El reconocimiento de objetos es la técnica de identificación del objeto presente en imágenes y videos. Es una de las aplicaciones más importantes del aprendizaje automático y el aprendizaje profundo. El objetivo de este campo es enseñar a las máquinas a comprender (reconocer) el contenido de una imagen tal como lo hacen los humanos.
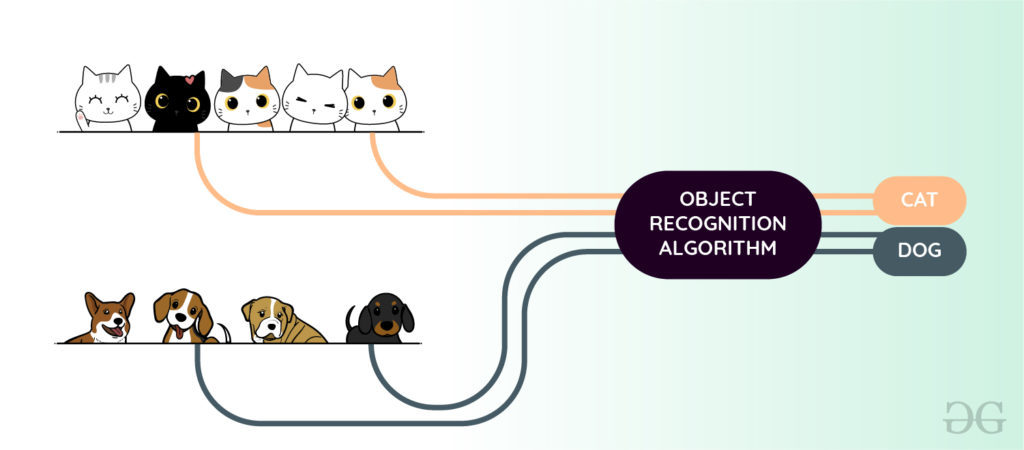
Reconocimiento de objetos
Reconocimiento de objetos mediante aprendizaje automático
- Extractor de características HOG (Histogram of oriented Gradients) y modelo SVM (Support Vector Machine) : antes de la era del aprendizaje profundo, era un método de última generación para la detección de objetos. Toma descriptores de histograma de muestras positivas (imágenes que contienen objetos) y negativas (imágenes que no contienen objetos) y entrena nuestro modelo SVM en eso.
- Modelo de bolsa de características : Al igual que la bolsa de palabras considera el documento como una colección sin orden de palabras, este enfoque también representa una imagen como una colección sin orden de características de imagen. Ejemplos de esto son SIFT, MSER, etc.
- Algoritmo Viola-Jones: este algoritmo es muy utilizado para la detección de rostros en la imagen o en tiempo real. Realiza una extracción de características similar a la de Haar de la imagen. Esto genera una gran cantidad de funciones. Estas características luego se pasan a un clasificador de refuerzo. Esto genera una cascada del clasificador potenciado para realizar la detección de imágenes. Una imagen debe pasar a cada uno de los clasificadores para generar un resultado positivo (cara encontrada). La ventaja de Viola-Jones es que tiene un tiempo de detección de 2 fps que se puede utilizar en un sistema de reconocimiento facial en tiempo real.
Reconocimiento de objetos mediante aprendizaje profundo
La red neuronal de convolución (CNN) es una de las formas más populares de realizar el reconocimiento de objetos. Es ampliamente utilizado y la mayoría de las redes neuronales de última generación utilizan este método para diversas tareas relacionadas con el reconocimiento de objetos, como la clasificación de imágenes. Esta red CNN toma una imagen como entrada y genera la probabilidad de las diferentes clases. Si el objeto presente en la imagen, su probabilidad de salida es alta, de lo contrario, la probabilidad de salida del resto de clases es insignificante o baja. La ventaja del aprendizaje profundo es que no necesitamos extraer características de los datos en comparación con el aprendizaje automático.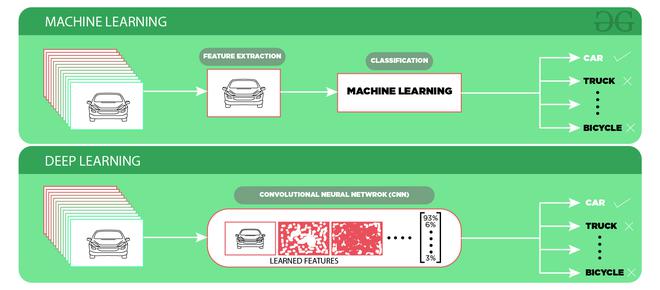
Desafíos del reconocimiento de objetos:
- Dado que tomamos la salida generada por la última capa (totalmente conectada) del modelo CNN, es una etiqueta de clase única. Por lo tanto, un enfoque simple de CNN no funcionará si hay más de una etiqueta de clase presente en la imagen.
- Si queremos localizar la presencia de un objeto en el cuadro delimitador, debemos probar un enfoque diferente que no solo genere la etiqueta de clase, sino también las ubicaciones del cuadro delimitador.
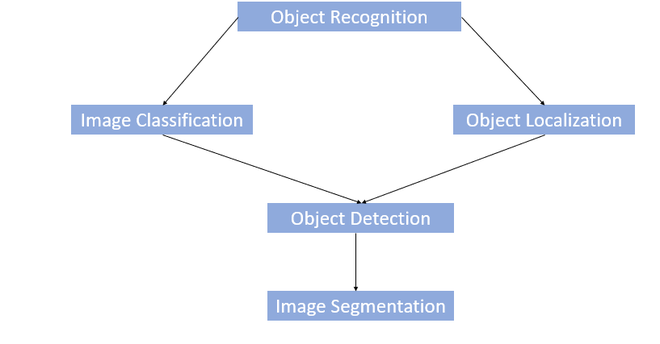
Descripción general de las tareas relacionadas con el reconocimiento de objetos
Clasificación de imágenes:
En la clasificación de imágenes, toma una imagen como entrada y genera la etiqueta de clasificación de esa imagen con alguna métrica (probabilidad, pérdida, precisión, etc.). Por ejemplo: una imagen de un gato se puede clasificar como una etiqueta de clase «gato» o una imagen de un perro se puede clasificar como una etiqueta de clase «perro» con cierta probabilidad.

Clasificación de imágenes
Desafíos de la detección de objetos:
- En la detección de objetos, los cuadros delimitadores son siempre rectangulares. Por lo tanto, no ayuda a determinar la forma de los objetos si el objeto contiene la parte de curvatura.
- La detección de objetos no puede estimar con precisión algunas medidas, como el área de un objeto, el perímetro de un objeto a partir de la imagen.
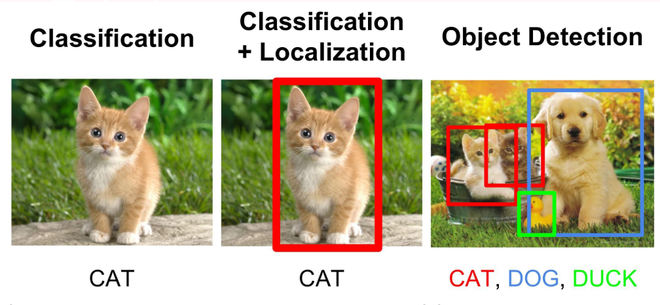
Diferencia entre clasificación. Localización y Detección
La segmentación de imágenes es una extensión adicional de la detección de objetos en la que marcamos la presencia de un objeto a través de máscaras de píxeles generadas para cada objeto en la imagen. Esta técnica es más granular que la generación de cuadros delimitadores porque puede ayudarnos a determinar la forma de cada objeto presente en la imagen porque en lugar de dibujar cuadros delimitadores, la segmentación ayuda a descubrir los píxeles que están creando ese objeto. Esta granularidad nos ayuda en varios campos, como el procesamiento de imágenes médicas, imágenes satelitales, etc. Recientemente se han propuesto muchos enfoques de segmentación de imágenes. Uno de los más populares es Mask R-CNN propuesto por K He et al . en 2017.
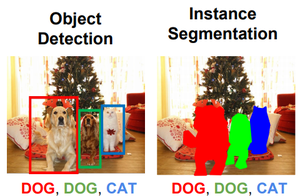
Detección de objetos frente a segmentación (Fuente: Enlace)
Hay principalmente dos tipos de segmentación:
- Segmentación de instancias: múltiples instancias de la misma clase son segmentos separados, es decir, los objetos de la misma clase se tratan como diferentes. Por lo tanto, todos los objetos se colorean con un color diferente aunque pertenezcan a la misma clase.
- Segmentación semántica: todos los objetos de la misma clase forman una sola clasificación, por lo tanto, todos los objetos de la misma clase están coloreados por el mismo color.
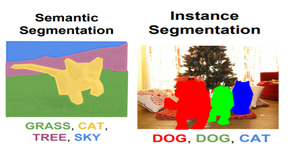
Segmentación semántica vs de instancias (Fuente: Enlace)
Las técnicas de reconocimiento de objetos discutidas anteriormente se pueden utilizar en muchos campos, tales como:
- Coches sin conductor: el reconocimiento de objetos se utiliza para detectar señales de tráfico, otros vehículos, etc.
- Procesamiento de imágenes médicas: las técnicas de reconocimiento de objetos y procesamiento de imágenes pueden ayudar a detectar enfermedades con mayor precisión. La segmentación de imágenes ayuda a detectar la forma del defecto presente en el cuerpo. Por ejemplo, la IA de Google para la detección del cáncer de mama detecta con mayor precisión que los médicos.
- Vigilancia y Seguridad: como reconocimiento facial, seguimiento de objetos, reconocimiento de actividad, etc.