1. Extracción, carga y transformación (ELT):
la extracción, carga y transformación (ELT) es la técnica de extraer datos sin procesar de la fuente y almacenarlos en el almacén de datos del servidor de destino y prepararlos para los usuarios finales.
ELT se compone de 3 operaciones diferentes realizadas en los datos:
- Extraer:
La extracción de datos es la técnica de identificar datos de una o más fuentes. Las fuentes pueden ser bases de datos, archivos, ERP, CRM o cualquier otra fuente útil de datos. - Carga:
la carga es el proceso de almacenar los datos sin procesar extraídos en un almacén de datos o lagos de datos. - Transformar:
la transformación de datos es el proceso en el que la fuente de datos sin procesar se transforma al formato de destino requerido para el análisis.
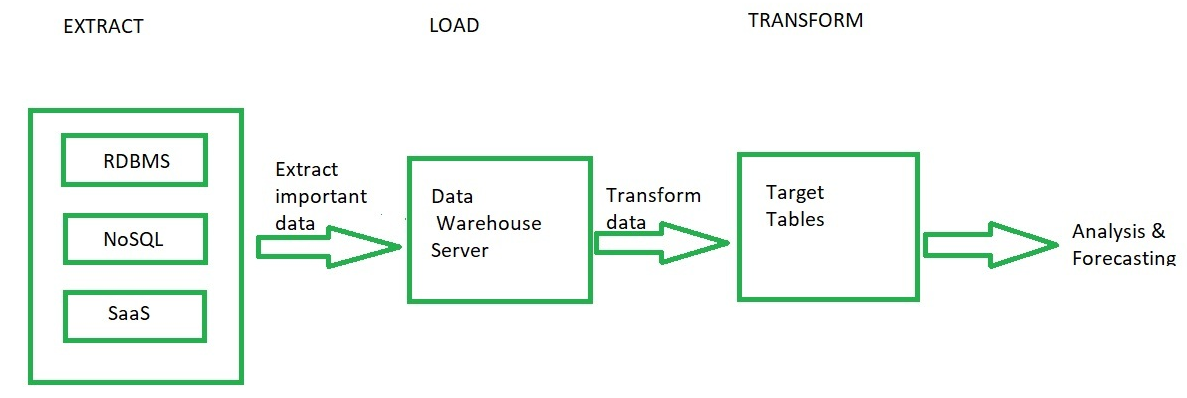
Los datos de las fuentes se extraen y almacenan en el almacén de datos. No se transforman todos los datos, pero solo se realiza la transformación requerida cuando es necesario. Los datos sin procesar se pueden recuperar del almacén en cualquier momento cuando sea necesario. Los datos transformados según sea necesario se envían luego para su análisis. Cuando usa ELT, mueve todo el conjunto de datos tal como existe en los sistemas de origen al destino. Esto significa que tiene los datos sin procesar a su disposición en el almacén de datos, en contraste con el enfoque ETL.
2. Extracción, transformación y carga (ETL):
ETL es la técnica tradicional de extracción de datos sin procesar, transformándolos para los usuarios según sea necesario y almacenándolos en almacenes de datos. ELT se desarrolló más tarde, teniendo a ETL como base. Las tres operaciones que ocurren en ETL y ELT son las mismas excepto que su orden de procesamiento varía ligeramente. Este cambio en la secuencia se hizo para superar algunos inconvenientes.
- Extraer:
Es el proceso de extraer datos sin procesar de todas las fuentes de datos disponibles, como bases de datos, archivos, ERP, CRM o cualquier otro. - Transformar:
los datos extraídos se transforman inmediatamente según lo requiera el usuario. - Cargar:
los datos transformados se cargan luego en el almacén de datos desde donde los usuarios pueden acceder a ellos.

Los datos recopilados de las fuentes se almacenan directamente en el área de ensayo. Las transformaciones requeridas se realizan en los datos en el área de ensayo. Una vez que se transforman los datos, los datos resultantes se almacenan en el almacén de datos. El principal inconveniente de la arquitectura ETL es que una vez que los datos transformados se almacenan en el almacén, no se pueden volver a modificar, mientras que en ELT, una copia de los datos sin procesar siempre está disponible en el almacén y solo se transforman los datos requeridos cuando es necesario.
Diferencia entre ELT y ETL:
| ELT | ETL |
|---|---|
| Las herramientas ELT no requieren hardware adicional | Las herramientas ETL requieren hardware específico con sus propios motores para realizar transformaciones |
| Principalmente base de datos Hadoop o NoSQL para almacenar datos. Rara vez se usa RDBMS | RDBMS se utiliza exclusivamente para almacenar datos |
| Como todos los componentes están en un solo sistema, la carga se realiza solo una vez | Como ETL usa el área de preparación, se requiere tiempo adicional para cargar los datos |
| El tiempo para transformar los datos es independiente del tamaño de los datos | El sistema tiene que esperar grandes cantidades de datos. A medida que aumenta el tamaño de los datos, también aumenta el tiempo de transformación |
| Es rentable y está disponible para todas las empresas que utilizan la solución SaaS. | No rentable para pequeñas y medianas empresas |
| Los datos transformados son utilizados por científicos de datos y analistas avanzados. | Los datos transformados son utilizados por los usuarios que leen el informe y los codificadores SQL. |
| Crea vistas ad hoc. Bajo costo de construcción y mantenimiento | Las vistas se crean en función de varios scripts. Eliminar la vista significa eliminar los datos |
| Lo mejor para datos no estructurados y no relacionales. Ideal para lagos de datos. Adecuado para grandes cantidades de datos | Lo mejor para datos relacionales y estructurados. Mejor para pequeñas y medianas cantidades de datos |
Publicación traducida automáticamente
Artículo escrito por hazel15300 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA