La regresión logística y la clasificación del árbol de decisiones son dos de los algoritmos de clasificación más populares y básicos que se utilizan en la actualidad. Ninguno de los algoritmos es mejor que el otro y el rendimiento superior de uno a menudo se atribuye a la naturaleza de los datos con los que se trabaja.
Podemos comparar los dos algoritmos en diferentes categorías:
| Criterios | Regresión logística | Clasificación del árbol de decisión |
|---|---|---|
| Interpretabilidad | Menos interpretable | Más interpretable |
| Límites de decisión | Límite de decisión lineal y único | Divide el espacio en espacios más pequeños |
| Facilidad de toma de decisiones | Se debe establecer un umbral de decisión. | Maneja automáticamente la toma de decisiones |
| sobreajuste | No es propenso al sobreajuste | Propenso al sobreajuste |
| Robustez al ruido | Robusto al ruido | Mayormente afectado por el ruido |
| Escalabilidad | Requiere un conjunto de entrenamiento lo suficientemente grande | Se puede entrenar en un pequeño conjunto de entrenamiento. |
Como un experimento simple, ejecutamos los dos modelos en el mismo conjunto de datos y comparamos sus rendimientos.
Paso 1: Importación de las bibliotecas requeridas
Python3
import numpy as np import pandas as pd from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifier
Paso 2: lectura y limpieza del conjunto de datos
Python3
cd C:\Users\Dev\Desktop\Kaggle\Sinking Titanic
# Changing the working location to the location of the file
df = pd.read_csv('_train.csv')
y = df['Survived']
X = df.drop('Survived', axis = 1)
X = X.drop(['Name', 'Ticket', 'Cabin', 'Embarked'], axis = 1)
X = X.replace(['male', 'female'], [2, 3])
# Hot-encoding the categorical variables
X.fillna(method ='ffill', inplace = True)
# Handling the missing values
Paso 3: Entrenamiento y evaluación del modelo de Regresión Logística
Python3
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size = 0.3, random_state = 0) lr = LogisticRegression() lr.fit(X_train, y_train) print(lr.score(X_test, y_test))
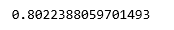
Paso 4: Entrenamiento y evaluación del modelo Clasificador de Árbol de Decisión
Python3
criteria = ['gini', 'entropy']
scores = {}
for c in criteria:
dt = DecisionTreeClassifier(criterion = c)
dt.fit(X_train, y_train)
test_score = dt.score(X_test, y_test)
scores = test_score
print(scores)
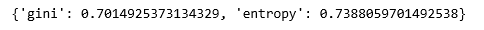
Al comparar las puntuaciones, podemos ver que el modelo de regresión logística se desempeñó mejor en el conjunto de datos actual, pero es posible que este no sea siempre el caso.
Publicación traducida automáticamente
Artículo escrito por AlindGupta y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA