suficiente experiencia en el área sobre la que deseamos preguntar para poder expresar las preguntas y entender. qué tipo de datos son relevantes para responder a esa pregunta. Una vez que tenemos nuestra pregunta y los datos relevantes, entendemos que, a partir de los tipos de datos con los que opera la ciencia de datos, muchas veces es necesario someterlos a una limpieza y formateo significativos, y esto a menudo requiere habilidades de programación informática. Finalmente, una vez que tenemos los datos, necesitamos analizarlos, y esto a menudo requiere conocimientos de matemáticas y estadísticas.
Funciones y responsabilidades de un científico de datos:
- Administración: el científico de datos desempeña un papel administrativo insignificante en el que apoya la construcción de la base de habilidades técnicas y futuristas dentro del campo de datos y análisis para ayudar a varios proyectos de análisis de datos planificados y continuos.
- Analítica: El científico de datos representa un rol científico en el que planifica, implementa y evalúa modelos y estrategias estadísticas de alto nivel para su aplicación en los problemas más complejos del negocio. El científico de datos desarrolla modelos econométricos y estadísticos para diversos problemas, incluidas proyecciones, clasificación, agrupación, análisis de patrones, muestreo, simulaciones, etc.
- Estrategia/diseño: el científico de datos desempeña un papel vital en el avance de estrategias innovadoras para comprender las tendencias y la gestión de los consumidores de la empresa, así como las formas de resolver problemas comerciales difíciles, por ejemplo, la optimización del cumplimiento del producto y la ganancia total.
- Colaboración: el rol del científico de datos no es un rol solitario y, en este puesto, colabora con científicos de datos superiores para comunicar obstáculos y hallazgos a las partes interesadas relevantes en un esfuerzo por mejorar el desempeño comercial y la toma de decisiones.
- Conocimiento: el científico de datos también asume el liderazgo para explorar diferentes tecnologías y herramientas con la visión de crear conocimientos innovadores basados en datos para el negocio al ritmo más ágil posible. En esta situación, el científico de datos también usa la iniciativa para evaluar y utilizar métodos de ciencia de datos nuevos y mejorados para el negocio, que entrega a la alta gerencia para su aprobación.
- Otros deberes: un científico de datos también realiza tareas relacionadas y tareas asignadas por el científico de datos sénior, el jefe de ciencia de datos, el director de datos o el empleador.
Diferencia entre científico de datos, analista de datos e ingeniero de datos:
Científico de datos, ingeniero de datos y analista de datos son las tres carreras más comunes en la ciencia de datos . Entonces, comprendamos quién es un científico de datos comparándolo con trabajos similares.
|
Científico de datos |
Analista de datos |
Ingeniero de datos |
|---|---|---|
| La atención se centrará en la visualización futurista de datos. | El enfoque principal de un analista de datos está en la optimización de escenarios, por ejemplo, cómo un empleado puede mejorar el crecimiento del producto de la empresa. | Los ingenieros de datos se centran en las técnicas de optimización y la construcción de datos de forma convencional. El propósito de un ingeniero de datos es avanzar continuamente en el consumo de datos. |
| Los científicos de datos presentan aprendizaje de datos tanto supervisado como no supervisado, por ejemplo, regresión y clasificación de datos, redes neuronales, etc. | Formación de datos y limpieza de datos sin procesar, interpretación y visualización de datos para realizar el análisis y realizar el resumen técnico de datos. | Con frecuencia, los ingenieros de datos operan en el back-end. Se utilizaron algoritmos de aprendizaje automático optimizados para conservar los datos y hacer que los datos se prepararan con mayor precisión. |
| Las habilidades requeridas para Data Scientist son Python, R, SQL, Pig, SAS, Apache Hadoop, Java, Perl, Spark. | Las habilidades requeridas para Data Analyst son Python, R, SQL, SAS. | Las habilidades requeridas para el ingeniero de datos son MapReduce, Hive, Pig Hadoop, técnicas. |
Algunos científicos de datos inspiradores
La variedad de áreas en las que se utiliza la ciencia de datos se materializa al observar ejemplos de científicos de datos.
- Hilary Mason : es cofundadora de FastForward labs, una empresa de aprendizaje automático recientemente propiedad de Cloudera , una empresa de ciencia de datos. Es científica de datos en Accel. En términos generales, trabaja con datos para resolver preguntas sobre la minería en la web y también aprende el método de cómo las personas se comunican entre sí a través de las redes sociales.
- Nate Silver: es uno de los científicos de datos o estadísticos más destacados del mundo en la actualidad. Es el fundador de FiveThirtyEight. FiveThirtyEight es un sitio web que aplica análisis estadístico para contar historias convincentes sobre elecciones, política, deportes, ciencia y estilo de vida. Utiliza grandes cantidades de datos públicos para predecir una diversidad de temas; lo más destacado es que predice quién ganará las elecciones en los EE. UU. y tiene un historial extraordinario de precisión al hacerlo.
- Daryl Morey: Es el gerente general de un equipo de baloncesto de Estados Unidos, los Houston Rockets. Se le otorgó el puesto de gerente general en base a su licenciatura en ciencias de la computación y su maestría en administración de empresas del MIT.
¿Por qué necesitamos la ciencia de datos?
Una de las razones de la aceleración de la ciencia de datos en los últimos años es el enorme volumen de datos actualmente disponibles y que se están generando. No solo se recopilan enormes cantidades de datos sobre muchos aspectos del mundo y de nuestras vidas, sino que al mismo tiempo tenemos el auge de la informática económica. Esto ha formado la tormenta perfecta en la que tenemos datos valiosos y las herramientas para analizarlos. ¡Avanzando en las capacidades de la memoria de la computadora, más software mejorado, procesadores más competentes y ahora, más científicos de datos con las habilidades para poner esto en uso y resolver preguntas usando los datos!
¿Qué es el gran volumen de datos?
Con frecuencia escuchamos el término Big Data . Por lo tanto, merece una introducción aquí, ya que ha sido una parte integral del auge de la ciencia de datos.
¿Qué significa Big Data?
Big Data literalmente significa grandes cantidades de datos. Big data es el pilar detrás de la idea de que uno puede hacer inferencias útiles con una gran cantidad de datos que antes no era posible con conjuntos de datos más pequeños. Por lo tanto, los conjuntos de datos extremadamente grandes pueden analizarse computacionalmente para revelar patrones, tendencias y asociaciones que no son transparentes o fáciles de identificar.
¿Por qué todo el mundo está interesado en Big Data?
¡Los grandes datos están en todas partes!
Cada vez que entras a la web y haces algo se recopilan datos, cada vez que compras algo en uno de los e-commerce se recopilan tus datos. Cada vez que va a la tienda, los datos se recopilan en el punto de venta, cuando realiza transacciones bancarias, esos datos están allí, cuando va a las redes sociales como Facebook, Twitter, esos datos se recopilan. Ahora, estos son más datos sociales, pero lo mismo está comenzando a suceder con las plantas de ingeniería reales. Los datos en tiempo real se recopilan de plantas de todo el mundo. No solo esto, si estás haciendo simulaciones mucho más sofisticadas, simulaciones moleculares , que generan toneladas de datos que también se recopilan y almacenan.
¿Cuántos datos son Big Data?
- Google procesa 20 petabytes (PB) por día (2008)
- Facebook tiene 2,5 PB de datos de usuario + 15 TB por día (2009)
- eBay tiene 6,5 PB de datos de usuario + 50 TB por día (2009)
- El Gran Colisionador de Hadrones (LHC) del CERN genera 15 PB al año
¿Por qué hacer ciencia de datos?
Hablando de demanda, existe una inmensa necesidad de personas con habilidades en ciencia de datos. Según el Informe de empleos emergentes de EE. UU. de LinkedIn, el científico de datos de 2020 ocupó el tercer lugar con un crecimiento anual del 37 %. Este campo ha encabezado la lista de Empleos emergentes durante tres años consecutivos.
Además, según Glassdoor , en el que enumeraron los 50 trabajos más satisfactorios en Estados Unidos, el científico de datos ocupa el puesto número 3 en los EE. UU. en 2020, según la satisfacción laboral (4.0/5), el salario ($107,801) y la demanda.
Por lo tanto, este es un buen momento para ingresar a la ciencia de datos: no solo tenemos más datos y más herramientas para recopilarlos, almacenarlos e interpretarlos, sino que la necesidad de científicos de datos crece con frecuencia y se percibe como esencial en muchos. diversos sectores, no sólo empresarial y académico.
¡Ciencia de datos en acción!
Un ejemplo famoso de ciencia de datos en acción es de 2009, en el que algunos investigadores de Google analizaron 50 millones de palabras comúnmente buscadas durante un período de cinco años y las compararon con los datos de los CDC (Centros para el Control y la Prevención de Enfermedades) sobre brotes de gripe. Su objetivo era comprender si algunas búsquedas particulares armonizaban con los brotes de gripe.
Una de las ventajas de la ciencia de datos y trabajar con big data es que puede distinguir correlaciones; en este caso, distinguieron 45 palabras que tenían una fuerte correlación con los datos de brotes de gripe de los CDC. ¡Y utilizando estos datos, pudieron predecir los brotes de gripe basándose solo en las búsquedas habituales de Google! Sin esta cantidad masiva de datos, estas 45 palabras no podrían haberse predicho de antemano.
¿Qué son los datos?
Como hemos usado algún tiempo discutiendo qué es la ciencia de datos, es necesario dedicar algún tiempo a ver qué son exactamente los datos. Wikipedia define los datos como,
Un conjunto de valores de variables cualitativas o cuantitativas.
Esta definición se centra más en lo que implican los datos. Y aunque es una definición razonablemente corta. Tomemos un segundo para analizar esto y enfocarnos en cada componente individualmente.
- Un conjunto de valores : el primer término en el que concentrarse es «un conjunto de valores» : para tener datos, necesitamos incluir un conjunto de valores. En estadística, este conjunto de valores se conoce como población . Por ejemplo, ese conjunto de valores necesarios para responder a su pregunta podría ser todos los sitios web o aplicaciones, o podría ser el conjunto de todas las personas que obtienen un medicamento en particular o el conjunto de personas que visitan un sitio web en particular. Pero, en general, es un conjunto de cosas sobre las que vas a hacer mediciones.
- Variables : lo siguiente en lo que hay que centrarse son las «variables» : las variables son medidas o características de un artículo. Por ejemplo, podría medir el peso de una persona o estimar la cantidad de tiempo que una persona visita un sitio web o una aplicación. O puede ser otra característica cualitativa que está tratando de medir, como en qué hace clic una persona en un sitio web, o si cree que la persona que visita es hombre o mujer.
- Variables cualitativas y cuantitativas : Por último, tenemos tanto “ variables cualitativas como cuantitativas ”. Las variables cualitativas son información sobre cualidades. Son cosas como el país de origen, el género, la religión, etc. Por lo general, se representan con palabras, no con números, y no están indexadas ni ordenadas. Por otro lado, las variables cuantitativas son información sobre cantidades. Las medidas cuantitativas normalmente se representan mediante números y se estiman en una escala ordenada constante; son algo así como el peso, la altura, la edad y la presión arterial.
El proceso de la ciencia de datos
Las partes involucradas en un proyecto completo de ciencia de datos son,

- Formar la pregunta : cada proyecto de ciencia de datos comienza con una pregunta que debe responderse con datos. Eso significa que ‘ formar la pregunta’ es un primer paso importante en el proceso. Al comenzar con un proyecto de ciencia de datos, es bueno tener su pregunta claramente definida. Pueden surgir más preguntas a medida que realiza el análisis, pero comprender lo que necesita responder con su análisis es un primer paso muy importante.
- Encontrar o generar los datos : el segundo paso es » encontrar o generar los datos » que utilizará para responder esa pregunta. La generación de datos se puede obtener en cualquier formato aleatorio. Por lo tanto, de acuerdo con el enfoque elegido y el resultado que se obtenga, los datos recopilados deben validarse. Por lo tanto, si es necesario, se pueden recopilar más datos o descartar los datos irrelevantes.
- Luego se analizan los datos : con la pregunta solidificada y los datos en la mano, los » datos se analizan «. Esto se puede hacer en dos partes.
- Exploración de los datos : en este paso, estudia y preprocesa los datos para el modelado. Serás capaz de realizar limpieza y visualización de datos. Esto ayudará a encontrar las diferencias y establecer una conexión entre los factores. Una vez que haya completado el paso, es hora de realizar análisis exploratorios en él.
- Modelado de los datos : en este paso, generará conjuntos de datos con fines de capacitación y prueba. Puede interpretar varios métodos de aprendizaje como la clasificación y la agrupación y, por último, completar la técnica de ajuste más excelente para construir la pantalla. En resumen, eso significa usar algunas técnicas estadísticas o de aprendizaje automático para analizar los datos y responder a su pregunta.
- Comunicado a otros : Después de sacar conclusiones de este análisis, el proyecto debe ser “ comunicado a otros” . Un componente importante de cualquier proyecto de ciencia de datos es describir adecuadamente el resultado del proyecto. A veces, este es un informe que envía a su jefe o puede ser una publicación de blog.
Algunos proyectos geniales de ciencia de datos:
Los siguientes son algunos proyectos geniales de ciencia de datos. En cada proyecto, el autor tenía una pregunta y quería resolverla. Y utilizaron datos para resolver esa pregunta. Analizaron y visualizaron los datos. Luego, escribieron publicaciones de blog para comunicar sus resultados. ¡Eche un vistazo para obtener más información sobre los temas y para ver cómo otros trabajan en el proyecto de ciencia de datos y entregan sus resultados!
- El análisis de texto de los tweets de Trump confirma que escribe solo la mitad de Android (más enojado) , por David Robinson
- Hilary: el nombre de bebé más envenenado en la historia de Estados Unidos por Hilary Parker
- Dónde vivir en los Estados Unidos , por Maelle Salmon
- Clínicas de salud sexual en Toronto , por Sharla Gelfand
Algunos datos estadísticos importantes
Encuesta para desarrolladores de Stackoverflow , 2020: funciones de los desarrolladores
Según la encuesta de desarrolladores de StackOverflow, 2020: funciones de desarrollador , alrededor del 8,1 % de los encuestados se identifican como científicos de datos o especialistas en aprendizaje automático.
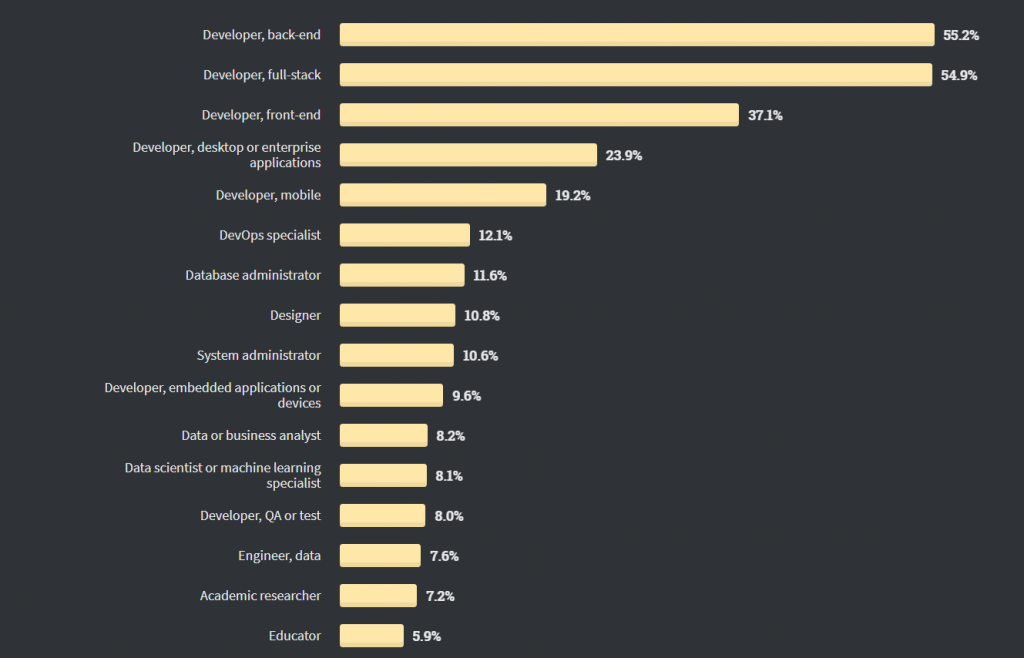
Encuesta para desarrolladores de Stackoverflow, 2020: funciones de los desarrolladores
Las habilidades de ciencia de datos más demandadas de 2019

Cómo volverse más comercializable como científico de datos
Publicación traducida automáticamente
Artículo escrito por AmiyaRanjanRout y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA