Si tenemos una gran cantidad de datos de texto, entonces uno puede categorizarlos en secciones separadas.
Código #1: Categorización
Python3
# Loading brown corpus from nltk.corpus import brown brown.categories()
Producción :
['adventure', 'belles_lettres', 'editorial', 'fiction', 'government', 'hobbies', 'humor', 'learned', 'lore', 'mystery', 'news', 'religion', 'reviews', 'romance', 'science_fiction']
¿Cómo categorizar un corpus?
La forma más fácil es tener un archivo para cada categoría. Los siguientes son dos extractos del corpus movie_reviews:
- movie_pos.txt
- movie_neg.txt
Usando estos dos archivos, tendremos dos categorías: pos y neg.
Código #2: Vamos a categorizar
Python3
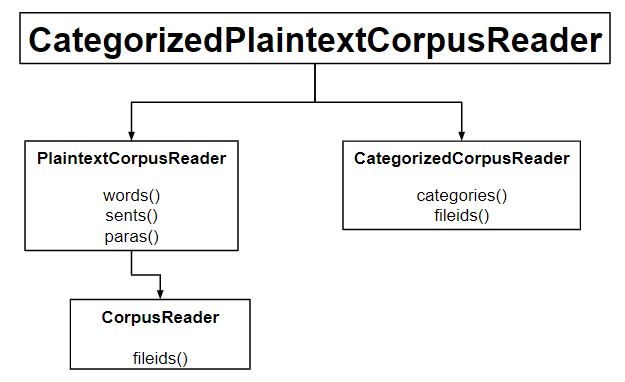
from nltk.corpus.reader import CategorizedPlaintextCorpusReader
reader = CategorizedPlaintextCorpusReader(
'.', r'movie_.*\.txt', cat_pattern = r'movie_(\w+)\.txt')
print ("Categorize : ", reader.categories())
print ("\nNegative field : ", reader.fileids(categories =['neg']))
print ("\nPositive field : ", reader.fileids(categories =['pos']))
Producción :
Categorize : ['neg', 'pos'] Negative field : ['movie_neg.txt'] Positive field : ['movie_pos.txt']
Código #3: En lugar de cat_pattern, usando en un cat_map
Python3
from nltk.corpus.reader import CategorizedPlaintextCorpusReader
reader = CategorizedPlaintextCorpusReader(
'.', r'movie_.*\.txt', cat_map ={'movie_pos.txt': ['pos'],
'movie_neg.txt': ['neg']})
print ("Categorize : ", reader.categories())
Producción :
Categorize : ['neg', 'pos']
Publicación traducida automáticamente
Artículo escrito por Mohit Gupta_OMG 🙂 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA