StandardScaler sigue la distribución normal estándar (SND) . Por lo tanto, hace que la media sea igual a 0 y escala los datos a la varianza unitaria.
MinMaxScaler escala todas las características de datos en el rango [0, 1] o en el rango [-1, 1] si hay valores negativos en el conjunto de datos. Esta escala comprime todos los valores internos en el rango estrecho [0, 0.005] .
En presencia de valores atípicos, StandardScaler no garantiza escalas de características equilibradas, debido a la influencia de los valores atípicos al calcular la media empírica y la desviación estándar. Esto conduce a la contracción en el rango de los valores de las características.
Mediante el uso de RobustScaler(), podemos eliminar los valores atípicos y luego usar StandardScaler o MinMaxScaler para preprocesar el conjunto de datos.
Cómo funciona RobustScaler:
class
sklearn.preprocessing.RobustScaler(
with_centering=True,
with_scaling=True,
quantile_range=(25.0, 75.0),
copy=True,
)
Escala características usando estadísticas que son sólidas para valores atípicos. Este método elimina la mediana y escala los datos en el rango entre el 1er cuartil y el 3er cuartil . es decir, entre el rango del cuantil 25 y el cuantil 75 . Este rango también se llama rango intercuartílico .
Luego, la mediana y el rango intercuartílico se almacenan para que puedan usarse en datos futuros utilizando el método de transformación. Si hay valores atípicos en el conjunto de datos, la mediana y el rango intercuartílico proporcionan mejores resultados y superan la media y la varianza de la muestra.
RobustScaler utiliza el rango intercuartílico para que sea resistente a los valores atípicos. Por tanto su fórmula es la siguiente: 
Código: comparación entre StandardScaler, MinMaxScaler y RobustScaler.
Python3
# Importing libraries
import pandas as pd
import numpy as np
from sklearn import preprocessing
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns % matplotlib inline
matplotlib.style.use('fivethirtyeight')
# data
x = pd.DataFrame({
# Distribution with lower outliers
'x1': np.concatenate([np.random.normal(20, 2, 1000), np.random.normal(1, 2, 25)]),
# Distribution with higher outliers
'x2': np.concatenate([np.random.normal(30, 2, 1000), np.random.normal(50, 2, 25)]),
})
np.random.normal
scaler = preprocessing.RobustScaler()
robust_df = scaler.fit_transform(x)
robust_df = pd.DataFrame(robust_df, columns =['x1', 'x2'])
scaler = preprocessing.StandardScaler()
standard_df = scaler.fit_transform(x)
standard_df = pd.DataFrame(standard_df, columns =['x1', 'x2'])
scaler = preprocessing.MinMaxScaler()
minmax_df = scaler.fit_transform(x)
minmax_df = pd.DataFrame(minmax_df, columns =['x1', 'x2'])
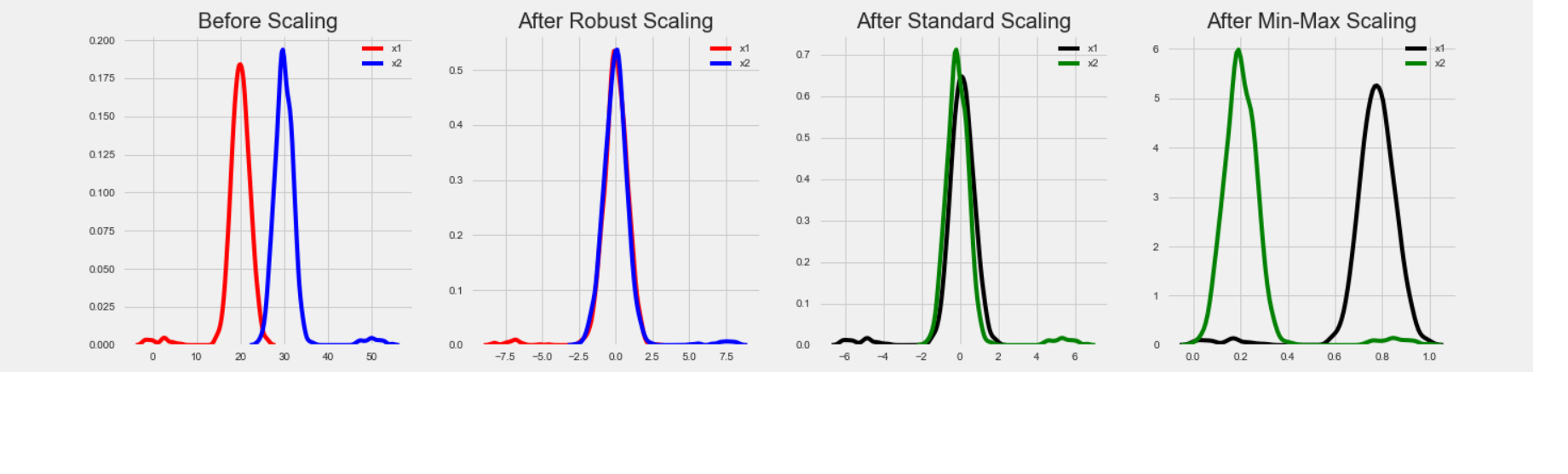
fig, (ax1, ax2, ax3, ax4) = plt.subplots(ncols = 4, figsize =(20, 5))
ax1.set_title('Before Scaling')
sns.kdeplot(x['x1'], ax = ax1, color ='r')
sns.kdeplot(x['x2'], ax = ax1, color ='b')
ax2.set_title('After Robust Scaling')
sns.kdeplot(robust_df['x1'], ax = ax2, color ='red')
sns.kdeplot(robust_df['x2'], ax = ax2, color ='blue')
ax3.set_title('After Standard Scaling')
sns.kdeplot(standard_df['x1'], ax = ax3, color ='black')
sns.kdeplot(standard_df['x2'], ax = ax3, color ='g')
ax4.set_title('After Min-Max Scaling')
sns.kdeplot(minmax_df['x1'], ax = ax4, color ='black')
sns.kdeplot(minmax_df['x2'], ax = ax4, color ='g')
plt.show()
Producción:
Parámetros de RobustScaler:
- with_centering: boolean: es True por defecto. Si el valor es True, los datos se centran antes de escalar. Cuando se aplica en arrays dispersas, la transformación generará una excepción porque centrarlas requiere construir una array densa, que generalmente es demasiado grande para caber en la memoria.
- with_scaling: boolean: También se establece en True de forma predeterminada. Escala los datos al rango intercuartílico.
- quantile_range: tuple(q_min, q_max), 0.0 < q_min < q_max < 100.0 : El rango de cuantiles se usa para calcular la escala. Por defecto, está configurado como se muestra a continuación. Predeterminado: (25,0, 75,0) = (1er cuantil, 3er cuantil) = IQR.
- copy: boolean Es un parámetro opcional. Por defecto, es Verdadero. Si la entrada ya es una array NumPy o una array CSC scipy.sparse y si axis = 1 , evite una copia configurando este parámetro en False y, en su lugar, realice una normalización de fila en el lugar.
Atributos:
- center_: array de flotantes: el valor medio de cada función en el conjunto de entrenamiento.
- scale_: array of floats: el rango intercuartílico escalado para la entidad en el conjunto de entrenamiento.
Publicación traducida automáticamente
Artículo escrito por ashwinsharmap y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA