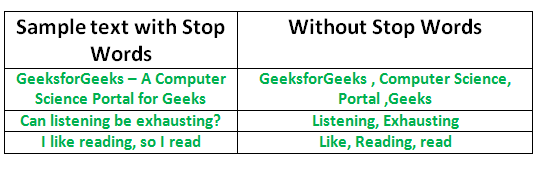
El proceso de convertir datos en algo que una computadora pueda entender se conoce como preprocesamiento. Una de las principales formas de preprocesamiento es filtrar datos inútiles. En el procesamiento del lenguaje natural, las palabras inútiles (datos) se denominan palabras vacías.

¿Qué son las palabras vacías?
Palabras vacías: una palabra vacía es una palabra de uso común (como «el», «un», «un», «en») que un motor de búsqueda ha sido programado para ignorar, tanto al indexar entradas para la búsqueda como al recuperarlas. como resultado de una consulta de búsqueda.
No queremos que estas palabras ocupen espacio en nuestra base de datos o que consuman un valioso tiempo de procesamiento. Para ello, podemos eliminarlas fácilmente, almacenando una lista de palabras que consideres palabras de parada. NLTK (Kit de herramientas de lenguaje natural) en python tiene una lista de palabras vacías almacenadas en 16 idiomas diferentes. Puede encontrarlos en el directorio nltk_data. home/pratima/nltk_data/corpora/stopwords es la dirección del directorio. (No olvide cambiar el nombre de su directorio de inicio)
Para verificar la lista de palabras vacías, puede escribir los siguientes comandos en el shell de python.
import nltk
from nltk.corpus import stopwords
print(stopwords.words('english'))
{‘nosotros mismos’, ‘ella’, ‘entre’, ‘usted mismo’, ‘pero’, ‘otra vez’, ‘allí’, ‘sobre’, ‘una vez’, ‘durante’, ‘fuera’, ‘muy’, ‘ tener’, ‘con’, ‘ellos’, ‘poseer’, ‘un’, ‘ser’, ‘algunos’, ‘para’, ‘hacer’, ‘su’, ‘tuyo’, ‘tal’, ‘en’ , ‘de’, ‘la mayoría’, ‘en sí’, ‘otro’, ‘fuera’, ‘es’, ‘s’, ‘soy’, ‘o’, ‘quién’, ‘como’, ‘de’, ‘ él’, ‘cada’, ‘el’, ‘ellos mismos’, ‘hasta’, ‘abajo’, ‘son’, ‘nosotros’, ‘estos’, ‘su’, ‘su’, ‘a través de’, ‘no’ , ‘ni’, ‘yo’, ‘eran’, ‘ella’, ‘más’, ‘él mismo’, ‘esto’, ‘abajo’, ‘debería’, ‘nuestro’, ‘su’, ‘mientras’, ‘ arriba’, ‘ambos’, ‘arriba’, ‘a’, ‘nuestro’, ‘tenía’, ‘ella’, ‘todas’, ‘no’, ‘cuándo’, ‘en’, ‘cualquiera’, ‘antes’ , ‘ellos’, ‘igual’, ‘y’, ‘sido’, ‘tener’, ‘en’, ‘voluntad’, ‘sobre’, ‘hace’, ‘ustedes mismos’, ‘entonces’, ‘eso’, ‘ porque’, ‘qué’, ‘sobre’, ‘por qué’, ‘entonces’, ‘puede’, ‘hizo’, ‘no’, ‘ahora’, ‘debajo’, ‘él’, ‘usted’, ‘ella misma’ , ‘tiene’, ‘solo’, ‘dónde’, ‘también’, ‘solo’, ‘yo mismo’, ‘cuál’, ‘esos’,’yo’, ‘después’, ‘pocos’, ‘quién’, ‘t’, ‘siendo’, ‘si’, ‘suyos’, ‘mi’, ‘contra’, ‘a’, ‘por’, ‘haciendo ‘, ‘eso’, ‘cómo’, ‘más allá’, ‘fue’, ‘aquí’, ‘que’}
Nota: Incluso puede modificar la lista agregando palabras de su elección en el .txt en inglés. archivo en el directorio de palabras vacías.
Eliminar palabras vacías con NLTK
El siguiente programa elimina las palabras vacías de un fragmento de texto:
Python3
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
example_sent = """This is a sample sentence,
showing off the stop words filtration."""
stop_words = set(stopwords.words('english'))
word_tokens = word_tokenize(example_sent)
filtered_sentence = [w for w in word_tokens if not w.lower() in stop_words]
filtered_sentence = []
for w in word_tokens:
if w not in stop_words:
filtered_sentence.append(w)
print(word_tokens)
print(filtered_sentence)
Producción:
['This', 'is', 'a', 'sample', 'sentence', ',', 'showing', 'off', 'the', 'stop', 'words', 'filtration', '.'] ['This', 'sample', 'sentence', ',', 'showing', 'stop', 'words', 'filtration', '.']
Realización de operaciones de Stopwords en un archivo
En el siguiente código, text.txt es el archivo de entrada original en el que se eliminarán las palabras vacías. filteredtext.txt es el archivo de salida. Se puede hacer usando el siguiente código:
Python3
import io
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
# word_tokenize accepts
# a string as an input, not a file.
stop_words = set(stopwords.words('english'))
file1 = open("text.txt")
# Use this to read file content as a stream:
line = file1.read()
words = line.split()
for r in words:
if not r in stop_words:
appendFile = open('filteredtext.txt','a')
appendFile.write(" "+r)
appendFile.close()
Así es como estamos haciendo que nuestro contenido procesado sea más eficiente al eliminar palabras que no contribuyen a ninguna operación futura.
Este artículo es una contribución de Pratima Upadhyay . Si te gusta GeeksforGeeks y te gustaría contribuir, también puedes escribir un artículo usando write.geeksforgeeks.org o enviar tu artículo por correo a review-team@geeksforgeeks.org. Vea su artículo que aparece en la página principal de GeeksforGeeks y ayude a otros Geeks.
Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA