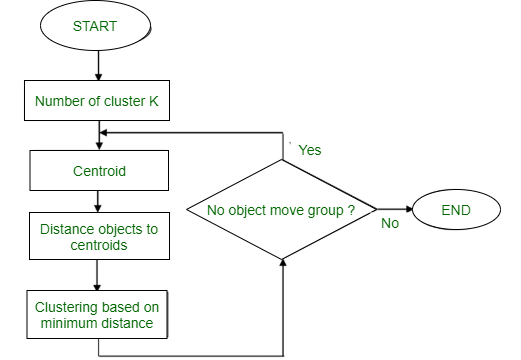
Método de partición:
este método de agrupación clasifica la información en varios grupos según las características y la similitud de los datos. Son los analistas de datos los que especifican la cantidad de clústeres que deben generarse para los métodos de agrupamiento.
En el método de partición, cuando la base de datos (D) contiene varios objetos (N), el método de partición construye particiones de datos especificadas por el usuario (K) en las que cada partición representa un clúster y una región particular. Hay muchos algoritmos que vienen bajo el método de partición, algunos de los más populares son K-Mean, PAM (K-Mediods), algoritmo CLARA (Clustering Large Applications), etc.
En este artículo, veremos en detalle el funcionamiento del algoritmo K Mean.
K-Mean (técnica basada en un centroide):
el algoritmo de K significa toma el parámetro de entrada K del usuario y divide el conjunto de datos que contiene N objetos en K grupos para que la similitud resultante entre los objetos de datos dentro del grupo (intracluster) sea alta pero el la similitud de los objetos de datos con los objetos de datos de fuera del clúster es baja (interclúster). La similitud del conglomerado se determina con respecto al valor medio del conglomerado.
Es un tipo de algoritmo de error cuadrático. Al principio, se eligen aleatoriamente k objetos del conjunto de datos en los que cada uno de los objetos representa una media de grupo (centro). Para el resto de los objetos de datos, se asignan al conglomerado más cercano en función de su distancia desde la media del conglomerado. Luego se calcula la nueva media de cada uno de los grupos con los objetos de datos agregados.
Algoritmo: K media:
Input: K: The number of clusters in which the dataset has to be divided D: A dataset containing N number of objects Output: A dataset of K clusters
Método:
- Asigne aleatoriamente K objetos del conjunto de datos (D) como centros de clúster (C)
- (Re) Asigne a cada objeto a qué objeto es más similar en función de los valores medios.
- Actualizar las medias de los clústeres, es decir, recalcular la media de cada clúster con los valores actualizados.
- Repita el Paso 4 hasta que no ocurra ningún cambio.
Diagrama de flujo:
Ejemplo: supongamos que queremos agrupar a los visitantes de un sitio web usando solo su edad de la siguiente manera:
16, 16, 17, 20, 20, 21, 21, 22, 23, 29, 36, 41, 42, 43, 44, 45, 61, 62, 66
Clúster inicial:
K=2 Centroid(C1) = 16 [16] Centroid(C2) = 22 [22]
Nota: Estos dos puntos se eligen al azar del conjunto de datos.
Iteración-1:
C1 = 16.33 [16, 16, 17] C2 = 37.25 [20, 20, 21, 21, 22, 23, 29, 36, 41, 42, 43, 44, 45, 61, 62, 66]
Iteración-2:
C1 = 19.55 [16, 16, 17, 20, 20, 21, 21, 22, 23] C2 = 46.90 [29, 36, 41, 42, 43, 44, 45, 61, 62, 66]
Iteración-3:
C1 = 20.50 [16, 16, 17, 20, 20, 21, 21, 22, 23, 29] C2 = 48.89 [36, 41, 42, 43, 44, 45, 61, 62, 66]
Iteración-4:
C1 = 20.50 [16, 16, 17, 20, 20, 21, 21, 22, 23, 29] C2 = 48.89 [36, 41, 42, 43, 44, 45, 61, 62, 66]
No hay cambios entre las iteraciones 3 y 4, así que nos detenemos. Por lo tanto, obtenemos los grupos (16-29) y (36-66) como 2 grupos que obtenemos usando el algoritmo de media K.