La tasa de aprendizaje es un hiperparámetro importante en Gradient Descent. Su valor determina qué tan rápido convergería la red neuronal a los mínimos. Por lo general, elegimos una tasa de aprendizaje y, según los resultados, cambiamos su valor para obtener el valor óptimo para LR. Si la tasa de aprendizaje es demasiado baja para la red neuronal, el proceso de convergencia sería muy lento y si es demasiado alta, la convergencia sería rápida, pero existe la posibilidad de que la pérdida se exceda. Por lo tanto, generalmente ajustamos nuestros parámetros para encontrar el mejor valor para la tasa de aprendizaje. Pero, ¿hay alguna manera de que podamos mejorar este proceso?
¿Por qué ajustar la tasa de aprendizaje?
En lugar de tomar una tasa de aprendizaje constante, podemos comenzar con un valor más alto de LR y luego seguir disminuyendo su valor periódicamente después de ciertas iteraciones. De esta forma, inicialmente podemos tener una convergencia más rápida mientras reducimos las posibilidades de sobrepasar la pérdida. Para implementar esto, podemos usar varios programadores en la biblioteca optim en PyTorch. El formato de un ciclo de entrenamiento es el siguiente:-
epochs = 10
scheduler = <Any scheduler>
for epoch in range(epochs):
# Training Steps
# Validation Steps
scheduler.step()
Programadores de uso común en torch.optim.lr_scheduler
PyTorch proporciona varios métodos para ajustar la tasa de aprendizaje en función del número de épocas. Echemos un vistazo a algunos de ellos: –
- StepLR: multiplica la tasa de aprendizaje con gamma cada época de tamaño de paso . Por ejemplo, si lr = 0.1, gamma = 0.1 y step_size = 10, luego de 10 épocas lr cambia a lr*step_size en este caso 0.01 y luego de otras 10 épocas se convierte en 0.001.
# Code format:- optimizer = torch.optim.SGD(model.parameters(), lr=0.1) scheduler = StepLR(optimizer, step_size=10, gamma=0.1) # Procedure:- lr = 0.1, gamma = 0.1 and step_size = 10 lr = 0.1 for epoch < 10 lr = 0.01 for epoch >= 10 and epoch < 20 lr = 0.001 for epoch >= 20 and epoch < 30 ... and so on
- MultiStepLR: esta es una versión más personalizada de StepLR en la que el lr se cambia después de que alcanza una de sus épocas. Aquí proporcionamos hitos que son épocas en las que queremos actualizar nuestra tasa de aprendizaje.
# Code format:- optimizer = torch.optim.SGD(model.parameters(), lr=0.1) scheduler = MultiStepLR(optimizer, milestones=[10,30], gamma=0.1) # Procedure:- lr = 0.1, gamma = 0.1 and milestones=[10,30] lr = 0.1 for epoch < 10 lr = 0.01 for epoch >= 10 and epoch < 30 lr = 0.001 for epoch >= 30
- ExponentialLR: esta es una versión agresiva de StepLR en LR que se cambia después de cada época. Puede pensar en ello como StepLR con step_size = 1.
# Code format:- optimizer = torch.optim.SGD(model.parameters(), lr=0.1) scheduler = ExponentialLR(optimizer, gamma=0.1) # Procedure:- lr = 0.1, gamma = 0.1 lr = 0.1 for epoch = 1 lr = 0.01 for epoch = 2 lr = 0.001 for epoch = 3 ... and so on
- ReduceLROnPlateau: reduce la tasa de aprendizaje cuando una métrica deja de mejorar. Los modelos a menudo se benefician al reducir la tasa de aprendizaje en un factor de 2 a 10 una vez que el aprendizaje se estanca. Este planificador lee una cantidad de métricas y, si no se observa ninguna mejora durante un número de épocas de paciencia , la tasa de aprendizaje se reduce.
optimizer = torch.optim.SGD(model.parameters(), lr=0.1) scheduler = ReduceLROnPlateau(optimizer, 'min', patience = 5) # In min mode, lr will be reduced when the metric has stopped decreasing. # In max mode, lr will be reduced when the metric has stopped increasing.
Entrenamiento de redes neuronales usando programadores
Para este tutorial, usaremos el conjunto de datos MNIST, por lo que comenzaremos cargando nuestros datos y luego definiendo el modelo. Se recomienda que sepa cómo crear y entrenar una red neuronal en PyTorch. Comencemos cargando nuestros datos.
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
transform = transforms.Compose([
transforms.ToTensor()
])
train = datasets.MNIST('',train = True, download = True, transform=transform)
valid = datasets.MNIST('',train = False, download = True, transform=transform)
trainloader = DataLoader(train, batch_size= 32, shuffle=True)
validloader = DataLoader(test, batch_size= 32, shuffle=True)
Ahora que tenemos nuestro cargador de datos listo, podemos proceder a crear nuestro modelo. El modelo PyTorch sigue el siguiente formato:-
from torch import nn
class model(nn.Module):
def __init__(self):
# Define Model Here
def forward(self, x):
# Define Forward Pass Here
Con eso claro, definamos nuestro modelo: –
import torch
from torch import nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.fc1 = nn.Linear(28*28,256)
self.fc2 = nn.Linear(256,128)
self.out = nn.Linear(128,10)
self.lr = 0.01
self.loss = nn.CrossEntropyLoss()
def forward(self,x):
batch_size, _, _, _ = x.size()
x = x.view(batch_size,-1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.out(x)
model = Net()
# Send the model to GPU if available
if torch.cuda.is_available():
model = model.cuda()
Ahora que tenemos nuestro modelo, podemos especificar nuestro optimizador, la función de pérdida y nuestro lr_scheduler . Usaremos el optimizador SGD, CrossEntropyLoss para la función de pérdida y ReduceLROnPlateau para el programador lr.
from torch.optim import SGD from torch.optim.lr_scheduler import ReduceLROnPlateau optimizer = SGD(model.parameters(), lr = 0.1) loss = nn.CrossEntropyLoss() scheduler = ReduceLROnPlateau(optimizer, 'min', patience = 5)
Definamos el ciclo de entrenamiento. El ciclo de entrenamiento es más o menos el mismo que antes, excepto que esta vez llamaremos a nuestro método de pasos del planificador al final del ciclo.
from tqdm.notebook import trange
epoch = 25
for e in trange(epoch):
train_loss, valid_loss = 0.0, 0.0
# Set model to training mode
model.train()
for data, label in trainloader:
if torch.cuda.is_available():
data, label = data.cuda(), label.cuda()
optimizer.zero_grad()
target = model(data)
train_step_loss = loss(target, label)
train_step_loss.backward()
optimizer.step()
train_loss += train_step_loss.item() * data.size(0)
# Set model to Evaluation mode
model.eval()
for data, label in validloader:
if torch.cuda.is_available():
data, label = data.cuda(), label.cuda()
target = model(data)
valid_step_loss = loss(target, label)
valid_loss += valid_step_loss.item() * data.size(0)
curr_lr = optimizer.param_groups[0]['lr']
print(f'Epoch {e}\t \
Training Loss: {train_loss/len(trainloader)}\t \
Validation Loss:{valid_loss/len(validloader)}\t \
LR:{curr_lr}')
scheduler.step(valid_loss/len(validloader))
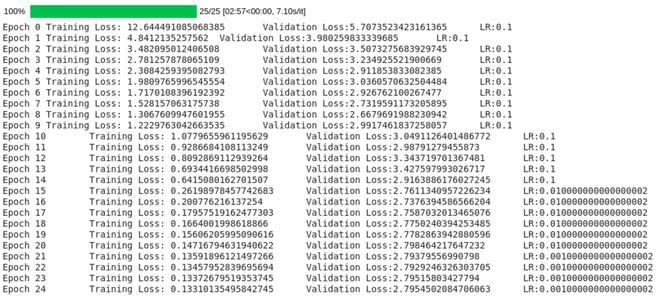
Como puede ver, el programador siguió ajustando lr cuando la pérdida de validación dejó de disminuir.
Código:
import torch
from torch import nn
import torch.nn.functional as F
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
from torch.optim import SGD
from torch.optim.lr_scheduler import ReduceLROnPlateau
from tqdm.notebook import trange
# LOADING DATA
transform = transforms.Compose([
transforms.ToTensor()
])
train = datasets.MNIST('',train = True, download = True, transform=transform)
valid = datasets.MNIST('',train = False, download = True, transform=transform)
trainloader = DataLoader(train, batch_size= 32, shuffle=True)
validloader = DataLoader(test, batch_size= 32, shuffle=True)
# CREATING OUR MODEL
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.fc1 = nn.Linear(28*28,64)
self.fc2 = nn.Linear(64,32)
self.out = nn.Linear(32,10)
self.lr = 0.01
self.loss = nn.CrossEntropyLoss()
def forward(self,x):
batch_size, _, _, _ = x.size()
x = x.view(batch_size,-1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.out(x)
model = Net()
# Send the model to GPU if available
if torch.cuda.is_available():
model = model.cuda()
# SETTING OPTIMIZER, LOSS AND SCHEDULER
optimizer = SGD(model.parameters(), lr = 0.1)
loss = nn.CrossEntropyLoss()
scheduler = ReduceLROnPlateau(optimizer, 'min', patience = 5)
# TRAINING THE NEURAL NETWORK
epoch = 25
for e in trange(epoch):
train_loss, valid_loss = 0.0, 0.0
# Set model to training mode
model.train()
for data, label in trainloader:
if torch.cuda.is_available():
data, label = data.cuda(), label.cuda()
optimizer.zero_grad()
target = model(data)
train_step_loss = loss(target, label)
train_step_loss.backward()
optimizer.step()
train_loss += train_step_loss.item() * data.size(0)
# Set model to Evaluation mode
model.eval()
for data, label in validloader:
if torch.cuda.is_available():
data, label = data.cuda(), label.cuda()
target = model(data)
valid_step_loss = loss(target, label)
valid_loss += valid_step_loss.item() * data.size(0)
curr_lr = optimizer.param_groups[0]['lr']
print(f'Epoch {e}\t \
Training Loss: {train_loss/len(trainloader)}\t \
Validation Loss:{valid_loss/len(validloader)}\t \
LR:{curr_lr}')
scheduler.step(valid_loss/len(validloader))
Publicación traducida automáticamente
Artículo escrito por herumbshandilya y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA