DeepFace es el sistema de reconocimiento facial utilizado por Facebook para etiquetar imágenes. Fue propuesto por investigadores de Facebook AI Research (FAIR) en la Conferencia de reconocimiento de patrones y visión por computadora (CVPR) de IEEE de 2014 .
En el reconocimiento facial moderno hay 4 pasos:
- Detectar
- Alinear
- Representar
- Clasificar
Este enfoque se centra en la alineación y representación de imágenes faciales. Discutiremos estas dos partes en detalle.
Alineación:
el objetivo de esta parte de alineación es generar una cara frontal a partir de la imagen de entrada que puede contener caras de diferentes poses y ángulos. El método propuesto en este artículo utilizó la frontalización 3D de rostros basada en el fiduciario (puntos característicos del rostro) para extraer el rostro frontal. Todo el proceso de alineación se realiza en los siguientes pasos:
- Dada una imagen de entrada, primero identificamos la cara usando seis puntos de referencia . Estos seis puntos fiduciales son 2 ojos, punta de la nariz y 3 puntos en los labios. Estos puntos característicos se utilizan para detectar caras en la imagen.

6 puntos fiduciales
- En este paso, generamos la imagen de la cara en 2D recortada de la imagen original usando 6 puntos fiduciales.

Rostro recortado en 2D
- En el tercer paso, aplicamos el mapa de 67 puntos de referencia con su correspondiente triangulación de Delauney en la imagen recortada alineada en 2D. Este paso se realiza para alinear las rotaciones fuera del plano. En este paso, también generamos un modelo 3D utilizando un generador de modelo genérico 2D a 3D y trazamos 67 puntos fiduciales en eso manualmente.

67 puntos fiduciales con triangulación de Delaunay

Forma 3D generada a partir de la imagen de recorte 2D alineada

Mapa de visibilidad de forma 2D en 3D (los triángulos más oscuros son menos visibles en comparación con los triángulos lifgt)
- Luego tratamos de establecer una relación entre 2D y 3D usando la relación dada

Aquí, para mejorar esta transformación, necesitamos minimizar la pérdida sobre
 la cual se puede calcular mediante la siguiente relación:
la cual se puede calcular mediante la siguiente relación: 
dónde,

y ∑
 es una array de covarianza y dimensiones de (67 x 2) x (67 x 2) , X 3d es (67 x 2) x 8 y [Tex]\overrightarrow{P} [/Tex] tiene dimensiones de (2 x 4) . Estamos utilizando la descomposición de Cholesky para convertir esa función de pérdida en mínimos cuadrados ordinarios.
es una array de covarianza y dimensiones de (67 x 2) x (67 x 2) , X 3d es (67 x 2) x 8 y [Tex]\overrightarrow{P} [/Tex] tiene dimensiones de (2 x 4) . Estamos utilizando la descomposición de Cholesky para convertir esa función de pérdida en mínimos cuadrados ordinarios.
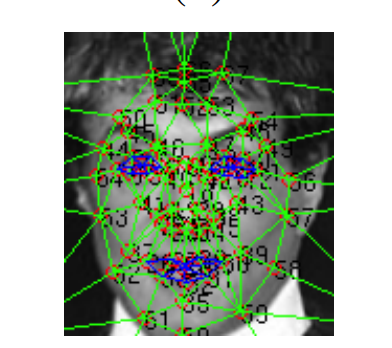
Mapeo de 67 puntos ficudiales en cara afín 2D-3D.
- La etapa final es la frontalización de la alineación . Pero antes de lograr la frontalización, agregamos el componente residual a las coordenadas xy de la deformación 3D porque reduce la corrupción en la deformación 3D. Finalmente, la frontalización se logra haciendo afines por partes en la triangulación de Delauney que generamos en 67 puntos fiduciarios.

frontalización final
Arquitectura de representación y clasificación:
DeepFace está capacitado para el reconocimiento facial de múltiples clases, es decir, para clasificar las imágenes de múltiples personas en función de sus identidades.
Toma entrada en una imagen RGB alineada en 3D de 152*152 . Luego, esta imagen se pasa a la capa Convolución con 32 filtros y un tamaño de 11*11*3 y una capa de agrupación máxima de 3*3 con una zancada de 2 . A esto le sigue otra capa de convolución de 16 filtros y tamaño 9*9*16 . El propósito de estas capas es extraer características de bajo nivel de los bordes y texturas de la imagen.
Las siguientes tres capas son capas conectadas localmente, un tipo de capa completamente conectada que tiene diferentes tipos de filtros en un mapa de características diferente. Esto ayuda a mejorar el modelo porque las diferentes regiones de la cara tienen una capacidad de discriminación diferente, por lo que es mejor tener diferentes tipos de mapas de características para distinguir estas regiones faciales.

Arquitectura completa DeepFace
Las dos últimas capas del modelo son capas totalmente conectadas. Estas capas ayudan a establecer una correlación entre dos partes distantes de la cara. Ejemplo: Posición y forma de los ojos y posición y forma de la boca. La salida de la penúltima capa completamente conectada se usa como una representación de la cara y la salida de la última capa es la clase K de la capa softmax para la clasificación de la cara.
El número total de parámetros en esta red es de aproximadamente 120 millones y la mayoría (~95 %) proviene de las capas finales totalmente conectadas. La propiedad interesante de esta red es que el mapa/vector de características generado durante el entrenamiento de este modelo es increíblemente escaso. Por ejemplo, 75%de los valores en las capas superiores es 0. Esto puede deberse a que esta red usa la función de activación ReLU en cada red de convolución que es esencialmente max(0, x) . Esta red también utiliza la Regularización de la Abandono que también contribuyó a la escasez. Sin embargo, Dropout solo se aplica a la primera capa completamente conectada.
En las etapas finales de esta red, también normalizamos la función para que esté entre 0 y 1. Esto también reduce el efecto de los cambios de iluminación. También realizamos una regularización L2 después de esta normalización.
Métrica de verificación:
necesitamos definir alguna métrica que mida si dos imágenes de entrada pertenecen a la misma clase o no. Hay dos métodos: supervisado y no supervisado, y el supervisado tiene una mayor precisión que el no supervisado. Es intuitivo porque mientras se entrena en un conjunto de datos de destino particular, uno puede mejorar la precisión ajustando el modelo de acuerdo con él. Por ejemplo, el conjunto de datos Labeled Faces in the Wild (LFW) tiene un 75 %de los rostros son masculinos, el entrenamiento en LFW puede introducir algún sesgo y agregar cierta generalización que no es adecuada al realizar pruebas en otros conjuntos de datos de reconocimiento facial. Sin embargo, el entrenamiento con un conjunto de datos pequeño puede reducir la generalización cuando se usa en otros conjuntos de datos. En estos casos, la métrica de similitud no supervisada es mejor. Este documento utiliza el producto interno de dos vectores de características generados a partir de la arquitectura de representación para la similitud no supervisada. Este documento también utiliza dos métricas de verificación supervisada. Estos son
- La distancia [Tex]\chi ^{2} [/Tex] ponderada :
La similitud ponderada se define como:
similitud ponderada se define como:
![\chi^{2}_{f_1, f_2} = \sum _{i}\omega_{i} \dfrac{\left ( f_1\left [ i \right ] - f_2\left [ i \right ]\right )^2}{f_1\left [ i \right ] + f_2\left [ i \right ]}](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-19b906b338441830d1605378840d1984_l3.png "Rendered by QuickLaTeX.com")
donde
 están el vector de representación de la cara y
están el vector de representación de la cara y  el peso que podemos aprender usando SVM lineal.
el peso que podemos aprender usando SVM lineal.
- Red siamesa:
La red siamesa es un enfoque muy común y se utiliza para predecir si dos caras pertenecen a la misma clase o no. Calcula la distancia siamesa entre dos representaciones de caras si la distancia está dentro de la tolerancia, entonces si la distancia está por debajo del nivel de tolerancia, predice que dos caras pertenecen a la misma clase, de lo contrario no. La distancia siamesa se define como![d_{\left ( f_1, f_2 \right )} = \sum_{i}\alpha_i\left | f_1\left [ i \right ] - f_2\left [ i \right ] \right |](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-a65388c8fae9065293a0931e6a92bd15_l3.png "Rendered by QuickLaTeX.com")
Entrenamiento y resultados
DeepFace está entrenado y experimentado en los siguientes tres conjuntos de datos
- Conjunto de datos SFC:
este es el conjunto de datos generado por el propio Facebook. Contiene casi 4,4 millones de imágenes de 4030 personas, cada una de las cuales tiene entre 800 y 1200 imágenes de rostros. Para fines de prueba, toman el 5% de las imágenes más recientes de cada clase. El modelo se entrena utilizando una red de avance estándar con SGD con impulso = 0,9 , tamaño de lote = 128 y la tasa de aprendizaje es la misma para toda la capa, es decir, 0,01 .
El modelo está entrenado en tres subconjuntos de conjuntos de datos de 1,500 personas (1,5 millones de imágenes) , 3000 personas (3,3 millones de imágenes) y 4000 personas (4,4 millones de imágenes). La tasa de error de clasificación en estos subconjuntos es del 7 % , 7,2 % y 8,7 % , respectivamente.
- Conjunto de datos LFW:
es uno de los conjuntos de datos más populares en el dominio del reconocimiento facial. Contiene más de 13000 imágenes web de más de 5700 celebridades. El rendimiento se mide utilizando tres métodos:- Método restringido en el que se proporciona el par de imágenes al modelo y el objetivo es identificar si la imagen es igual o no.
- Método sin restricciones en el que se puede acceder a más imágenes que un solo par para el entrenamiento.
- Método no supervisado en el que el modelo no ha sido entrenado en el conjunto de datos LFW.
Los resultados son los siguientes:

Aquí, DeepFace-ensamble representa una combinación de diferentes modelos DeepFace-single que utilizan diferentes métricas de verificación que discutimos anteriormente.
Como podemos concluir, el conjunto DeepFace alcanza una precisión máxima del 97,35 % , que está muy cerca del nivel humano del 97,53 %.
- Conjunto de datos YTF:
contiene 3425 videos de 1595 celebridades (un subconjunto de celebridades de LFW). Estos videos se dividen en 5000 pares de videos de 10 divisiones y se utilizan para evaluar el rendimiento en la verificación facial a nivel de video. Los resultados en el conjunto de datos YTF son los siguientes:

Resultados en YTF
Tenga en cuenta que, debido al desenfoque de movimiento y otros factores, la calidad de imagen de los conjuntos de datos de video es generalmente peor que la de los conjuntos de datos de imágenes. Sin embargo, el 91,4 % sigue siendo la precisión más avanzada en ese momento y reduce la tasa de error en más del 50 % .
En términos de tiempo de prueba, DeepFace tarda 0,33 segundos cuando se prueba en un procesador Intel de 2,2 GHz de un solo núcleo. Esto incluye 0,05 segundos tomados en la alineación y 0,18 segundos en la extracción de características.
Conclusión:
en el momento de su publicación, era uno de los mejores modelos de reconocimiento facial ahora, por supuesto, modelos como Google-FaceNet y otros modelos que brindan una precisión de hasta el 99,6% en el conjunto de datos LFW. El principal problema que DeepFace ha podido resolver es construir un modelo que sea invariable al efecto de luz, pose, expresión facial, etc. y es por eso que se usa en la mayoría de las tareas de reconocimiento facial de Facebook. El enfoque novedoso para utilizar la alineación 3D también contribuyó al aumento de la precisión del modelo.
Referencia: